
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
3.53B
| node_id
stringlengths 18
32
| number
int64 1
7.82k
| title
stringlengths 1
290
| user
dict | labels
listlengths 0
4
| state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
listlengths 0
4
| milestone
dict | comments
int64 0
70
| created_at
stringdate 2020-04-14 10:18:02
2025-10-20 06:38:19
| updated_at
stringdate 2020-04-27 16:04:17
2025-10-20 06:41:20
| closed_at
stringlengths 3
25
| author_association
stringclasses 4
values | type
float64 | active_lock_reason
float64 | draft
float64 0
1
⌀ | pull_request
dict | body
stringlengths 0
228k
⌀ | closed_by
dict | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
float64 | state_reason
stringclasses 4
values | sub_issues_summary
dict | issue_dependencies_summary
dict | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/245
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/245/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/245/comments
|
https://api.github.com/repos/huggingface/datasets/issues/245/events
|
https://github.com/huggingface/datasets/issues/245
| 631,985,108
|
MDU6SXNzdWU2MzE5ODUxMDg=
| 245
|
SST-2 test labels are all -1
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jxmorris12",
"id": 13238952,
"login": "jxmorris12",
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jxmorris12",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 10
|
2020-06-05 21:41:42+00:00
|
2021-12-08 00:47:32+00:00
|
2020-06-06 16:56:41+00:00
|
CONTRIBUTOR
| null | null | null | null |
I'm trying to test a model on the SST-2 task, but all the labels I see in the test set are -1.
```
>>> import nlp
>>> glue = nlp.load_dataset('glue', 'sst2')
>>> glue
{'train': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 67349), 'validation': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 872), 'test': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 1821)}
>>> list(l['label'] for l in glue['test'])
[-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jxmorris12",
"id": 13238952,
"login": "jxmorris12",
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jxmorris12",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/245/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/245/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/244
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/244/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/244/comments
|
https://api.github.com/repos/huggingface/datasets/issues/244/events
|
https://github.com/huggingface/datasets/pull/244
| 631,869,155
|
MDExOlB1bGxSZXF1ZXN0NDI4NjgxMTcx
| 244
|
Add Allociné Dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/37028092?v=4",
"events_url": "https://api.github.com/users/TheophileBlard/events{/privacy}",
"followers_url": "https://api.github.com/users/TheophileBlard/followers",
"following_url": "https://api.github.com/users/TheophileBlard/following{/other_user}",
"gists_url": "https://api.github.com/users/TheophileBlard/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/TheophileBlard",
"id": 37028092,
"login": "TheophileBlard",
"node_id": "MDQ6VXNlcjM3MDI4MDky",
"organizations_url": "https://api.github.com/users/TheophileBlard/orgs",
"received_events_url": "https://api.github.com/users/TheophileBlard/received_events",
"repos_url": "https://api.github.com/users/TheophileBlard/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/TheophileBlard/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TheophileBlard/subscriptions",
"type": "User",
"url": "https://api.github.com/users/TheophileBlard",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-06-05 19:19:26+00:00
|
2020-06-11 07:47:26+00:00
|
2020-06-11 07:47:26+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/244.diff",
"html_url": "https://github.com/huggingface/datasets/pull/244",
"merged_at": "2020-06-11T07:47:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/244.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/244"
}
|
This is a french binary sentiment classification dataset, which was used to train this model: https://huggingface.co/tblard/tf-allocine.
Basically, it's a french "IMDB" dataset, with more reviews.
More info on [this repo](https://github.com/TheophileBlard/french-sentiment-analysis-with-bert).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/244/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/244/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/243
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/243/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/243/comments
|
https://api.github.com/repos/huggingface/datasets/issues/243/events
|
https://github.com/huggingface/datasets/pull/243
| 631,735,848
|
MDExOlB1bGxSZXF1ZXN0NDI4NTY2MTEy
| 243
|
Specify utf-8 encoding for GLUE
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "https://api.github.com/users/patpizio/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patpizio",
"id": 15801338,
"login": "patpizio",
"node_id": "MDQ6VXNlcjE1ODAxMzM4",
"organizations_url": "https://api.github.com/users/patpizio/orgs",
"received_events_url": "https://api.github.com/users/patpizio/received_events",
"repos_url": "https://api.github.com/users/patpizio/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patpizio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patpizio/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patpizio",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-06-05 16:33:00+00:00
|
2020-06-17 21:16:06+00:00
|
2020-06-08 08:42:01+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/243.diff",
"html_url": "https://github.com/huggingface/datasets/pull/243",
"merged_at": "2020-06-08T08:42:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/243.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/243"
}
|
#242
This makes the GLUE-MNLI dataset readable on my machine, not sure if it's a Windows-only bug.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/243/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/243/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/242
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/242/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/242/comments
|
https://api.github.com/repos/huggingface/datasets/issues/242/events
|
https://github.com/huggingface/datasets/issues/242
| 631,733,683
|
MDU6SXNzdWU2MzE3MzM2ODM=
| 242
|
UnicodeDecodeError when downloading GLUE-MNLI
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "https://api.github.com/users/patpizio/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patpizio",
"id": 15801338,
"login": "patpizio",
"node_id": "MDQ6VXNlcjE1ODAxMzM4",
"organizations_url": "https://api.github.com/users/patpizio/orgs",
"received_events_url": "https://api.github.com/users/patpizio/received_events",
"repos_url": "https://api.github.com/users/patpizio/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patpizio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patpizio/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patpizio",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-06-05 16:30:01+00:00
|
2020-06-09 16:06:47+00:00
|
2020-06-08 08:45:03+00:00
|
CONTRIBUTOR
| null | null | null | null |
When I run
```python
dataset = nlp.load_dataset('glue', 'mnli')
```
I get an encoding error (could it be because I'm using Windows?) :
```python
# Lots of error log lines later...
~\Miniconda3\envs\nlp\lib\site-packages\tqdm\std.py in __iter__(self)
1128 try:
-> 1129 for obj in iterable:
1130 yield obj
~\Miniconda3\envs\nlp\lib\site-packages\nlp\datasets\glue\5256cc2368cf84497abef1f1a5f66648522d5854b225162148cb8fc78a5a91cc\glue.py in _generate_examples(self, data_file, split, mrpc_files)
529
--> 530 for n, row in enumerate(reader):
531 if is_cola_non_test:
~\Miniconda3\envs\nlp\lib\csv.py in __next__(self)
110 self.fieldnames
--> 111 row = next(self.reader)
112 self.line_num = self.reader.line_num
~\Miniconda3\envs\nlp\lib\encodings\cp1252.py in decode(self, input, final)
22 def decode(self, input, final=False):
---> 23 return codecs.charmap_decode(input,self.errors,decoding_table)[0]
24
UnicodeDecodeError: 'charmap' codec can't decode byte 0x9d in position 6744: character maps to <undefined>
```
Anyway this can be solved by specifying to decode in UTF when reading the csv file. I am proposing a PR if that's okay.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/242/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/242/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/241
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/241/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/241/comments
|
https://api.github.com/repos/huggingface/datasets/issues/241/events
|
https://github.com/huggingface/datasets/pull/241
| 631,703,079
|
MDExOlB1bGxSZXF1ZXN0NDI4NTQwMDM0
| 241
|
Fix empty cache dir
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-06-05 15:45:22+00:00
|
2020-06-08 08:35:33+00:00
|
2020-06-08 08:35:31+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/241.diff",
"html_url": "https://github.com/huggingface/datasets/pull/241",
"merged_at": "2020-06-08T08:35:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/241.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/241"
}
|
If the cache dir of a dataset is empty, the dataset fails to load and throws a FileNotFounfError. We could end up with empty cache dir because there was a line in the code that created the cache dir without using a temp dir. Using a temp dir is useful as it gets renamed to the real cache dir only if the full process is successful.
So I removed this bad line, and I also reordered things a bit to make sure that we always use a temp dir. I also added warning if we still end up with empty cache dirs in the future.
This should fix #239
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/241/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/241/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/240
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/240/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/240/comments
|
https://api.github.com/repos/huggingface/datasets/issues/240/events
|
https://github.com/huggingface/datasets/issues/240
| 631,434,677
|
MDU6SXNzdWU2MzE0MzQ2Nzc=
| 240
|
Deterministic dataset loading
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 4
|
2020-06-05 09:03:26+00:00
|
2020-06-08 09:18:14+00:00
|
2020-06-08 09:18:14+00:00
|
CONTRIBUTOR
| null | null | null | null |
When calling:
```python
import nlp
dataset = nlp.load_dataset("trivia_qa", split="validation[:1%]")
```
the resulting dataset is not deterministic over different google colabs.
After talking to @thomwolf, I suspect the reason to be the use of `glob.glob` in line:
https://github.com/huggingface/nlp/blob/2e0a8639a79b1abc848cff5c669094d40bba0f63/datasets/trivia_qa/trivia_qa.py#L180
which seems to return an ordering of files that depends on the filesystem:
https://stackoverflow.com/questions/6773584/how-is-pythons-glob-glob-ordered
I think we should go through all the dataset scripts and make sure to have deterministic behavior.
A simple solution for `glob.glob()` would be to just replace it with `sorted(glob.glob())` to have everything sorted by name.
What do you think @lhoestq?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/240/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/240/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/239
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/239/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/239/comments
|
https://api.github.com/repos/huggingface/datasets/issues/239/events
|
https://github.com/huggingface/datasets/issues/239
| 631,340,440
|
MDU6SXNzdWU2MzEzNDA0NDA=
| 239
|
[Creating new dataset] Not found dataset_info.json
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null | 5
|
2020-06-05 06:15:04+00:00
|
2020-06-07 13:01:04+00:00
|
2020-06-07 13:01:04+00:00
|
CONTRIBUTOR
| null | null | null | null |
Hi, I am trying to create Toronto Book Corpus. #131
I ran
`~/nlp % python nlp-cli test datasets/bookcorpus --save_infos --all_configs`
but this doesn't create `dataset_info.json` and try to use it
```
INFO:nlp.load:Checking datasets/bookcorpus/bookcorpus.py for additional imports.
INFO:filelock:Lock 139795325778640 acquired on datasets/bookcorpus/bookcorpus.py.lock
INFO:nlp.load:Found main folder for dataset datasets/bookcorpus/bookcorpus.py at /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus
INFO:nlp.load:Found specific version folder for dataset datasets/bookcorpus/bookcorpus.py at /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus/8e84759446cf68d0b0deb3417e60cc331f30a3bbe58843de18a0f48e87d1efd9
INFO:nlp.load:Found script file from datasets/bookcorpus/bookcorpus.py to /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus/8e84759446cf68d0b0deb3417e60cc331f30a3bbe58843de18a0f48e87d1efd9/bookcorpus.py
INFO:nlp.load:Couldn't find dataset infos file at datasets/bookcorpus/dataset_infos.json
INFO:nlp.load:Found metadata file for dataset datasets/bookcorpus/bookcorpus.py at /home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/datasets/bookcorpus/8e84759446cf68d0b0deb3417e60cc331f30a3bbe58843de18a0f48e87d1efd9/bookcorpus.json
INFO:filelock:Lock 139795325778640 released on datasets/bookcorpus/bookcorpus.py.lock
INFO:nlp.builder:Overwrite dataset info from restored data version.
INFO:nlp.info:Loading Dataset info from /home/yisiang/.cache/huggingface/datasets/book_corpus/plain_text/1.0.0
Traceback (most recent call last):
File "nlp-cli", line 37, in <module>
service.run()
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/commands/test.py", line 78, in run
builders.append(builder_cls(name=config.name, data_dir=self._data_dir))
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/builder.py", line 610, in __init__
super(GeneratorBasedBuilder, self).__init__(*args, **kwargs)
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/builder.py", line 152, in __init__
self.info = DatasetInfo.from_directory(self._cache_dir)
File "/home/yisiang/miniconda3/envs/ml/lib/python3.7/site-packages/nlp/info.py", line 157, in from_directory
with open(os.path.join(dataset_info_dir, DATASET_INFO_FILENAME), "r") as f:
FileNotFoundError: [Errno 2] No such file or directory: '/home/yisiang/.cache/huggingface/datasets/book_corpus/plain_text/1.0.0/dataset_info.json'
```
btw, `ls /home/yisiang/.cache/huggingface/datasets/book_corpus/plain_text/1.0.0/` show me nothing is in the directory.
I have also pushed the script to my fork [bookcorpus.py](https://github.com/richardyy1188/nlp/blob/bookcorpusdev/datasets/bookcorpus/bookcorpus.py).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/239/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/239/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/238
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/238/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/238/comments
|
https://api.github.com/repos/huggingface/datasets/issues/238/events
|
https://github.com/huggingface/datasets/issues/238
| 631,260,143
|
MDU6SXNzdWU2MzEyNjAxNDM=
| 238
|
[Metric] Bertscore : Warning : Empty candidate sentence; Setting recall to be 0.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
[
{
"color": "25b21e",
"default": false,
"description": "A bug in a metric script",
"id": 2067393914,
"name": "metric bug",
"node_id": "MDU6TGFiZWwyMDY3MzkzOTE0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/metric%20bug"
}
] |
closed
| false
| null |
[] | null | 1
|
2020-06-05 02:14:47+00:00
|
2020-06-29 17:10:19+00:00
|
2020-06-29 17:10:19+00:00
|
NONE
| null | null | null | null |
When running BERT-Score, I'm meeting this warning :
> Warning: Empty candidate sentence; Setting recall to be 0.
Code :
```
import nlp
metric = nlp.load_metric("bertscore")
scores = metric.compute(["swag", "swags"], ["swags", "totally something different"], lang="en", device=0)
```
---
**What am I doing wrong / How can I hide this warning ?**
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/238/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/238/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/237
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/237/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/237/comments
|
https://api.github.com/repos/huggingface/datasets/issues/237/events
|
https://github.com/huggingface/datasets/issues/237
| 631,199,940
|
MDU6SXNzdWU2MzExOTk5NDA=
| 237
|
Can't download MultiNLI
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "https://api.github.com/users/patpizio/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patpizio",
"id": 15801338,
"login": "patpizio",
"node_id": "MDQ6VXNlcjE1ODAxMzM4",
"organizations_url": "https://api.github.com/users/patpizio/orgs",
"received_events_url": "https://api.github.com/users/patpizio/received_events",
"repos_url": "https://api.github.com/users/patpizio/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patpizio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patpizio/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patpizio",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-06-04 23:05:21+00:00
|
2020-06-06 10:51:34+00:00
|
2020-06-06 10:51:34+00:00
|
CONTRIBUTOR
| null | null | null | null |
When I try to download MultiNLI with
```python
dataset = load_dataset('multi_nli')
```
I get this long error:
```python
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
<ipython-input-13-3b11f6be4cb9> in <module>
1 # Load a dataset and print the first examples in the training set
2 # nli_dataset = nlp.load_dataset('multi_nli')
----> 3 dataset = load_dataset('multi_nli')
4 # nli_dataset = nlp.load_dataset('multi_nli', split='validation_matched[:10%]')
5 # print(nli_dataset['train'][0])
~\Miniconda3\envs\nlp\lib\site-packages\nlp\load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
514
515 # Download and prepare data
--> 516 builder_instance.download_and_prepare(
517 download_config=download_config,
518 download_mode=download_mode,
~\Miniconda3\envs\nlp\lib\site-packages\nlp\builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
417 with utils.temporary_assignment(self, "_cache_dir", tmp_data_dir):
418 verify_infos = not save_infos and not ignore_verifications
--> 419 self._download_and_prepare(
420 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
421 )
~\Miniconda3\envs\nlp\lib\site-packages\nlp\builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
455 split_dict = SplitDict(dataset_name=self.name)
456 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 457 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
458 # Checksums verification
459 if verify_infos:
~\Miniconda3\envs\nlp\lib\site-packages\nlp\datasets\multi_nli\60774175381b9f3f1e6ae1028229e3cdb270d50379f45b9f2c01008f50f09e6b\multi_nli.py in _split_generators(self, dl_manager)
99 def _split_generators(self, dl_manager):
100
--> 101 downloaded_dir = dl_manager.download_and_extract(
102 "http://storage.googleapis.com/tfds-data/downloads/multi_nli/multinli_1.0.zip"
103 )
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\download_manager.py in download_and_extract(self, url_or_urls)
214 extracted_path(s): `str`, extracted paths of given URL(s).
215 """
--> 216 return self.extract(self.download(url_or_urls))
217
218 def get_recorded_sizes_checksums(self):
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\download_manager.py in extract(self, path_or_paths)
194 path_or_paths.
195 """
--> 196 return map_nested(
197 lambda path: cached_path(path, extract_compressed_file=True, force_extract=False), path_or_paths,
198 )
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\py_utils.py in map_nested(function, data_struct, dict_only, map_tuple)
168 return tuple(mapped)
169 # Singleton
--> 170 return function(data_struct)
171
172
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\download_manager.py in <lambda>(path)
195 """
196 return map_nested(
--> 197 lambda path: cached_path(path, extract_compressed_file=True, force_extract=False), path_or_paths,
198 )
199
~\Miniconda3\envs\nlp\lib\site-packages\nlp\utils\file_utils.py in cached_path(url_or_filename, download_config, **download_kwargs)
231 if is_zipfile(output_path):
232 with ZipFile(output_path, "r") as zip_file:
--> 233 zip_file.extractall(output_path_extracted)
234 zip_file.close()
235 elif tarfile.is_tarfile(output_path):
~\Miniconda3\envs\nlp\lib\zipfile.py in extractall(self, path, members, pwd)
1644
1645 for zipinfo in members:
-> 1646 self._extract_member(zipinfo, path, pwd)
1647
1648 @classmethod
~\Miniconda3\envs\nlp\lib\zipfile.py in _extract_member(self, member, targetpath, pwd)
1698
1699 with self.open(member, pwd=pwd) as source, \
-> 1700 open(targetpath, "wb") as target:
1701 shutil.copyfileobj(source, target)
1702
OSError: [Errno 22] Invalid argument: 'C:\\Users\\Python\\.cache\\huggingface\\datasets\\3e12413b8ec69f22dfcfd54a79d1ba9e7aac2e18e334bbb6b81cca64fd16bffc\\multinli_1.0\\Icon\r'
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "https://api.github.com/users/patpizio/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patpizio",
"id": 15801338,
"login": "patpizio",
"node_id": "MDQ6VXNlcjE1ODAxMzM4",
"organizations_url": "https://api.github.com/users/patpizio/orgs",
"received_events_url": "https://api.github.com/users/patpizio/received_events",
"repos_url": "https://api.github.com/users/patpizio/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patpizio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patpizio/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patpizio",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/237/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/237/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/236
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/236/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/236/comments
|
https://api.github.com/repos/huggingface/datasets/issues/236/events
|
https://github.com/huggingface/datasets/pull/236
| 631,099,875
|
MDExOlB1bGxSZXF1ZXN0NDI4MDUwNzI4
| 236
|
CompGuessWhat?! dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1479733?v=4",
"events_url": "https://api.github.com/users/aleSuglia/events{/privacy}",
"followers_url": "https://api.github.com/users/aleSuglia/followers",
"following_url": "https://api.github.com/users/aleSuglia/following{/other_user}",
"gists_url": "https://api.github.com/users/aleSuglia/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/aleSuglia",
"id": 1479733,
"login": "aleSuglia",
"node_id": "MDQ6VXNlcjE0Nzk3MzM=",
"organizations_url": "https://api.github.com/users/aleSuglia/orgs",
"received_events_url": "https://api.github.com/users/aleSuglia/received_events",
"repos_url": "https://api.github.com/users/aleSuglia/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/aleSuglia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aleSuglia/subscriptions",
"type": "User",
"url": "https://api.github.com/users/aleSuglia",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 9
|
2020-06-04 19:45:50+00:00
|
2020-06-11 09:43:42+00:00
|
2020-06-11 07:45:21+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/236.diff",
"html_url": "https://github.com/huggingface/datasets/pull/236",
"merged_at": "2020-06-11T07:45:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/236.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/236"
}
|
Hello,
Thanks for the amazing library that you put together. I'm Alessandro Suglia, the first author of CompGuessWhat?!, a recently released dataset for grounded language learning accepted to ACL 2020 ([https://compguesswhat.github.io](https://compguesswhat.github.io)).
This pull-request adds the CompGuessWhat?! splits that have been extracted from the original dataset. This is only part of our evaluation framework because there is also an additional split of the dataset that has a completely different set of games. I didn't integrate it yet because I didn't know what would be the best practice in this case. Let me clarify the scenario.
In our paper, we have a main dataset (let's call it `compguesswhat-gameplay`) and a zero-shot dataset (let's call it `compguesswhat-zs-gameplay`). In the current code of the pull-request, I have only integrated `compguesswhat-gameplay`. I was thinking that it would be nice to have the `compguesswhat-zs-gameplay` in the same dataset class by simply specifying some particular option to the `nlp.load_dataset()` factory. For instance:
```python
cgw = nlp.load_dataset("compguesswhat")
cgw_zs = nlp.load_dataset("compguesswhat", zero_shot=True)
```
The other option would be to have a separate dataset class. Any preferences?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/236/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/236/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/235
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/235/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/235/comments
|
https://api.github.com/repos/huggingface/datasets/issues/235/events
|
https://github.com/huggingface/datasets/pull/235
| 630,952,297
|
MDExOlB1bGxSZXF1ZXN0NDI3OTM1MjQ0
| 235
|
Add experimental datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 6
|
2020-06-04 15:54:56+00:00
|
2020-06-12 15:38:55+00:00
|
2020-06-12 15:38:55+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/235.diff",
"html_url": "https://github.com/huggingface/datasets/pull/235",
"merged_at": "2020-06-12T15:38:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/235.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/235"
}
|
## Adding an *experimental datasets* folder
After using the 🤗nlp library for some time, I find that while it makes it super easy to create new memory-mapped datasets with lots of cool utilities, a lot of what I want to do doesn't work well with the current `MockDownloader` based testing paradigm, making it hard to share my work with the community.
My suggestion would be to add a **datasets\_experimental** folder so we can start making these new datasets public without having to completely re-think testing for every single one. We would allow contributors to submit dataset PRs in this folder, but require an explanation for why the current testing suite doesn't work for them. We can then aggregate the feedback and periodically see what's missing from the current tests.
I have added a **datasets\_experimental** folder to the repository and S3 bucket with two initial datasets: ELI5 (explainlikeimfive) and a Wikipedia Snippets dataset to support indexing (wiki\_snippets)
### ELI5
#### Dataset description
This allows people to download the [ELI5: Long Form Question Answering](https://arxiv.org/abs/1907.09190) dataset, along with two variants based on the r/askscience and r/AskHistorians. Full Reddit dumps for each month are downloaded from [pushshift](https://files.pushshift.io/reddit/), filtered for submissions and comments from the desired subreddits, then deleted one at a time to save space. The resulting dataset is split into a training, validation, and test dataset for r/explainlikeimfive, r/askscience, and r/AskHistorians respectively, where each item is a question along with all of its high scoring answers.
#### Issues with the current testing
1. the list of files to be downloaded is not pre-defined, but rather determined by parsing an index web page at run time. This is necessary as the name and compression type of the dump files changes from month to month as the pushshift website is maintained. Currently, the dummy folder requires the user to know which files will be downloaded.
2. to save time, the script works on the compressed files using the corresponding python packages rather than first running `download\_and\_extract` then filtering the extracted files.
### Wikipedia Snippets
#### Dataset description
This script creates a *snippets* version of a source Wikipedia dataset: each article is split into passages of fixed length which can then be indexed using ElasticSearch or a dense indexer. The script currently handles all **wikipedia** and **wiki40b** source datasets, and allows the user to choose the passage length and how much overlap they want across passages. In addition to the passage text, each snippet also has the article title, list of titles of sections covered by the text, and information to map the passage back to the initial dataset at the paragraph and character level.
#### Issues with the current testing
1. The DatasetBuilder needs to call `nlp.load_dataset()`. Currently, testing is not recursive (the test doesn't know where to find the dummy data for the source dataset)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/235/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/235/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/234
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/234/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/234/comments
|
https://api.github.com/repos/huggingface/datasets/issues/234/events
|
https://github.com/huggingface/datasets/issues/234
| 630,534,427
|
MDU6SXNzdWU2MzA1MzQ0Mjc=
| 234
|
Huggingface NLP, Uploading custom dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42269506?v=4",
"events_url": "https://api.github.com/users/Nouman97/events{/privacy}",
"followers_url": "https://api.github.com/users/Nouman97/followers",
"following_url": "https://api.github.com/users/Nouman97/following{/other_user}",
"gists_url": "https://api.github.com/users/Nouman97/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Nouman97",
"id": 42269506,
"login": "Nouman97",
"node_id": "MDQ6VXNlcjQyMjY5NTA2",
"organizations_url": "https://api.github.com/users/Nouman97/orgs",
"received_events_url": "https://api.github.com/users/Nouman97/received_events",
"repos_url": "https://api.github.com/users/Nouman97/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Nouman97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nouman97/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Nouman97",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 4
|
2020-06-04 05:59:06+00:00
|
2020-07-06 09:33:26+00:00
|
2020-07-06 09:33:26+00:00
|
NONE
| null | null | null | null |
Hello,
Does anyone know how we can call our custom dataset using the nlp.load command? Let's say that I have a dataset based on the same format as that of squad-v1.1, how am I supposed to load it using huggingface nlp.
Thank you!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42269506?v=4",
"events_url": "https://api.github.com/users/Nouman97/events{/privacy}",
"followers_url": "https://api.github.com/users/Nouman97/followers",
"following_url": "https://api.github.com/users/Nouman97/following{/other_user}",
"gists_url": "https://api.github.com/users/Nouman97/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Nouman97",
"id": 42269506,
"login": "Nouman97",
"node_id": "MDQ6VXNlcjQyMjY5NTA2",
"organizations_url": "https://api.github.com/users/Nouman97/orgs",
"received_events_url": "https://api.github.com/users/Nouman97/received_events",
"repos_url": "https://api.github.com/users/Nouman97/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Nouman97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nouman97/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Nouman97",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/234/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/234/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/233
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/233/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/233/comments
|
https://api.github.com/repos/huggingface/datasets/issues/233/events
|
https://github.com/huggingface/datasets/issues/233
| 630,432,132
|
MDU6SXNzdWU2MzA0MzIxMzI=
| 233
|
Fail to download c4 english corpus
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16605764?v=4",
"events_url": "https://api.github.com/users/donggyukimc/events{/privacy}",
"followers_url": "https://api.github.com/users/donggyukimc/followers",
"following_url": "https://api.github.com/users/donggyukimc/following{/other_user}",
"gists_url": "https://api.github.com/users/donggyukimc/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/donggyukimc",
"id": 16605764,
"login": "donggyukimc",
"node_id": "MDQ6VXNlcjE2NjA1NzY0",
"organizations_url": "https://api.github.com/users/donggyukimc/orgs",
"received_events_url": "https://api.github.com/users/donggyukimc/received_events",
"repos_url": "https://api.github.com/users/donggyukimc/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/donggyukimc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/donggyukimc/subscriptions",
"type": "User",
"url": "https://api.github.com/users/donggyukimc",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 5
|
2020-06-04 01:06:38+00:00
|
2021-01-08 07:17:32+00:00
|
2020-06-08 09:16:59+00:00
|
NONE
| null | null | null | null |
i run following code to download c4 English corpus.
```
dataset = nlp.load_dataset('c4', 'en', beam_runner='DirectRunner'
, data_dir='/mypath')
```
and i met failure as follows
```
Downloading and preparing dataset c4/en (download: Unknown size, generated: Unknown size, total: Unknown size) to /home/adam/.cache/huggingface/datasets/c4/en/2.3.0...
Traceback (most recent call last):
File "download_corpus.py", line 38, in <module>
, data_dir='/home/adam/data/corpus/en/c4')
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/load.py", line 520, in load_dataset
save_infos=save_infos,
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/builder.py", line 420, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/builder.py", line 816, in _download_and_prepare
dl_manager, verify_infos=False, pipeline=pipeline,
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/builder.py", line 457, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/home/adam/anaconda3/envs/adam/lib/python3.7/site-packages/nlp/datasets/c4/f545de9f63300d8d02a6795e2eb34e140c47e62a803f572ac5599e170ee66ecc/c4.py", line 175, in _split_generators
dl_manager.download_checksums(_CHECKSUMS_URL)
AttributeError: 'DownloadManager' object has no attribute 'download_checksums
```
can i get any advice?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/233/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/233/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/232
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/232/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/232/comments
|
https://api.github.com/repos/huggingface/datasets/issues/232/events
|
https://github.com/huggingface/datasets/pull/232
| 630,029,568
|
MDExOlB1bGxSZXF1ZXN0NDI3MjI5NDcy
| 232
|
Nlp cli fix endpoints
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-06-03 14:10:39+00:00
|
2020-06-08 09:02:58+00:00
|
2020-06-08 09:02:57+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/232.diff",
"html_url": "https://github.com/huggingface/datasets/pull/232",
"merged_at": "2020-06-08T09:02:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/232.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/232"
}
|
With this PR users will be able to upload their own datasets and metrics.
As mentioned in #181, I had to use the new endpoints and revert the use of dataclasses (just in case we have changes in the API in the future).
We now distinguish commands for datasets and commands for metrics:
```bash
nlp-cli upload_dataset <path/to/dataset>
nlp-cli upload_metric <path/to/metric>
nlp-cli s3_datasets {rm, ls}
nlp-cli s3_metrics {rm, ls}
```
Does it sound good to you @julien-c @thomwolf ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/232/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/232/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/231
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/231/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/231/comments
|
https://api.github.com/repos/huggingface/datasets/issues/231/events
|
https://github.com/huggingface/datasets/pull/231
| 629,988,694
|
MDExOlB1bGxSZXF1ZXN0NDI3MTk3MTcz
| 231
|
Add .download to MockDownloadManager
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-06-03 13:20:00+00:00
|
2020-06-03 14:25:56+00:00
|
2020-06-03 14:25:55+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/231.diff",
"html_url": "https://github.com/huggingface/datasets/pull/231",
"merged_at": "2020-06-03T14:25:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/231.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/231"
}
|
One method from the DownloadManager was missing and some users couldn't run the tests because of that.
@yjernite
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/231/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/231/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/230
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/230/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/230/comments
|
https://api.github.com/repos/huggingface/datasets/issues/230/events
|
https://github.com/huggingface/datasets/pull/230
| 629,983,684
|
MDExOlB1bGxSZXF1ZXN0NDI3MTkzMTQ0
| 230
|
Don't force to install apache beam for wikipedia dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-06-03 13:13:07+00:00
|
2020-06-03 14:34:09+00:00
|
2020-06-03 14:34:07+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/230.diff",
"html_url": "https://github.com/huggingface/datasets/pull/230",
"merged_at": "2020-06-03T14:34:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/230.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/230"
}
|
As pointed out in #227, we shouldn't force users to install apache beam if the processed dataset can be downloaded. I moved the imports of some datasets to avoid this problem
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/230/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/230/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/229
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/229/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/229/comments
|
https://api.github.com/repos/huggingface/datasets/issues/229/events
|
https://github.com/huggingface/datasets/pull/229
| 629,956,490
|
MDExOlB1bGxSZXF1ZXN0NDI3MTcxMzc5
| 229
|
Rename dataset_infos.json to dataset_info.json
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11817160?v=4",
"events_url": "https://api.github.com/users/aswin-giridhar/events{/privacy}",
"followers_url": "https://api.github.com/users/aswin-giridhar/followers",
"following_url": "https://api.github.com/users/aswin-giridhar/following{/other_user}",
"gists_url": "https://api.github.com/users/aswin-giridhar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/aswin-giridhar",
"id": 11817160,
"login": "aswin-giridhar",
"node_id": "MDQ6VXNlcjExODE3MTYw",
"organizations_url": "https://api.github.com/users/aswin-giridhar/orgs",
"received_events_url": "https://api.github.com/users/aswin-giridhar/received_events",
"repos_url": "https://api.github.com/users/aswin-giridhar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/aswin-giridhar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aswin-giridhar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/aswin-giridhar",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-06-03 12:31:44+00:00
|
2020-06-03 12:52:54+00:00
|
2020-06-03 12:48:33+00:00
|
NONE
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/229.diff",
"html_url": "https://github.com/huggingface/datasets/pull/229",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/229.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/229"
}
|
As the file required for the viewing in the live nlp viewer is named as dataset_info.json
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/229/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/229/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/228
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/228/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/228/comments
|
https://api.github.com/repos/huggingface/datasets/issues/228/events
|
https://github.com/huggingface/datasets/issues/228
| 629,952,402
|
MDU6SXNzdWU2Mjk5NTI0MDI=
| 228
|
Not able to access the XNLI dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11817160?v=4",
"events_url": "https://api.github.com/users/aswin-giridhar/events{/privacy}",
"followers_url": "https://api.github.com/users/aswin-giridhar/followers",
"following_url": "https://api.github.com/users/aswin-giridhar/following{/other_user}",
"gists_url": "https://api.github.com/users/aswin-giridhar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/aswin-giridhar",
"id": 11817160,
"login": "aswin-giridhar",
"node_id": "MDQ6VXNlcjExODE3MTYw",
"organizations_url": "https://api.github.com/users/aswin-giridhar/orgs",
"received_events_url": "https://api.github.com/users/aswin-giridhar/received_events",
"repos_url": "https://api.github.com/users/aswin-giridhar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/aswin-giridhar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aswin-giridhar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/aswin-giridhar",
"user_view_type": "public"
}
|
[
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35882?v=4",
"events_url": "https://api.github.com/users/srush/events{/privacy}",
"followers_url": "https://api.github.com/users/srush/followers",
"following_url": "https://api.github.com/users/srush/following{/other_user}",
"gists_url": "https://api.github.com/users/srush/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/srush",
"id": 35882,
"login": "srush",
"node_id": "MDQ6VXNlcjM1ODgy",
"organizations_url": "https://api.github.com/users/srush/orgs",
"received_events_url": "https://api.github.com/users/srush/received_events",
"repos_url": "https://api.github.com/users/srush/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/srush/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/srush/subscriptions",
"type": "User",
"url": "https://api.github.com/users/srush",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/35882?v=4",
"events_url": "https://api.github.com/users/srush/events{/privacy}",
"followers_url": "https://api.github.com/users/srush/followers",
"following_url": "https://api.github.com/users/srush/following{/other_user}",
"gists_url": "https://api.github.com/users/srush/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/srush",
"id": 35882,
"login": "srush",
"node_id": "MDQ6VXNlcjM1ODgy",
"organizations_url": "https://api.github.com/users/srush/orgs",
"received_events_url": "https://api.github.com/users/srush/received_events",
"repos_url": "https://api.github.com/users/srush/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/srush/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/srush/subscriptions",
"type": "User",
"url": "https://api.github.com/users/srush",
"user_view_type": "public"
}
] | null | 4
|
2020-06-03 12:25:14+00:00
|
2020-07-17 17:44:22+00:00
|
2020-07-17 17:44:22+00:00
|
NONE
| null | null | null | null |
When I try to access the XNLI dataset, I get the following error. The option of plain_text get selected automatically and then I get the following error.
```
FileNotFoundError: [Errno 2] No such file or directory: '/home/sasha/.cache/huggingface/datasets/xnli/plain_text/1.0.0/dataset_info.json'
Traceback:
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/ScriptRunner.py", line 322, in _run_script
exec(code, module.__dict__)
File "/home/sasha/nlp_viewer/run.py", line 86, in <module>
dts, fail = get(str(option.id), str(conf_option.name) if conf_option else None)
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/caching.py", line 591, in wrapped_func
return get_or_create_cached_value()
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/caching.py", line 575, in get_or_create_cached_value
return_value = func(*args, **kwargs)
File "/home/sasha/nlp_viewer/run.py", line 72, in get
builder_instance = builder_cls(name=conf)
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/builder.py", line 610, in __init__
super(GeneratorBasedBuilder, self).__init__(*args, **kwargs)
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/builder.py", line 152, in __init__
self.info = DatasetInfo.from_directory(self._cache_dir)
File "/home/sasha/.local/lib/python3.7/site-packages/nlp/info.py", line 157, in from_directory
with open(os.path.join(dataset_info_dir, DATASET_INFO_FILENAME), "r") as f:
```
Is it possible to see if the dataset_info.json is correctly placed?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/228/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/228/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/227
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/227/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/227/comments
|
https://api.github.com/repos/huggingface/datasets/issues/227/events
|
https://github.com/huggingface/datasets/issues/227
| 629,845,704
|
MDU6SXNzdWU2Mjk4NDU3MDQ=
| 227
|
Should we still have to force to install apache_beam to download wikipedia ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null | 3
|
2020-06-03 09:33:20+00:00
|
2020-06-03 15:25:41+00:00
|
2020-06-03 15:25:41+00:00
|
CONTRIBUTOR
| null | null | null | null |
Hi, first thanks to @lhoestq 's revolutionary work, I successfully downloaded processed wikipedia according to the doc. 😍😍😍
But at the first try, it tell me to install `apache_beam` and `mwparserfromhell`, which I thought wouldn't be used according to #204 , it was kind of confusing me at that time.
Maybe we should not force users to install these ? Or we just add them to`nlp`'s dependency ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/227/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/227/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/226
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/226/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/226/comments
|
https://api.github.com/repos/huggingface/datasets/issues/226/events
|
https://github.com/huggingface/datasets/pull/226
| 628,344,520
|
MDExOlB1bGxSZXF1ZXN0NDI1OTA0MjEz
| 226
|
add BlendedSkillTalk dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-06-01 10:54:45+00:00
|
2020-06-03 14:37:23+00:00
|
2020-06-03 14:37:22+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/226.diff",
"html_url": "https://github.com/huggingface/datasets/pull/226",
"merged_at": "2020-06-03T14:37:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/226.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/226"
}
|
This PR add the BlendedSkillTalk dataset, which is used to fine tune the blenderbot.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/226/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/226/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/225
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/225/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/225/comments
|
https://api.github.com/repos/huggingface/datasets/issues/225/events
|
https://github.com/huggingface/datasets/issues/225
| 628,083,366
|
MDU6SXNzdWU2MjgwODMzNjY=
| 225
|
[ROUGE] Different scores with `files2rouge`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
[
{
"color": "d722e8",
"default": false,
"description": "Discussions on the metrics",
"id": 2067400959,
"name": "Metric discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwOTU5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/Metric%20discussion"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
] | null | 3
|
2020-06-01 00:50:36+00:00
|
2020-06-03 15:27:18+00:00
|
2020-06-03 15:27:18+00:00
|
NONE
| null | null | null | null |
It seems that the ROUGE score of `nlp` is lower than the one of `files2rouge`.
Here is a self-contained notebook to reproduce both scores : https://colab.research.google.com/drive/14EyAXValB6UzKY9x4rs_T3pyL7alpw_F?usp=sharing
---
`nlp` : (Only mid F-scores)
>rouge1 0.33508031962733364
rouge2 0.14574333776191592
rougeL 0.2321187823256159
`files2rouge` :
>Running ROUGE...
===========================
1 ROUGE-1 Average_R: 0.48873 (95%-conf.int. 0.41192 - 0.56339)
1 ROUGE-1 Average_P: 0.29010 (95%-conf.int. 0.23605 - 0.34445)
1 ROUGE-1 Average_F: 0.34761 (95%-conf.int. 0.29479 - 0.39871)
===========================
1 ROUGE-2 Average_R: 0.20280 (95%-conf.int. 0.14969 - 0.26244)
1 ROUGE-2 Average_P: 0.12772 (95%-conf.int. 0.08603 - 0.17752)
1 ROUGE-2 Average_F: 0.14798 (95%-conf.int. 0.10517 - 0.19240)
===========================
1 ROUGE-L Average_R: 0.32960 (95%-conf.int. 0.26501 - 0.39676)
1 ROUGE-L Average_P: 0.19880 (95%-conf.int. 0.15257 - 0.25136)
1 ROUGE-L Average_F: 0.23619 (95%-conf.int. 0.19073 - 0.28663)
---
When using longer predictions/gold, the difference is bigger.
**How can I reproduce same score as `files2rouge` ?**
@lhoestq
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/225/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/225/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/224
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/224/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/224/comments
|
https://api.github.com/repos/huggingface/datasets/issues/224/events
|
https://github.com/huggingface/datasets/issues/224
| 627,791,693
|
MDU6SXNzdWU2Mjc3OTE2OTM=
| 224
|
[Feature Request/Help] BLEURT model -> PyTorch
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6889910?v=4",
"events_url": "https://api.github.com/users/adamwlev/events{/privacy}",
"followers_url": "https://api.github.com/users/adamwlev/followers",
"following_url": "https://api.github.com/users/adamwlev/following{/other_user}",
"gists_url": "https://api.github.com/users/adamwlev/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/adamwlev",
"id": 6889910,
"login": "adamwlev",
"node_id": "MDQ6VXNlcjY4ODk5MTA=",
"organizations_url": "https://api.github.com/users/adamwlev/orgs",
"received_events_url": "https://api.github.com/users/adamwlev/received_events",
"repos_url": "https://api.github.com/users/adamwlev/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/adamwlev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adamwlev/subscriptions",
"type": "User",
"url": "https://api.github.com/users/adamwlev",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
] | null | 6
|
2020-05-30 18:30:40+00:00
|
2023-08-26 17:38:48+00:00
|
2021-01-04 09:53:32+00:00
|
NONE
| null | null | null | null |
Hi, I am interested in porting google research's new BLEURT learned metric to PyTorch (because I wish to do something experimental with language generation and backpropping through BLEURT). I noticed that you guys don't have it yet so I am partly just asking if you plan to add it (@thomwolf said you want to do so on Twitter).
I had a go of just like manually using the checkpoint that they publish which includes the weights. It seems like the architecture is exactly aligned with the out-of-the-box BertModel in transformers just with a single linear layer on top of the CLS embedding. I loaded all the weights to the PyTorch model but I am not able to get the same numbers as the BLEURT package's python api. Here is my colab notebook where I tried https://colab.research.google.com/drive/1Bfced531EvQP_CpFvxwxNl25Pj6ptylY?usp=sharing . If you have any pointers on what might be going wrong that would be much appreciated!
Thank you muchly!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/224/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/224/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/223
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/223/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/223/comments
|
https://api.github.com/repos/huggingface/datasets/issues/223/events
|
https://github.com/huggingface/datasets/issues/223
| 627,683,386
|
MDU6SXNzdWU2Mjc2ODMzODY=
| 223
|
[Feature request] Add FLUE dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/58078086?v=4",
"events_url": "https://api.github.com/users/lbourdois/events{/privacy}",
"followers_url": "https://api.github.com/users/lbourdois/followers",
"following_url": "https://api.github.com/users/lbourdois/following{/other_user}",
"gists_url": "https://api.github.com/users/lbourdois/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lbourdois",
"id": 58078086,
"login": "lbourdois",
"node_id": "MDQ6VXNlcjU4MDc4MDg2",
"organizations_url": "https://api.github.com/users/lbourdois/orgs",
"received_events_url": "https://api.github.com/users/lbourdois/received_events",
"repos_url": "https://api.github.com/users/lbourdois/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lbourdois/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lbourdois/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lbourdois",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
closed
| false
| null |
[] | null | 3
|
2020-05-30 08:52:15+00:00
|
2020-12-03 13:39:33+00:00
|
2020-12-03 13:39:33+00:00
|
NONE
| null | null | null | null |
Hi,
I think it would be interesting to add the FLUE dataset for francophones or anyone wishing to work on French.
In other requests, I read that you are already working on some datasets, and I was wondering if FLUE was planned.
If it is not the case, I can provide each of the cleaned FLUE datasets (in the form of a directly exploitable dataset rather than in the original xml formats which require additional processing, with the French part for cases where the dataset is based on a multilingual dataframe, etc.).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/223/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/223/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/222
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/222/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/222/comments
|
https://api.github.com/repos/huggingface/datasets/issues/222/events
|
https://github.com/huggingface/datasets/issues/222
| 627,586,690
|
MDU6SXNzdWU2Mjc1ODY2OTA=
| 222
|
Colab Notebook breaks when downloading the squad dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/338917?v=4",
"events_url": "https://api.github.com/users/carlos-aguayo/events{/privacy}",
"followers_url": "https://api.github.com/users/carlos-aguayo/followers",
"following_url": "https://api.github.com/users/carlos-aguayo/following{/other_user}",
"gists_url": "https://api.github.com/users/carlos-aguayo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/carlos-aguayo",
"id": 338917,
"login": "carlos-aguayo",
"node_id": "MDQ6VXNlcjMzODkxNw==",
"organizations_url": "https://api.github.com/users/carlos-aguayo/orgs",
"received_events_url": "https://api.github.com/users/carlos-aguayo/received_events",
"repos_url": "https://api.github.com/users/carlos-aguayo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/carlos-aguayo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/carlos-aguayo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/carlos-aguayo",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 6
|
2020-05-29 22:55:59+00:00
|
2020-06-04 00:21:05+00:00
|
2020-06-04 00:21:05+00:00
|
NONE
| null | null | null | null |
When I run the notebook in Colab
https://colab.research.google.com/github/huggingface/nlp/blob/master/notebooks/Overview.ipynb
breaks when running this cell:
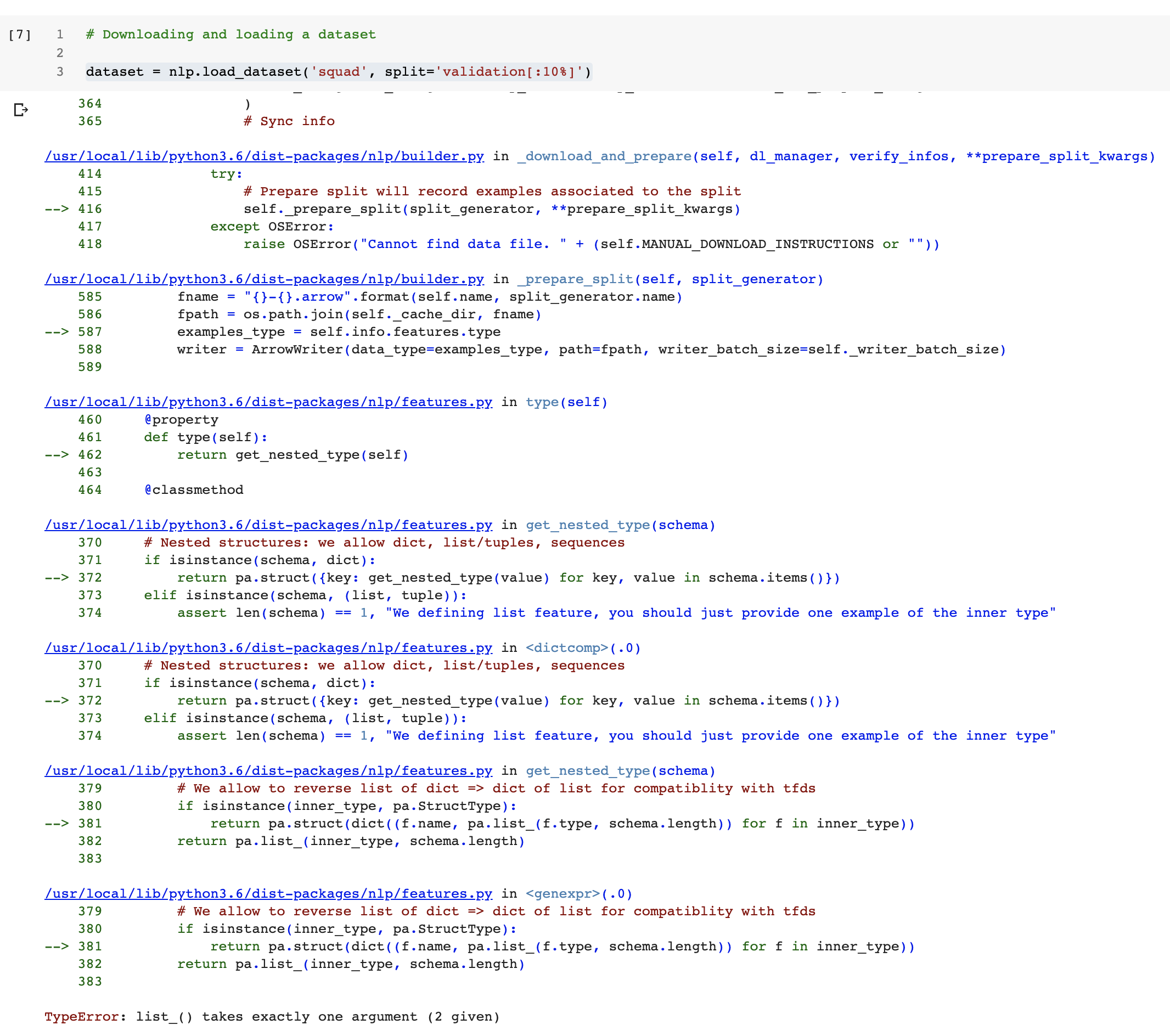
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/338917?v=4",
"events_url": "https://api.github.com/users/carlos-aguayo/events{/privacy}",
"followers_url": "https://api.github.com/users/carlos-aguayo/followers",
"following_url": "https://api.github.com/users/carlos-aguayo/following{/other_user}",
"gists_url": "https://api.github.com/users/carlos-aguayo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/carlos-aguayo",
"id": 338917,
"login": "carlos-aguayo",
"node_id": "MDQ6VXNlcjMzODkxNw==",
"organizations_url": "https://api.github.com/users/carlos-aguayo/orgs",
"received_events_url": "https://api.github.com/users/carlos-aguayo/received_events",
"repos_url": "https://api.github.com/users/carlos-aguayo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/carlos-aguayo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/carlos-aguayo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/carlos-aguayo",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/222/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/222/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/221
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/221/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/221/comments
|
https://api.github.com/repos/huggingface/datasets/issues/221/events
|
https://github.com/huggingface/datasets/pull/221
| 627,300,648
|
MDExOlB1bGxSZXF1ZXN0NDI1MTI5OTc0
| 221
|
Fix tests/test_dataset_common.py
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13635495?v=4",
"events_url": "https://api.github.com/users/tayciryahmed/events{/privacy}",
"followers_url": "https://api.github.com/users/tayciryahmed/followers",
"following_url": "https://api.github.com/users/tayciryahmed/following{/other_user}",
"gists_url": "https://api.github.com/users/tayciryahmed/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tayciryahmed",
"id": 13635495,
"login": "tayciryahmed",
"node_id": "MDQ6VXNlcjEzNjM1NDk1",
"organizations_url": "https://api.github.com/users/tayciryahmed/orgs",
"received_events_url": "https://api.github.com/users/tayciryahmed/received_events",
"repos_url": "https://api.github.com/users/tayciryahmed/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tayciryahmed/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tayciryahmed/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tayciryahmed",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-05-29 14:12:15+00:00
|
2020-06-01 12:20:42+00:00
|
2020-05-29 15:02:23+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/221.diff",
"html_url": "https://github.com/huggingface/datasets/pull/221",
"merged_at": "2020-05-29T15:02:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/221.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/221"
}
|
When I run the command `RUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_arcd` while working on #220. I get the error ` unexpected keyword argument "'download_and_prepare_kwargs'"` at the level of `load_dataset`. Indeed, this [function](https://github.com/huggingface/nlp/blob/master/src/nlp/load.py#L441) no longer has the argument `download_and_prepare_kwargs` but rather `download_config`. So here I change the tests accordingly.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/221/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/221/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/220
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/220/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/220/comments
|
https://api.github.com/repos/huggingface/datasets/issues/220/events
|
https://github.com/huggingface/datasets/pull/220
| 627,280,683
|
MDExOlB1bGxSZXF1ZXN0NDI1MTEzMzEy
| 220
|
dataset_arcd
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13635495?v=4",
"events_url": "https://api.github.com/users/tayciryahmed/events{/privacy}",
"followers_url": "https://api.github.com/users/tayciryahmed/followers",
"following_url": "https://api.github.com/users/tayciryahmed/following{/other_user}",
"gists_url": "https://api.github.com/users/tayciryahmed/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tayciryahmed",
"id": 13635495,
"login": "tayciryahmed",
"node_id": "MDQ6VXNlcjEzNjM1NDk1",
"organizations_url": "https://api.github.com/users/tayciryahmed/orgs",
"received_events_url": "https://api.github.com/users/tayciryahmed/received_events",
"repos_url": "https://api.github.com/users/tayciryahmed/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tayciryahmed/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tayciryahmed/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tayciryahmed",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-05-29 13:46:50+00:00
|
2020-05-29 14:58:40+00:00
|
2020-05-29 14:57:21+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/220.diff",
"html_url": "https://github.com/huggingface/datasets/pull/220",
"merged_at": "2020-05-29T14:57:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/220.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/220"
}
|
Added Arabic Reading Comprehension Dataset (ARCD): https://arxiv.org/abs/1906.05394
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 1,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/220/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/220/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/219
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/219/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/219/comments
|
https://api.github.com/repos/huggingface/datasets/issues/219/events
|
https://github.com/huggingface/datasets/pull/219
| 627,235,893
|
MDExOlB1bGxSZXF1ZXN0NDI1MDc2NjQx
| 219
|
force mwparserfromhell as third party
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-29 12:33:17+00:00
|
2020-05-29 13:30:13+00:00
|
2020-05-29 13:30:12+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/219.diff",
"html_url": "https://github.com/huggingface/datasets/pull/219",
"merged_at": "2020-05-29T13:30:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/219.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/219"
}
|
This should fix your env because you had `mwparserfromhell ` as a first party for `isort` @patrickvonplaten
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/219/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/219/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/218
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/218/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/218/comments
|
https://api.github.com/repos/huggingface/datasets/issues/218/events
|
https://github.com/huggingface/datasets/pull/218
| 627,173,407
|
MDExOlB1bGxSZXF1ZXN0NDI1MDI2NzEz
| 218
|
Add Natual Questions and C4 scripts
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-29 10:40:30+00:00
|
2020-05-29 12:31:01+00:00
|
2020-05-29 12:31:00+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/218.diff",
"html_url": "https://github.com/huggingface/datasets/pull/218",
"merged_at": "2020-05-29T12:31:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/218.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/218"
}
|
Scripts are ready !
However they are not processed nor directly available from gcp yet.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/218/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/218/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/217
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/217/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/217/comments
|
https://api.github.com/repos/huggingface/datasets/issues/217/events
|
https://github.com/huggingface/datasets/issues/217
| 627,128,403
|
MDU6SXNzdWU2MjcxMjg0MDM=
| 217
|
Multi-task dataset mixing
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13795113?v=4",
"events_url": "https://api.github.com/users/ghomasHudson/events{/privacy}",
"followers_url": "https://api.github.com/users/ghomasHudson/followers",
"following_url": "https://api.github.com/users/ghomasHudson/following{/other_user}",
"gists_url": "https://api.github.com/users/ghomasHudson/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ghomasHudson",
"id": 13795113,
"login": "ghomasHudson",
"node_id": "MDQ6VXNlcjEzNzk1MTEz",
"organizations_url": "https://api.github.com/users/ghomasHudson/orgs",
"received_events_url": "https://api.github.com/users/ghomasHudson/received_events",
"repos_url": "https://api.github.com/users/ghomasHudson/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ghomasHudson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghomasHudson/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ghomasHudson",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] |
open
| false
| null |
[] | null | 28
|
2020-05-29 09:22:26+00:00
|
2025-09-24 08:59:38+00:00
|
NaT
|
CONTRIBUTOR
| null | null | null | null |
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sample from tasks proportionally to their dataset size
- **Equal mixing** - sample uniformly from each task
- **Temperature-scaled mixing** - The generalized approach used by multilingual BERT which uses a temperature T, where the mixing rate of each task is raised to the power 1/T and renormalized. When T=1 this is equivalent to equal mixing, and becomes closer to equal mixing with increasing T.
Following this discussion https://github.com/huggingface/transformers/issues/4340 in [transformers](https://github.com/huggingface/transformers), @enzoampil suggested that the `nlp` library might be a better place for this functionality.
Some method for combining datasets could be implemented ,e.g.
```
dataset = nlp.load_multitask(['squad','imdb','cnn_dm'], temperature=2.0, ...)
```
We would need a few additions:
- Method of identifying the tasks - how can we support adding a string to each task as an identifier: e.g. 'summarisation: '?
- Method of combining the metrics - a standard approach is to use the specific metric for each task and add them together for a combined score.
It would be great to support common use cases such as pretraining on the GLUE benchmark before fine-tuning on each GLUE task in turn.
I'm willing to write bits/most of this I just need some guidance on the interface and other library details so I can integrate it properly.
| null |
{
"+1": 12,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 12,
"url": "https://api.github.com/repos/huggingface/datasets/issues/217/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/217/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/216
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/216/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/216/comments
|
https://api.github.com/repos/huggingface/datasets/issues/216/events
|
https://github.com/huggingface/datasets/issues/216
| 626,896,890
|
MDU6SXNzdWU2MjY4OTY4OTA=
| 216
|
❓ How to get ROUGE-2 with the ROUGE metric ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-05-28 23:47:32+00:00
|
2020-06-01 00:04:35+00:00
|
2020-06-01 00:04:35+00:00
|
NONE
| null | null | null | null |
I'm trying to use ROUGE metric, but I don't know how to get the ROUGE-2 metric.
---
I compute scores with :
```python
import nlp
rouge = nlp.load_metric('rouge')
with open("pred.txt") as p, open("ref.txt") as g:
for lp, lg in zip(p, g):
rouge.add([lp], [lg])
score = rouge.compute()
```
then : _(print only the F-score for readability)_
```python
for k, s in score.items():
print(k, s.mid.fmeasure)
```
It gives :
>rouge1 0.7915168355671788
rougeL 0.7915168355671788
---
**How can I get the ROUGE-2 score ?**
Also, it's seems weird that ROUGE-1 and ROUGE-L scores are the same. Did I made a mistake ?
@lhoestq
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/216/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/216/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/215
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/215/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/215/comments
|
https://api.github.com/repos/huggingface/datasets/issues/215/events
|
https://github.com/huggingface/datasets/issues/215
| 626,867,879
|
MDU6SXNzdWU2MjY4Njc4Nzk=
| 215
|
NonMatchingSplitsSizesError when loading blog_authorship_corpus
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/52105365?v=4",
"events_url": "https://api.github.com/users/cedricconol/events{/privacy}",
"followers_url": "https://api.github.com/users/cedricconol/followers",
"following_url": "https://api.github.com/users/cedricconol/following{/other_user}",
"gists_url": "https://api.github.com/users/cedricconol/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cedricconol",
"id": 52105365,
"login": "cedricconol",
"node_id": "MDQ6VXNlcjUyMTA1MzY1",
"organizations_url": "https://api.github.com/users/cedricconol/orgs",
"received_events_url": "https://api.github.com/users/cedricconol/received_events",
"repos_url": "https://api.github.com/users/cedricconol/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cedricconol/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cedricconol/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cedricconol",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
| null |
[] | null | 12
|
2020-05-28 22:55:19+00:00
|
2025-01-04 00:03:12+00:00
|
2022-02-10 13:05:45+00:00
|
NONE
| null | null | null | null |
Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_examples=532812, dataset_name='blog_authorship_corpus'),
'recorded': SplitInfo(name='train', num_bytes=616473500, num_examples=536323,
dataset_name='blog_authorship_corpus')}, {'expected': SplitInfo(name='validation',
num_bytes=37500394, num_examples=31277, dataset_name='blog_authorship_corpus'),
'recorded': SplitInfo(name='validation', num_bytes=30786661, num_examples=27766,
dataset_name='blog_authorship_corpus')}]
```
Upon checking it seems like there is a disparity between the information in `datasets/blog_authorship_corpus/dataset_infos.json` and what was downloaded. Although I can get away with this by passing `ignore_verifications=True` in `load_dataset`, I'm thinking doing so might give problems later on.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/215/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/215/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/214
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/214/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/214/comments
|
https://api.github.com/repos/huggingface/datasets/issues/214/events
|
https://github.com/huggingface/datasets/pull/214
| 626,641,549
|
MDExOlB1bGxSZXF1ZXN0NDI0NTk1NjIx
| 214
|
[arrow_dataset.py] add new filter function
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 13
|
2020-05-28 16:21:40+00:00
|
2020-05-29 11:43:29+00:00
|
2020-05-29 11:32:20+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/214.diff",
"html_url": "https://github.com/huggingface/datasets/pull/214",
"merged_at": "2020-05-29T11:32:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/214.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/214"
}
|
The `.map()` function is super useful, but can IMO a bit tedious when filtering certain examples.
I think, filtering out examples is also a very common operation people would like to perform on datasets.
This PR is a proposal to add a `.filter()` function in the same spirit than the `.map()` function.
Here is a sample code you can play around with:
```python
ds = nlp.load_dataset("squad", split="validation[:10%]")
def remove_under_idx_5(example, idx):
return idx < 5
def only_keep_examples_with_is_in_context(example):
return "is" in example["context"]
result_keep_only_first_5 = ds.filter(remove_under_idx_5, with_indices=True, load_from_cache_file=False)
result_keep_examples_with_is_in_context = ds.filter(only_keep_examples_with_is_in_context, load_from_cache_file=False)
print("Original number of examples: {}".format(len(ds)))
print("First five examples number of examples: {}".format(len(result_keep_only_first_5)))
print("Is in context examples number of examples: {}".format(len(result_keep_examples_with_is_in_context)))
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/214/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/214/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/213
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/213/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/213/comments
|
https://api.github.com/repos/huggingface/datasets/issues/213/events
|
https://github.com/huggingface/datasets/pull/213
| 626,587,995
|
MDExOlB1bGxSZXF1ZXN0NDI0NTUxODE3
| 213
|
better message if missing beam options
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-28 15:06:57+00:00
|
2020-05-29 09:51:17+00:00
|
2020-05-29 09:51:16+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/213.diff",
"html_url": "https://github.com/huggingface/datasets/pull/213",
"merged_at": "2020-05-29T09:51:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/213.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/213"
}
|
WDYT @yjernite ?
For example:
```python
dataset = nlp.load_dataset('wikipedia', '20200501.aa')
```
Raises:
```
MissingBeamOptions: Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided in `load_dataset` or in the builder arguments. For big datasets it has to run on large-scale data processing tools like Dataflow, Spark, etc. More information about Apache Beam runners at https://beam.apache.org/documentation/runners/capability-matrix/
If you really want to run it locally because you feel like the Dataset is small enough, you can use the local beam runner called `DirectRunner` (you may run out of memory).
Example of usage:
`load_dataset('wikipedia', '20200501.aa', beam_runner='DirectRunner')`
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/213/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/213/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/212
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/212/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/212/comments
|
https://api.github.com/repos/huggingface/datasets/issues/212/events
|
https://github.com/huggingface/datasets/pull/212
| 626,580,198
|
MDExOlB1bGxSZXF1ZXN0NDI0NTQ1NjAy
| 212
|
have 'add' and 'add_batch' for metrics
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-28 14:56:47+00:00
|
2020-05-29 10:41:05+00:00
|
2020-05-29 10:41:04+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/212.diff",
"html_url": "https://github.com/huggingface/datasets/pull/212",
"merged_at": "2020-05-29T10:41:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/212.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/212"
}
|
This should fix #116
Previously the `.add` method of metrics expected a batch of examples.
Now `.add` expects one prediction/reference and `.add_batch` expects a batch.
I think it is more coherent with the way the ArrowWriter works.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/212/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/212/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/211
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/211/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/211/comments
|
https://api.github.com/repos/huggingface/datasets/issues/211/events
|
https://github.com/huggingface/datasets/issues/211
| 626,565,994
|
MDU6SXNzdWU2MjY1NjU5OTQ=
| 211
|
[Arrow writer, Trivia_qa] Could not convert TagMe with type str: converting to null type
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
},
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
},
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null | 7
|
2020-05-28 14:38:14+00:00
|
2020-07-23 10:15:16+00:00
|
2020-07-23 10:15:16+00:00
|
CONTRIBUTOR
| null | null | null | null |
Running the following code
```
import nlp
ds = nlp.load_dataset("trivia_qa", "rc", split="validation[:1%]") # this might take 2.3 min to download but it's cached afterwards...
ds.map(lambda x: x, load_from_cache_file=False)
```
triggers a `ArrowInvalid: Could not convert TagMe with type str: converting to null type` error.
On the other hand if we remove a certain column of `trivia_qa` which seems responsible for the bug, it works:
```
import nlp
ds = nlp.load_dataset("trivia_qa", "rc", split="validation[:1%]") # this might take 2.3 min to download but it's cached afterwards...
ds.map(lambda x: x, remove_columns=["entity_pages"], load_from_cache_file=False)
```
. Seems quite hard to debug what's going on here... @lhoestq @thomwolf - do you have a good first guess what the problem could be?
**Note** BTW: I think this could be a good test to check that the datasets work correctly: Take a tiny portion of the dataset and check that it can be written correctly.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/211/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/211/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/210
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/210/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/210/comments
|
https://api.github.com/repos/huggingface/datasets/issues/210/events
|
https://github.com/huggingface/datasets/pull/210
| 626,504,243
|
MDExOlB1bGxSZXF1ZXN0NDI0NDgyNDgz
| 210
|
fix xnli metric kwargs description
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-28 13:21:44+00:00
|
2020-05-28 13:22:11+00:00
|
2020-05-28 13:22:10+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/210.diff",
"html_url": "https://github.com/huggingface/datasets/pull/210",
"merged_at": "2020-05-28T13:22:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/210.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/210"
}
|
The text was wrong as noticed in #202
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/210/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/210/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/209
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/209/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/209/comments
|
https://api.github.com/repos/huggingface/datasets/issues/209/events
|
https://github.com/huggingface/datasets/pull/209
| 626,405,849
|
MDExOlB1bGxSZXF1ZXN0NDI0NDAwOTc4
| 209
|
Add a Google Drive exception for small files
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/25703835?v=4",
"events_url": "https://api.github.com/users/airKlizz/events{/privacy}",
"followers_url": "https://api.github.com/users/airKlizz/followers",
"following_url": "https://api.github.com/users/airKlizz/following{/other_user}",
"gists_url": "https://api.github.com/users/airKlizz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/airKlizz",
"id": 25703835,
"login": "airKlizz",
"node_id": "MDQ6VXNlcjI1NzAzODM1",
"organizations_url": "https://api.github.com/users/airKlizz/orgs",
"received_events_url": "https://api.github.com/users/airKlizz/received_events",
"repos_url": "https://api.github.com/users/airKlizz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/airKlizz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/airKlizz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/airKlizz",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-05-28 10:40:17+00:00
|
2020-05-28 15:15:04+00:00
|
2020-05-28 15:15:04+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/209.diff",
"html_url": "https://github.com/huggingface/datasets/pull/209",
"merged_at": "2020-05-28T15:15:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/209.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/209"
}
|
I tried to use the ``nlp`` library to load personnal datasets. I mainly copy-paste the code for ``multi-news`` dataset because my files are stored on Google Drive.
One of my dataset is small (< 25Mo) so it can be verified by Drive without asking the authorization to the user. This makes the download starts directly.
Currently the ``nlp`` raises a error: ``ConnectionError: Couldn't reach https://drive.google.com/uc?export=download&id=1DGnbUY9zwiThTdgUvVTSAvSVHoloCgun`` while the url is working. So I just add a new exception as you have already done for ``firebasestorage.googleapis.com`` :
```
elif (response.status_code == 400 and "firebasestorage.googleapis.com" in url) or (response.status_code == 405 and "drive.google.com" in url)
```
I make an example of the error that you can run on [](https://colab.research.google.com/drive/1ae_JJ9uvUt-9GBh0uGZhjbF5aXkl-BPv?usp=sharing)
I avoid the error by adding an exception but there is maybe a proper way to do it.
Many thanks :hugs:
Best,
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/209/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/209/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/208
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/208/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/208/comments
|
https://api.github.com/repos/huggingface/datasets/issues/208/events
|
https://github.com/huggingface/datasets/pull/208
| 626,398,519
|
MDExOlB1bGxSZXF1ZXN0NDI0Mzk0ODIx
| 208
|
[Dummy data] insert config name instead of config
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-28 10:28:19+00:00
|
2020-05-28 12:48:01+00:00
|
2020-05-28 12:48:00+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/208.diff",
"html_url": "https://github.com/huggingface/datasets/pull/208",
"merged_at": "2020-05-28T12:48:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/208.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/208"
}
|
Thanks @yjernite for letting me know. in the dummy data command the config name shuold be passed to the dataset builder and not the config itself.
Also, @lhoestq fixed small import bug introduced by beam command I think.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/208/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/208/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/207
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/207/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/207/comments
|
https://api.github.com/repos/huggingface/datasets/issues/207/events
|
https://github.com/huggingface/datasets/issues/207
| 625,932,200
|
MDU6SXNzdWU2MjU5MzIyMDA=
| 207
|
Remove test set from NLP viewer
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/748399?v=4",
"events_url": "https://api.github.com/users/chrisdonahue/events{/privacy}",
"followers_url": "https://api.github.com/users/chrisdonahue/followers",
"following_url": "https://api.github.com/users/chrisdonahue/following{/other_user}",
"gists_url": "https://api.github.com/users/chrisdonahue/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/chrisdonahue",
"id": 748399,
"login": "chrisdonahue",
"node_id": "MDQ6VXNlcjc0ODM5OQ==",
"organizations_url": "https://api.github.com/users/chrisdonahue/orgs",
"received_events_url": "https://api.github.com/users/chrisdonahue/received_events",
"repos_url": "https://api.github.com/users/chrisdonahue/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/chrisdonahue/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chrisdonahue/subscriptions",
"type": "User",
"url": "https://api.github.com/users/chrisdonahue",
"user_view_type": "public"
}
|
[
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] |
closed
| false
| null |
[] | null | 3
|
2020-05-27 18:32:07+00:00
|
2022-02-10 13:17:45+00:00
|
2022-02-10 13:17:45+00:00
|
NONE
| null | null | null | null |
While the new [NLP viewer](https://huggingface.co/nlp/viewer/) is a great tool, I think it would be best to outright remove the option of looking at the test sets. At the very least, a warning should be displayed to users before showing the test set. Newcomers to the field might not be aware of best practices, and small things like this can help increase awareness.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/207/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/207/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/206
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/206/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/206/comments
|
https://api.github.com/repos/huggingface/datasets/issues/206/events
|
https://github.com/huggingface/datasets/issues/206
| 625,842,989
|
MDU6SXNzdWU2MjU4NDI5ODk=
| 206
|
[Question] Combine 2 datasets which have the same columns
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/25703835?v=4",
"events_url": "https://api.github.com/users/airKlizz/events{/privacy}",
"followers_url": "https://api.github.com/users/airKlizz/followers",
"following_url": "https://api.github.com/users/airKlizz/following{/other_user}",
"gists_url": "https://api.github.com/users/airKlizz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/airKlizz",
"id": 25703835,
"login": "airKlizz",
"node_id": "MDQ6VXNlcjI1NzAzODM1",
"organizations_url": "https://api.github.com/users/airKlizz/orgs",
"received_events_url": "https://api.github.com/users/airKlizz/received_events",
"repos_url": "https://api.github.com/users/airKlizz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/airKlizz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/airKlizz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/airKlizz",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-05-27 16:25:52+00:00
|
2020-06-10 09:11:14+00:00
|
2020-06-10 09:11:14+00:00
|
CONTRIBUTOR
| null | null | null | null |
Hi,
I am using ``nlp`` to load personal datasets. I created summarization datasets in multi-languages based on wikinews. I have one dataset for english and one for german (french is getting to be ready as well). I want to keep these datasets independent because they need different pre-processing (add different task-specific prefixes for T5 : *summarize:* for english and *zusammenfassen:* for german)
My issue is that I want to train T5 on the combined english and german datasets to see if it improves results. So I would like to combine 2 datasets (which have the same columns) to make one and train T5 on it. I was wondering if there is a proper way to do it? I assume that it can be done by combining all examples of each dataset but maybe you have a better solution.
Hoping this is clear enough,
Thanks a lot 😊
Best
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/25703835?v=4",
"events_url": "https://api.github.com/users/airKlizz/events{/privacy}",
"followers_url": "https://api.github.com/users/airKlizz/followers",
"following_url": "https://api.github.com/users/airKlizz/following{/other_user}",
"gists_url": "https://api.github.com/users/airKlizz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/airKlizz",
"id": 25703835,
"login": "airKlizz",
"node_id": "MDQ6VXNlcjI1NzAzODM1",
"organizations_url": "https://api.github.com/users/airKlizz/orgs",
"received_events_url": "https://api.github.com/users/airKlizz/received_events",
"repos_url": "https://api.github.com/users/airKlizz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/airKlizz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/airKlizz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/airKlizz",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/206/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/206/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/205
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/205/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/205/comments
|
https://api.github.com/repos/huggingface/datasets/issues/205/events
|
https://github.com/huggingface/datasets/pull/205
| 625,839,335
|
MDExOlB1bGxSZXF1ZXN0NDIzOTY2ODE1
| 205
|
Better arrow dataset iter
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-27 16:20:21+00:00
|
2020-05-27 16:39:58+00:00
|
2020-05-27 16:39:56+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/205.diff",
"html_url": "https://github.com/huggingface/datasets/pull/205",
"merged_at": "2020-05-27T16:39:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/205.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/205"
}
|
I tried to play around with `tf.data.Dataset.from_generator` and I found out that the `__iter__` that we have for `nlp.arrow_dataset.Dataset` ignores the format that has been set (torch or tensorflow).
With these changes I should be able to come up with a `tf.data.Dataset` that uses lazy loading, as asked in #193.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/205/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/205/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/204
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/204/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/204/comments
|
https://api.github.com/repos/huggingface/datasets/issues/204/events
|
https://github.com/huggingface/datasets/pull/204
| 625,655,849
|
MDExOlB1bGxSZXF1ZXN0NDIzODE5MTQw
| 204
|
Add Dataflow support + Wikipedia + Wiki40b
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-27 12:32:49+00:00
|
2020-05-28 08:10:35+00:00
|
2020-05-28 08:10:34+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/204.diff",
"html_url": "https://github.com/huggingface/datasets/pull/204",
"merged_at": "2020-05-28T08:10:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/204.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/204"
}
|
# Add Dataflow support + Wikipedia + Wiki40b
## Support datasets processing with Apache Beam
Some datasets are too big to be processed on a single machine, for example: wikipedia, wiki40b, etc. Apache Beam allows to process datasets on many execution engines like Dataflow, Spark, Flink, etc.
To process such datasets with Beam, I added a command to run beam pipelines `nlp-cli run_beam path/to/dataset/script`. Then I used it to process the english + french wikipedia, and the english of wiki40b.
The processed arrow files are on GCS and are the result of a Dataflow job.
I added a markdown documentation file in `docs` that explains how to use it properly.
## Load already processed datasets
Now that we have those datasets already processed, I made it possible to load datasets that are already processed. You can do `load_dataset('wikipedia', '20200501.en')` and it will download the processed files from the Hugging Face GCS directly into the user's cache and be ready to use !
The Wikipedia dataset was already asked in #187 and this PR should soon allow to add Natural Questions as asked in #129
## Other changes in the code
To make things work, I had to do a few adjustments:
- add a `ship_files_with_pipeline` method to the `DownloadManager`. This is because beam pipelines can be run in the cloud and therefore need to have access to your downloaded data. I used it in the wikipedia script:
```python
if not pipeline.is_local():
downloaded_files = dl_manager.ship_files_with_pipeline(downloaded_files, pipeline)
```
- add parquet to arrow conversion. This is because the output of beam pipelines are parquet files so we need to convert them to arrow and have the arrow files on GCS
- add a test script with a dummy beam dataset
- minor adjustments to allow read/write operations on remote files using `apache_beam.io.filesystems.FileSystems` if we want (it can be connected to gcp, s3, hdfs, etc...)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/204/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/204/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/203
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/203/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/203/comments
|
https://api.github.com/repos/huggingface/datasets/issues/203/events
|
https://github.com/huggingface/datasets/pull/203
| 625,515,488
|
MDExOlB1bGxSZXF1ZXN0NDIzNzEyMTQ3
| 203
|
Raise an error if no config name for datasets like glue
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-27 09:03:58+00:00
|
2020-05-27 16:40:39+00:00
|
2020-05-27 16:40:38+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/203.diff",
"html_url": "https://github.com/huggingface/datasets/pull/203",
"merged_at": "2020-05-27T16:40:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/203.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/203"
}
|
Some datasets like glue (see #130) and scientific_papers (see #197) have many configs.
For example for glue there are cola, sst2, mrpc etc.
Currently if a user does `load_dataset('glue')`, then Cola is loaded by default and it can be confusing. Instead, we should raise an error to let the user know that he has to pick one of the available configs (as proposed in #152). For example for glue, the message looks like:
```
ValueError: Config name is missing.
Please pick one among the available configs: ['cola', 'sst2', 'mrpc', 'qqp', 'stsb', 'mnli', 'mnli_mismatched', 'mnli_matched', 'qnli', 'rte', 'wnli', 'ax']
Example of usage:
`load_dataset('glue', 'cola')`
```
The error is raised if the config name is missing and if there are >=2 possible configs.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/203/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/203/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/202
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/202/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/202/comments
|
https://api.github.com/repos/huggingface/datasets/issues/202/events
|
https://github.com/huggingface/datasets/issues/202
| 625,493,983
|
MDU6SXNzdWU2MjU0OTM5ODM=
| 202
|
Mistaken `_KWARGS_DESCRIPTION` for XNLI metric
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/33572125?v=4",
"events_url": "https://api.github.com/users/phiyodr/events{/privacy}",
"followers_url": "https://api.github.com/users/phiyodr/followers",
"following_url": "https://api.github.com/users/phiyodr/following{/other_user}",
"gists_url": "https://api.github.com/users/phiyodr/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/phiyodr",
"id": 33572125,
"login": "phiyodr",
"node_id": "MDQ6VXNlcjMzNTcyMTI1",
"organizations_url": "https://api.github.com/users/phiyodr/orgs",
"received_events_url": "https://api.github.com/users/phiyodr/received_events",
"repos_url": "https://api.github.com/users/phiyodr/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/phiyodr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/phiyodr/subscriptions",
"type": "User",
"url": "https://api.github.com/users/phiyodr",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-05-27 08:34:42+00:00
|
2020-05-28 13:22:36+00:00
|
2020-05-28 13:22:36+00:00
|
NONE
| null | null | null | null |
Hi!
The [`_KWARGS_DESCRIPTION`](https://github.com/huggingface/nlp/blob/7d0fa58641f3f462fb2861dcdd6ce7f0da3f6a56/metrics/xnli/xnli.py#L45) for the XNLI metric uses `Args` and `Returns` text from [BLEU](https://github.com/huggingface/nlp/blob/7d0fa58641f3f462fb2861dcdd6ce7f0da3f6a56/metrics/bleu/bleu.py#L58) metric:
```
_KWARGS_DESCRIPTION = """
Computes XNLI score which is just simple accuracy.
Args:
predictions: list of translations to score.
Each translation should be tokenized into a list of tokens.
references: list of lists of references for each translation.
Each reference should be tokenized into a list of tokens.
max_order: Maximum n-gram order to use when computing BLEU score.
smooth: Whether or not to apply Lin et al. 2004 smoothing.
Returns:
'bleu': bleu score,
'precisions': geometric mean of n-gram precisions,
'brevity_penalty': brevity penalty,
'length_ratio': ratio of lengths,
'translation_length': translation_length,
'reference_length': reference_length
"""
```
But it should be something like:
```
_KWARGS_DESCRIPTION = """
Computes XNLI score which is just simple accuracy.
Args:
predictions: Predicted labels.
references: Ground truth labels.
Returns:
'accuracy': accuracy
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/202/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/202/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/201
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/201/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/201/comments
|
https://api.github.com/repos/huggingface/datasets/issues/201/events
|
https://github.com/huggingface/datasets/pull/201
| 625,235,430
|
MDExOlB1bGxSZXF1ZXN0NDIzNDkzNTMw
| 201
|
Fix typo in README
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LysandreJik",
"id": 30755778,
"login": "LysandreJik",
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LysandreJik",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-05-26 22:18:21+00:00
|
2020-05-26 23:40:31+00:00
|
2020-05-26 23:00:56+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/201.diff",
"html_url": "https://github.com/huggingface/datasets/pull/201",
"merged_at": "2020-05-26T23:00:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/201.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/201"
}
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/201/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/201/timeline
| null | null | null | null | true
|
|
https://api.github.com/repos/huggingface/datasets/issues/200
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/200/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/200/comments
|
https://api.github.com/repos/huggingface/datasets/issues/200/events
|
https://github.com/huggingface/datasets/pull/200
| 625,226,638
|
MDExOlB1bGxSZXF1ZXN0NDIzNDg2NTM0
| 200
|
[ArrowWriter] Set schema at first write example
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-05-26 21:59:48+00:00
|
2020-05-27 09:07:54+00:00
|
2020-05-27 09:07:53+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/200.diff",
"html_url": "https://github.com/huggingface/datasets/pull/200",
"merged_at": "2020-05-27T09:07:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/200.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/200"
}
|
Right now if the schema was not specified when instantiating `ArrowWriter`, then it could be set with the first `write_table` for example (it calls `self._build_writer()` to do so).
I noticed that it was not done if the first example is added via `.write`, so I added it for coherence.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/200/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/200/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/199
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/199/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/199/comments
|
https://api.github.com/repos/huggingface/datasets/issues/199/events
|
https://github.com/huggingface/datasets/pull/199
| 625,217,440
|
MDExOlB1bGxSZXF1ZXN0NDIzNDc4ODIx
| 199
|
Fix GermEval 2014 dataset infos
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stefan-it",
"id": 20651387,
"login": "stefan-it",
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stefan-it",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-05-26 21:41:44+00:00
|
2020-05-26 21:50:24+00:00
|
2020-05-26 21:50:24+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/199.diff",
"html_url": "https://github.com/huggingface/datasets/pull/199",
"merged_at": "2020-05-26T21:50:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/199.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/199"
}
|
Hi,
this PR just removes the `dataset_info.json` file and adds a newly generated `dataset_infos.json` file.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/199/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/199/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/198
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/198/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/198/comments
|
https://api.github.com/repos/huggingface/datasets/issues/198/events
|
https://github.com/huggingface/datasets/issues/198
| 625,200,627
|
MDU6SXNzdWU2MjUyMDA2Mjc=
| 198
|
Index outside of table length
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/305717?v=4",
"events_url": "https://api.github.com/users/casajarm/events{/privacy}",
"followers_url": "https://api.github.com/users/casajarm/followers",
"following_url": "https://api.github.com/users/casajarm/following{/other_user}",
"gists_url": "https://api.github.com/users/casajarm/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/casajarm",
"id": 305717,
"login": "casajarm",
"node_id": "MDQ6VXNlcjMwNTcxNw==",
"organizations_url": "https://api.github.com/users/casajarm/orgs",
"received_events_url": "https://api.github.com/users/casajarm/received_events",
"repos_url": "https://api.github.com/users/casajarm/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/casajarm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/casajarm/subscriptions",
"type": "User",
"url": "https://api.github.com/users/casajarm",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-05-26 21:09:40+00:00
|
2020-05-26 22:43:49+00:00
|
2020-05-26 22:43:49+00:00
|
NONE
| null | null | null | null |
The offset input box warns of numbers larger than a limit (like 2000) but then the errors start at a smaller value than that limit (like 1955).
> ValueError: Index (2000) outside of table length (2000).
> Traceback:
> File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/ScriptRunner.py", line 322, in _run_script
> exec(code, module.__dict__)
> File "/home/sasha/nlp_viewer/run.py", line 116, in <module>
> v = d[item][k]
> File "/home/sasha/.local/lib/python3.7/site-packages/nlp/arrow_dataset.py", line 338, in __getitem__
> output_all_columns=self._output_all_columns,
> File "/home/sasha/.local/lib/python3.7/site-packages/nlp/arrow_dataset.py", line 290, in _getitem
> raise ValueError(f"Index ({key}) outside of table length ({self._data.num_rows}).")
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35882?v=4",
"events_url": "https://api.github.com/users/srush/events{/privacy}",
"followers_url": "https://api.github.com/users/srush/followers",
"following_url": "https://api.github.com/users/srush/following{/other_user}",
"gists_url": "https://api.github.com/users/srush/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/srush",
"id": 35882,
"login": "srush",
"node_id": "MDQ6VXNlcjM1ODgy",
"organizations_url": "https://api.github.com/users/srush/orgs",
"received_events_url": "https://api.github.com/users/srush/received_events",
"repos_url": "https://api.github.com/users/srush/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/srush/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/srush/subscriptions",
"type": "User",
"url": "https://api.github.com/users/srush",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/198/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/198/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/197
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/197/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/197/comments
|
https://api.github.com/repos/huggingface/datasets/issues/197/events
|
https://github.com/huggingface/datasets/issues/197
| 624,966,904
|
MDU6SXNzdWU2MjQ5NjY5MDQ=
| 197
|
Scientific Papers only downloading Pubmed
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17463361?v=4",
"events_url": "https://api.github.com/users/antmarakis/events{/privacy}",
"followers_url": "https://api.github.com/users/antmarakis/followers",
"following_url": "https://api.github.com/users/antmarakis/following{/other_user}",
"gists_url": "https://api.github.com/users/antmarakis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/antmarakis",
"id": 17463361,
"login": "antmarakis",
"node_id": "MDQ6VXNlcjE3NDYzMzYx",
"organizations_url": "https://api.github.com/users/antmarakis/orgs",
"received_events_url": "https://api.github.com/users/antmarakis/received_events",
"repos_url": "https://api.github.com/users/antmarakis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/antmarakis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/antmarakis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/antmarakis",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-05-26 15:18:47+00:00
|
2020-05-28 08:19:28+00:00
|
2020-05-28 08:19:28+00:00
|
NONE
| null | null | null | null |
Hi!
I have been playing around with this module, and I am a bit confused about the `scientific_papers` dataset. I thought that it would download two separate datasets, arxiv and pubmed. But when I run the following:
```
dataset = nlp.load_dataset('scientific_papers', data_dir='.', cache_dir='.')
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5.05k/5.05k [00:00<00:00, 2.66MB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.90k/4.90k [00:00<00:00, 2.42MB/s]
Downloading and preparing dataset scientific_papers/pubmed (download: 4.20 GiB, generated: 2.33 GiB, total: 6.53 GiB) to ./scientific_papers/pubmed/1.1.1...
Downloading: 3.62GB [00:40, 90.5MB/s]
Downloading: 880MB [00:08, 101MB/s]
Dataset scientific_papers downloaded and prepared to ./scientific_papers/pubmed/1.1.1. Subsequent calls will reuse this data.
```
only a pubmed folder is created. There doesn't seem to be something for arxiv. Are these two datasets merged? Or have I misunderstood something?
Thanks!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/197/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/197/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/196
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/196/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/196/comments
|
https://api.github.com/repos/huggingface/datasets/issues/196/events
|
https://github.com/huggingface/datasets/pull/196
| 624,901,266
|
MDExOlB1bGxSZXF1ZXN0NDIzMjIwMjIw
| 196
|
Check invalid config name
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 13
|
2020-05-26 13:52:51+00:00
|
2020-05-26 21:04:56+00:00
|
2020-05-26 21:04:55+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/196.diff",
"html_url": "https://github.com/huggingface/datasets/pull/196",
"merged_at": "2020-05-26T21:04:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/196.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/196"
}
|
As said in #194, we should raise an error if the config name has bad characters.
Bad characters are those that are not allowed for directory names on windows.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/196/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/196/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/195
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/195/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/195/comments
|
https://api.github.com/repos/huggingface/datasets/issues/195/events
|
https://github.com/huggingface/datasets/pull/195
| 624,858,686
|
MDExOlB1bGxSZXF1ZXN0NDIzMTg1NTAy
| 195
|
[Dummy data command] add new case to command
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-05-26 12:50:47+00:00
|
2020-05-26 14:38:28+00:00
|
2020-05-26 14:38:27+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/195.diff",
"html_url": "https://github.com/huggingface/datasets/pull/195",
"merged_at": "2020-05-26T14:38:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/195.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/195"
}
|
Qanta: #194 introduces a case that was not noticed before. This change in code helps community users to have an easier time creating the dummy data.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/195/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/195/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/194
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/194/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/194/comments
|
https://api.github.com/repos/huggingface/datasets/issues/194/events
|
https://github.com/huggingface/datasets/pull/194
| 624,854,897
|
MDExOlB1bGxSZXF1ZXN0NDIzMTgyNDM5
| 194
|
Add Dataset: Qanta
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-05-26 12:44:35+00:00
|
2020-05-26 16:58:17+00:00
|
2020-05-26 13:16:20+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/194.diff",
"html_url": "https://github.com/huggingface/datasets/pull/194",
"merged_at": "2020-05-26T13:16:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/194.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/194"
}
|
Fixes dummy data for #169 @EntilZha
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/194/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/194/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/193
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/193/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/193/comments
|
https://api.github.com/repos/huggingface/datasets/issues/193/events
|
https://github.com/huggingface/datasets/issues/193
| 624,655,558
|
MDU6SXNzdWU2MjQ2NTU1NTg=
| 193
|
[Tensorflow] Use something else than `from_tensor_slices()`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null | 7
|
2020-05-26 07:19:14+00:00
|
2020-10-27 15:28:11+00:00
|
2020-10-27 15:28:11+00:00
|
NONE
| null | null | null | null |
In the example notebook, the TF Dataset is built using `from_tensor_slices()` :
```python
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'start_positions', 'end_positions']
train_tf_dataset.set_format(type='tensorflow', columns=columns)
features = {x: train_tf_dataset[x] for x in columns[:3]}
labels = {"output_1": train_tf_dataset["start_positions"]}
labels["output_2"] = train_tf_dataset["end_positions"]
tfdataset = tf.data.Dataset.from_tensor_slices((features, labels)).batch(8)
```
But according to [official tensorflow documentation](https://www.tensorflow.org/guide/data#consuming_numpy_arrays), this will load the entire dataset to memory.
**This defeats one purpose of this library, which is lazy loading.**
Is there any other way to load the `nlp` dataset into TF dataset lazily ?
---
For example, is it possible to use [Arrow dataset](https://www.tensorflow.org/io/api_docs/python/tfio/arrow/ArrowDataset) ? If yes, is there any code example ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/193/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/193/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/192
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/192/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/192/comments
|
https://api.github.com/repos/huggingface/datasets/issues/192/events
|
https://github.com/huggingface/datasets/issues/192
| 624,397,592
|
MDU6SXNzdWU2MjQzOTc1OTI=
| 192
|
[Question] Create Apache Arrow dataset from raw text file
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/3653789?v=4",
"events_url": "https://api.github.com/users/mrm8488/events{/privacy}",
"followers_url": "https://api.github.com/users/mrm8488/followers",
"following_url": "https://api.github.com/users/mrm8488/following{/other_user}",
"gists_url": "https://api.github.com/users/mrm8488/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mrm8488",
"id": 3653789,
"login": "mrm8488",
"node_id": "MDQ6VXNlcjM2NTM3ODk=",
"organizations_url": "https://api.github.com/users/mrm8488/orgs",
"received_events_url": "https://api.github.com/users/mrm8488/received_events",
"repos_url": "https://api.github.com/users/mrm8488/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mrm8488/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mrm8488/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mrm8488",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 4
|
2020-05-25 16:42:47+00:00
|
2021-12-18 01:45:34+00:00
|
2020-10-27 15:20:22+00:00
|
CONTRIBUTOR
| null | null | null | null |
Hi guys, I have gathered and preprocessed about 2GB of COVID papers from CORD dataset @ Kggle. I have seen you have a text dataset as "Crime and punishment" in Apache arrow format. Do you have any script to do it from a raw txt file (preprocessed as for BERT like) or any guide?
Is the worth of send it to you and add it to the NLP library?
Thanks, Manu
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/192/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/192/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/191
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/191/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/191/comments
|
https://api.github.com/repos/huggingface/datasets/issues/191/events
|
https://github.com/huggingface/datasets/pull/191
| 624,394,936
|
MDExOlB1bGxSZXF1ZXN0NDIyODI3MDMy
| 191
|
[Squad es] add dataset_infos
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-25 16:35:52+00:00
|
2020-05-25 16:39:59+00:00
|
2020-05-25 16:39:58+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/191.diff",
"html_url": "https://github.com/huggingface/datasets/pull/191",
"merged_at": "2020-05-25T16:39:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/191.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/191"
}
|
@mariamabarham - was still about to upload this. Should have waited with my comment a bit more :D
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/191/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/191/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/190
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/190/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/190/comments
|
https://api.github.com/repos/huggingface/datasets/issues/190/events
|
https://github.com/huggingface/datasets/pull/190
| 624,124,600
|
MDExOlB1bGxSZXF1ZXN0NDIyNjA4NzAw
| 190
|
add squad Spanish v1 and v2
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 5
|
2020-05-25 08:08:40+00:00
|
2020-05-25 16:28:46+00:00
|
2020-05-25 16:28:45+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/190.diff",
"html_url": "https://github.com/huggingface/datasets/pull/190",
"merged_at": "2020-05-25T16:28:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/190.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/190"
}
|
This PR add the Spanish Squad versions 1 and 2 datasets.
Fixes #164
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/190/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/190/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/189
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/189/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/189/comments
|
https://api.github.com/repos/huggingface/datasets/issues/189/events
|
https://github.com/huggingface/datasets/issues/189
| 624,048,881
|
MDU6SXNzdWU2MjQwNDg4ODE=
| 189
|
[Question] BERT-style multiple choice formatting
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sarahwie",
"id": 8027676,
"login": "sarahwie",
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sarahwie",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-05-25 05:11:05+00:00
|
2020-05-25 18:38:28+00:00
|
2020-05-25 18:38:28+00:00
|
NONE
| null | null | null | null |
Hello, I am wondering what the equivalent formatting of a dataset should be to allow for multiple-choice answering prediction, BERT-style. Previously, this was done by passing a list of `InputFeatures` to the dataloader instead of a list of `InputFeature`, where `InputFeatures` contained lists of length equal to the number of answer choices in the MCQ instead of single items. I'm a bit confused on what the output of my feature conversion function should be when using `dataset.map()` to ensure similar behavior.
Thanks!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sarahwie",
"id": 8027676,
"login": "sarahwie",
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sarahwie",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/189/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/189/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/188
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/188/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/188/comments
|
https://api.github.com/repos/huggingface/datasets/issues/188/events
|
https://github.com/huggingface/datasets/issues/188
| 623,890,430
|
MDU6SXNzdWU2MjM4OTA0MzA=
| 188
|
When will the remaining math_dataset modules be added as dataset objects
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/31251196?v=4",
"events_url": "https://api.github.com/users/tylerroost/events{/privacy}",
"followers_url": "https://api.github.com/users/tylerroost/followers",
"following_url": "https://api.github.com/users/tylerroost/following{/other_user}",
"gists_url": "https://api.github.com/users/tylerroost/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tylerroost",
"id": 31251196,
"login": "tylerroost",
"node_id": "MDQ6VXNlcjMxMjUxMTk2",
"organizations_url": "https://api.github.com/users/tylerroost/orgs",
"received_events_url": "https://api.github.com/users/tylerroost/received_events",
"repos_url": "https://api.github.com/users/tylerroost/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tylerroost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tylerroost/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tylerroost",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-05-24 15:46:52+00:00
|
2020-05-24 18:53:48+00:00
|
2020-05-24 18:53:48+00:00
|
NONE
| null | null | null | null |
Currently only the algebra_linear_1d is supported. Is there a timeline for making the other modules supported. If no timeline is established, how can I help?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/31251196?v=4",
"events_url": "https://api.github.com/users/tylerroost/events{/privacy}",
"followers_url": "https://api.github.com/users/tylerroost/followers",
"following_url": "https://api.github.com/users/tylerroost/following{/other_user}",
"gists_url": "https://api.github.com/users/tylerroost/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tylerroost",
"id": 31251196,
"login": "tylerroost",
"node_id": "MDQ6VXNlcjMxMjUxMTk2",
"organizations_url": "https://api.github.com/users/tylerroost/orgs",
"received_events_url": "https://api.github.com/users/tylerroost/received_events",
"repos_url": "https://api.github.com/users/tylerroost/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tylerroost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tylerroost/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tylerroost",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/188/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/188/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/187
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/187/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/187/comments
|
https://api.github.com/repos/huggingface/datasets/issues/187/events
|
https://github.com/huggingface/datasets/issues/187
| 623,627,800
|
MDU6SXNzdWU2MjM2Mjc4MDA=
| 187
|
[Question] How to load wikipedia ? Beam runner ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-05-23 10:18:52+00:00
|
2020-05-25 00:12:02+00:00
|
2020-05-25 00:12:02+00:00
|
CONTRIBUTOR
| null | null | null | null |
When `nlp.load_dataset('wikipedia')`, I got
* `WARNING:nlp.builder:Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided. Please pass a nlp.DownloadConfig(beam_runner=...) object to the builder.download_and_prepare(download_config=...) method. Default values will be used.`
* `AttributeError: 'NoneType' object has no attribute 'size'`
Could somebody tell me what should I do ?
# Env
On Colab,
```
git clone https://github.com/huggingface/nlp
cd nlp
pip install -q .
```
```
%pip install -q apache_beam mwparserfromhell
-> ERROR: pydrive 1.3.1 has requirement oauth2client>=4.0.0, but you'll have oauth2client 3.0.0 which is incompatible.
ERROR: google-api-python-client 1.7.12 has requirement httplib2<1dev,>=0.17.0, but you'll have httplib2 0.12.0 which is incompatible.
ERROR: chainer 6.5.0 has requirement typing-extensions<=3.6.6, but you'll have typing-extensions 3.7.4.2 which is incompatible.
```
```
pip install -q apache-beam[interactive]
ERROR: google-colab 1.0.0 has requirement ipython~=5.5.0, but you'll have ipython 5.10.0 which is incompatible.
```
# The whole message
```
WARNING:nlp.builder:Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided. Please pass a nlp.DownloadConfig(beam_runner=...) object to the builder.download_and_prepare(download_config=...) method. Default values will be used.
Downloading and preparing dataset wikipedia/20200501.aa (download: Unknown size, generated: Unknown size, total: Unknown size) to /root/.cache/huggingface/datasets/wikipedia/20200501.aa/1.0.0...
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.DoFnRunner.process()
44 frames
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.PerWindowInvoker.invoke_process()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window()
/usr/local/lib/python3.6/dist-packages/apache_beam/io/iobase.py in process(self, element, init_result)
1081 writer.write(e)
-> 1082 return [window.TimestampedValue(writer.close(), timestamp.MAX_TIMESTAMP)]
1083
/usr/local/lib/python3.6/dist-packages/apache_beam/io/filebasedsink.py in close(self)
422 def close(self):
--> 423 self.sink.close(self.temp_handle)
424 return self.temp_shard_path
/usr/local/lib/python3.6/dist-packages/apache_beam/io/parquetio.py in close(self, writer)
537 if len(self._buffer[0]) > 0:
--> 538 self._flush_buffer()
539 if self._record_batches_byte_size > 0:
/usr/local/lib/python3.6/dist-packages/apache_beam/io/parquetio.py in _flush_buffer(self)
569 for b in x.buffers():
--> 570 size = size + b.size
571 self._record_batches_byte_size = self._record_batches_byte_size + size
AttributeError: 'NoneType' object has no attribute 'size'
During handling of the above exception, another exception occurred:
AttributeError Traceback (most recent call last)
<ipython-input-9-340aabccefff> in <module>()
----> 1 dset = nlp.load_dataset('wikipedia')
/usr/local/lib/python3.6/dist-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
518 download_mode=download_mode,
519 ignore_verifications=ignore_verifications,
--> 520 save_infos=save_infos,
521 )
522
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, dl_manager, **download_and_prepare_kwargs)
370 verify_infos = not save_infos and not ignore_verifications
371 self._download_and_prepare(
--> 372 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
373 )
374 # Sync info
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos)
770 with beam.Pipeline(runner=beam_runner, options=beam_options,) as pipeline:
771 super(BeamBasedBuilder, self)._download_and_prepare(
--> 772 dl_manager, pipeline=pipeline, verify_infos=False
773 ) # TODO{beam} verify infos
774
/usr/local/lib/python3.6/dist-packages/apache_beam/pipeline.py in __exit__(self, exc_type, exc_val, exc_tb)
501 def __exit__(self, exc_type, exc_val, exc_tb):
502 if not exc_type:
--> 503 self.run().wait_until_finish()
504
505 def visit(self, visitor):
/usr/local/lib/python3.6/dist-packages/apache_beam/pipeline.py in run(self, test_runner_api)
481 return Pipeline.from_runner_api(
482 self.to_runner_api(use_fake_coders=True), self.runner,
--> 483 self._options).run(False)
484
485 if self._options.view_as(TypeOptions).runtime_type_check:
/usr/local/lib/python3.6/dist-packages/apache_beam/pipeline.py in run(self, test_runner_api)
494 finally:
495 shutil.rmtree(tmpdir)
--> 496 return self.runner.run_pipeline(self, self._options)
497
498 def __enter__(self):
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/direct/direct_runner.py in run_pipeline(self, pipeline, options)
128 runner = BundleBasedDirectRunner()
129
--> 130 return runner.run_pipeline(pipeline, options)
131
132
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in run_pipeline(self, pipeline, options)
553
554 self._latest_run_result = self.run_via_runner_api(
--> 555 pipeline.to_runner_api(default_environment=self._default_environment))
556 return self._latest_run_result
557
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in run_via_runner_api(self, pipeline_proto)
563 # TODO(pabloem, BEAM-7514): Create a watermark manager (that has access to
564 # the teststream (if any), and all the stages).
--> 565 return self.run_stages(stage_context, stages)
566
567 @contextlib.contextmanager
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in run_stages(self, stage_context, stages)
704 stage,
705 pcoll_buffers,
--> 706 stage_context.safe_coders)
707 metrics_by_stage[stage.name] = stage_results.process_bundle.metrics
708 monitoring_infos_by_stage[stage.name] = (
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in _run_stage(self, worker_handler_factory, pipeline_components, stage, pcoll_buffers, safe_coders)
1071 cache_token_generator=cache_token_generator)
1072
-> 1073 result, splits = bundle_manager.process_bundle(data_input, data_output)
1074
1075 def input_for(transform_id, input_id):
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in process_bundle(self, inputs, expected_outputs)
2332
2333 with UnboundedThreadPoolExecutor() as executor:
-> 2334 for result, split_result in executor.map(execute, part_inputs):
2335
2336 split_result_list += split_result
/usr/lib/python3.6/concurrent/futures/_base.py in result_iterator()
584 # Careful not to keep a reference to the popped future
585 if timeout is None:
--> 586 yield fs.pop().result()
587 else:
588 yield fs.pop().result(end_time - time.monotonic())
/usr/lib/python3.6/concurrent/futures/_base.py in result(self, timeout)
430 raise CancelledError()
431 elif self._state == FINISHED:
--> 432 return self.__get_result()
433 else:
434 raise TimeoutError()
/usr/lib/python3.6/concurrent/futures/_base.py in __get_result(self)
382 def __get_result(self):
383 if self._exception:
--> 384 raise self._exception
385 else:
386 return self._result
/usr/local/lib/python3.6/dist-packages/apache_beam/utils/thread_pool_executor.py in run(self)
42 # If the future wasn't cancelled, then attempt to execute it.
43 try:
---> 44 self._future.set_result(self._fn(*self._fn_args, **self._fn_kwargs))
45 except BaseException as exc:
46 # Even though Python 2 futures library has #set_exection(),
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in execute(part_map)
2329 self._registered,
2330 cache_token_generator=self._cache_token_generator)
-> 2331 return bundle_manager.process_bundle(part_map, expected_outputs)
2332
2333 with UnboundedThreadPoolExecutor() as executor:
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in process_bundle(self, inputs, expected_outputs)
2243 process_bundle_descriptor_id=self._bundle_descriptor.id,
2244 cache_tokens=[next(self._cache_token_generator)]))
-> 2245 result_future = self._worker_handler.control_conn.push(process_bundle_req)
2246
2247 split_results = [] # type: List[beam_fn_api_pb2.ProcessBundleSplitResponse]
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/portability/fn_api_runner.py in push(self, request)
1557 self._uid_counter += 1
1558 request.instruction_id = 'control_%s' % self._uid_counter
-> 1559 response = self.worker.do_instruction(request)
1560 return ControlFuture(request.instruction_id, response)
1561
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/sdk_worker.py in do_instruction(self, request)
413 # E.g. if register is set, this will call self.register(request.register))
414 return getattr(self, request_type)(
--> 415 getattr(request, request_type), request.instruction_id)
416 else:
417 raise NotImplementedError
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/sdk_worker.py in process_bundle(self, request, instruction_id)
448 with self.maybe_profile(instruction_id):
449 delayed_applications, requests_finalization = (
--> 450 bundle_processor.process_bundle(instruction_id))
451 monitoring_infos = bundle_processor.monitoring_infos()
452 monitoring_infos.extend(self.state_cache_metrics_fn())
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/bundle_processor.py in process_bundle(self, instruction_id)
837 for data in data_channel.input_elements(instruction_id,
838 expected_transforms):
--> 839 input_op_by_transform_id[data.transform_id].process_encoded(data.data)
840
841 # Finish all operations.
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/bundle_processor.py in process_encoded(self, encoded_windowed_values)
214 decoded_value = self.windowed_coder_impl.decode_from_stream(
215 input_stream, True)
--> 216 self.output(decoded_value)
217
218 def try_split(self, fraction_of_remainder, total_buffer_size):
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/operations.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.worker.operations.Operation.output()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/operations.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.worker.operations.Operation.output()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/operations.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.worker.operations.SingletonConsumerSet.receive()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/operations.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.worker.operations.DoOperation.process()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/worker/operations.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.worker.operations.DoOperation.process()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.DoFnRunner.process()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.DoFnRunner._reraise_augmented()
/usr/local/lib/python3.6/dist-packages/future/utils/__init__.py in raise_with_traceback(exc, traceback)
417 if traceback == Ellipsis:
418 _, _, traceback = sys.exc_info()
--> 419 raise exc.with_traceback(traceback)
420
421 else:
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.DoFnRunner.process()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.PerWindowInvoker.invoke_process()
/usr/local/lib/python3.6/dist-packages/apache_beam/runners/common.cpython-36m-x86_64-linux-gnu.so in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window()
/usr/local/lib/python3.6/dist-packages/apache_beam/io/iobase.py in process(self, element, init_result)
1080 for e in bundle[1]: # values
1081 writer.write(e)
-> 1082 return [window.TimestampedValue(writer.close(), timestamp.MAX_TIMESTAMP)]
1083
1084
/usr/local/lib/python3.6/dist-packages/apache_beam/io/filebasedsink.py in close(self)
421
422 def close(self):
--> 423 self.sink.close(self.temp_handle)
424 return self.temp_shard_path
/usr/local/lib/python3.6/dist-packages/apache_beam/io/parquetio.py in close(self, writer)
536 def close(self, writer):
537 if len(self._buffer[0]) > 0:
--> 538 self._flush_buffer()
539 if self._record_batches_byte_size > 0:
540 self._write_batches(writer)
/usr/local/lib/python3.6/dist-packages/apache_beam/io/parquetio.py in _flush_buffer(self)
568 for x in arrays:
569 for b in x.buffers():
--> 570 size = size + b.size
571 self._record_batches_byte_size = self._record_batches_byte_size + size
AttributeError: 'NoneType' object has no attribute 'size' [while running 'train/Save to parquet/Write/WriteImpl/WriteBundles']
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/187/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/187/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/186
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/186/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/186/comments
|
https://api.github.com/repos/huggingface/datasets/issues/186/events
|
https://github.com/huggingface/datasets/issues/186
| 623,595,180
|
MDU6SXNzdWU2MjM1OTUxODA=
| 186
|
Weird-ish: Not creating unique caches for different phases
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1668462?v=4",
"events_url": "https://api.github.com/users/zphang/events{/privacy}",
"followers_url": "https://api.github.com/users/zphang/followers",
"following_url": "https://api.github.com/users/zphang/following{/other_user}",
"gists_url": "https://api.github.com/users/zphang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zphang",
"id": 1668462,
"login": "zphang",
"node_id": "MDQ6VXNlcjE2Njg0NjI=",
"organizations_url": "https://api.github.com/users/zphang/orgs",
"received_events_url": "https://api.github.com/users/zphang/received_events",
"repos_url": "https://api.github.com/users/zphang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zphang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zphang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zphang",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-05-23 06:40:58+00:00
|
2020-05-23 20:22:18+00:00
|
2020-05-23 20:22:17+00:00
|
NONE
| null | null | null | null |
Sample code:
```python
import nlp
dataset = nlp.load_dataset('boolq')
def func1(x):
return x
def func2(x):
return None
train_output = dataset["train"].map(func1)
valid_output = dataset["validation"].map(func1)
print()
print(len(train_output), len(valid_output))
# Output: 9427 9427
```
The map method in both cases seem to be pointing to the same cache, so the latter call based on the validation data will return the processed train data cache.
What's weird is that the following doesn't seem to be an issue:
```python
train_output = dataset["train"].map(func2)
valid_output = dataset["validation"].map(func2)
print()
print(len(train_output), len(valid_output))
# 9427 3270
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1668462?v=4",
"events_url": "https://api.github.com/users/zphang/events{/privacy}",
"followers_url": "https://api.github.com/users/zphang/followers",
"following_url": "https://api.github.com/users/zphang/following{/other_user}",
"gists_url": "https://api.github.com/users/zphang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zphang",
"id": 1668462,
"login": "zphang",
"node_id": "MDQ6VXNlcjE2Njg0NjI=",
"organizations_url": "https://api.github.com/users/zphang/orgs",
"received_events_url": "https://api.github.com/users/zphang/received_events",
"repos_url": "https://api.github.com/users/zphang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zphang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zphang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zphang",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/186/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/186/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/185
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/185/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/185/comments
|
https://api.github.com/repos/huggingface/datasets/issues/185/events
|
https://github.com/huggingface/datasets/pull/185
| 623,172,484
|
MDExOlB1bGxSZXF1ZXN0NDIxODkxNjY2
| 185
|
[Commands] In-detail instructions to create dummy data folder
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-05-22 12:26:25+00:00
|
2020-05-22 14:06:35+00:00
|
2020-05-22 14:06:34+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/185.diff",
"html_url": "https://github.com/huggingface/datasets/pull/185",
"merged_at": "2020-05-22T14:06:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/185.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/185"
}
|
### Dummy data command
This PR adds a new command `python nlp-cli dummy_data <path_to_dataset_folder>` that gives in-detail instructions on how to add the dummy data files.
It would be great if you can try it out by moving the current dummy_data folder of any dataset in `./datasets` with `mv datasets/<dataset_script>/dummy_data datasets/<dataset_name>/dummy_data_copy` and running the command `python nlp-cli dummy_data ./datasets/<dataset_name>` to see if you like the instructions.
### CONTRIBUTING.md
Also the CONTRIBUTING.md is made cleaner including a new section on "How to add a dataset".
### Current PRs
It would be nice if we can try out if this command helps current PRs, *e.g.* #169 to add a dataset. I comment on those PRs.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/185/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/185/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/184
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/184/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/184/comments
|
https://api.github.com/repos/huggingface/datasets/issues/184/events
|
https://github.com/huggingface/datasets/pull/184
| 623,120,929
|
MDExOlB1bGxSZXF1ZXN0NDIxODQ5MTQ3
| 184
|
Use IndexError instead of ValueError when index out of range
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-22 10:43:42+00:00
|
2020-05-28 08:31:18+00:00
|
2020-05-28 08:31:18+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/184.diff",
"html_url": "https://github.com/huggingface/datasets/pull/184",
"merged_at": "2020-05-28T08:31:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/184.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/184"
}
|
**`default __iter__ needs IndexError`**.
When I want to create a wrapper of arrow dataset to adapt to fastai,
I don't know how to initialize it, so I didn't use inheritance but use object composition.
I wrote sth like this.
```
clas HF_dataset():
def __init__(self, arrow_dataset):
self.dset = arrow_dataset
def __getitem__(self, i):
return self.my_get_item(self.dset)
```
But `for sample in my_dataset:` gave me `ValueError(f"Index ({key}) outside of table length ({self._data.num_rows}).")` . This is because default `__iter__` will stop when it catched `IndexError`.
You can also see my [work](https://github.com/richardyy1188/Pretrain-MLM-and-finetune-on-GLUE-with-fastai/blob/master/GLUE_with_fastai.ipynb) that uses fastai2 to show/load batches from huggingface/nlp GLUE datasets
So I hope we can use `IndexError` instead to let other people who want to wrap it for any purpose won't be caught by this caveat.
BTW, I super appreciate your work, both transformers and nlp save my life. 💖💖💖💖💖💖💖
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/184/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/184/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/183
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/183/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/183/comments
|
https://api.github.com/repos/huggingface/datasets/issues/183/events
|
https://github.com/huggingface/datasets/issues/183
| 623,054,270
|
MDU6SXNzdWU2MjMwNTQyNzA=
| 183
|
[Bug] labels of glue/ax are all -1
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null | 2
|
2020-05-22 08:43:36+00:00
|
2020-05-22 22:14:05+00:00
|
2020-05-22 22:14:05+00:00
|
CONTRIBUTOR
| null | null | null | null |
```
ax = nlp.load_dataset('glue', 'ax')
for i in range(30): print(ax['test'][i]['label'], end=', ')
```
```
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/183/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/183/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/182
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/182/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/182/comments
|
https://api.github.com/repos/huggingface/datasets/issues/182/events
|
https://github.com/huggingface/datasets/pull/182
| 622,646,770
|
MDExOlB1bGxSZXF1ZXN0NDIxNDcxMjg4
| 182
|
Update newsroom.py
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/3289873?v=4",
"events_url": "https://api.github.com/users/yoavartzi/events{/privacy}",
"followers_url": "https://api.github.com/users/yoavartzi/followers",
"following_url": "https://api.github.com/users/yoavartzi/following{/other_user}",
"gists_url": "https://api.github.com/users/yoavartzi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yoavartzi",
"id": 3289873,
"login": "yoavartzi",
"node_id": "MDQ6VXNlcjMyODk4NzM=",
"organizations_url": "https://api.github.com/users/yoavartzi/orgs",
"received_events_url": "https://api.github.com/users/yoavartzi/received_events",
"repos_url": "https://api.github.com/users/yoavartzi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yoavartzi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yoavartzi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yoavartzi",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
] | null | 0
|
2020-05-21 17:07:43+00:00
|
2020-05-22 16:38:23+00:00
|
2020-05-22 16:38:23+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/182.diff",
"html_url": "https://github.com/huggingface/datasets/pull/182",
"merged_at": "2020-05-22T16:38:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/182.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/182"
}
|
Updated the URL for Newsroom download so it's more robust to future changes.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/182/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/182/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/181
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/181/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/181/comments
|
https://api.github.com/repos/huggingface/datasets/issues/181/events
|
https://github.com/huggingface/datasets/issues/181
| 622,634,420
|
MDU6SXNzdWU2MjI2MzQ0MjA=
| 181
|
Cannot upload my own dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/3155646?v=4",
"events_url": "https://api.github.com/users/korakot/events{/privacy}",
"followers_url": "https://api.github.com/users/korakot/followers",
"following_url": "https://api.github.com/users/korakot/following{/other_user}",
"gists_url": "https://api.github.com/users/korakot/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/korakot",
"id": 3155646,
"login": "korakot",
"node_id": "MDQ6VXNlcjMxNTU2NDY=",
"organizations_url": "https://api.github.com/users/korakot/orgs",
"received_events_url": "https://api.github.com/users/korakot/received_events",
"repos_url": "https://api.github.com/users/korakot/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/korakot/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/korakot/subscriptions",
"type": "User",
"url": "https://api.github.com/users/korakot",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 6
|
2020-05-21 16:45:52+00:00
|
2020-06-18 22:14:42+00:00
|
2020-06-18 22:14:42+00:00
|
NONE
| null | null | null | null |
I look into `nlp-cli` and `user.py` to learn how to upload my own data.
It is supposed to work like this
- Register to get username, password at huggingface.co
- `nlp-cli login` and type username, passworld
- I have a single file to upload at `./ttc/ttc_freq_extra.csv`
- `nlp-cli upload ttc/ttc_freq_extra.csv`
But I got this error.
```
2020-05-21 16:33:52.722464: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
About to upload file /content/ttc/ttc_freq_extra.csv to S3 under filename ttc/ttc_freq_extra.csv and namespace korakot
Proceed? [Y/n] y
Uploading... This might take a while if files are large
Traceback (most recent call last):
File "/usr/local/bin/nlp-cli", line 33, in <module>
service.run()
File "/usr/local/lib/python3.6/dist-packages/nlp/commands/user.py", line 234, in run
token=token, filename=filename, filepath=filepath, organization=self.args.organization
File "/usr/local/lib/python3.6/dist-packages/nlp/hf_api.py", line 141, in presign_and_upload
urls = self.presign(token, filename=filename, organization=organization)
File "/usr/local/lib/python3.6/dist-packages/nlp/hf_api.py", line 132, in presign
return PresignedUrl(**d)
TypeError: __init__() got an unexpected keyword argument 'cdn'
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/181/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/181/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/180
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/180/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/180/comments
|
https://api.github.com/repos/huggingface/datasets/issues/180/events
|
https://github.com/huggingface/datasets/pull/180
| 622,556,861
|
MDExOlB1bGxSZXF1ZXN0NDIxMzk5Nzg2
| 180
|
Add hall of fame
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/821155?v=4",
"events_url": "https://api.github.com/users/clmnt/events{/privacy}",
"followers_url": "https://api.github.com/users/clmnt/followers",
"following_url": "https://api.github.com/users/clmnt/following{/other_user}",
"gists_url": "https://api.github.com/users/clmnt/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/clmnt",
"id": 821155,
"login": "clmnt",
"node_id": "MDQ6VXNlcjgyMTE1NQ==",
"organizations_url": "https://api.github.com/users/clmnt/orgs",
"received_events_url": "https://api.github.com/users/clmnt/received_events",
"repos_url": "https://api.github.com/users/clmnt/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/clmnt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/clmnt/subscriptions",
"type": "User",
"url": "https://api.github.com/users/clmnt",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-21 14:53:48+00:00
|
2020-05-22 16:35:16+00:00
|
2020-05-22 16:35:14+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/180.diff",
"html_url": "https://github.com/huggingface/datasets/pull/180",
"merged_at": "2020-05-22T16:35:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/180.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/180"
}
|
powered by https://github.com/sourcerer-io/hall-of-fame
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/180/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/180/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/179
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/179/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/179/comments
|
https://api.github.com/repos/huggingface/datasets/issues/179/events
|
https://github.com/huggingface/datasets/issues/179
| 622,525,410
|
MDU6SXNzdWU2MjI1MjU0MTA=
| 179
|
[Feature request] separate split name and split instructions
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null | 2
|
2020-05-21 14:10:51+00:00
|
2020-05-22 13:31:08+00:00
|
2020-05-22 13:31:07+00:00
|
MEMBER
| null | null | null | null |
Currently, the name of an nlp.NamedSplit is parsed in arrow_reader.py and used as the instruction.
This makes it impossible to have several training sets, which can occur when:
- A dataset corresponds to a collection of sub-datasets
- A dataset was built in stages, adding new examples at each stage
Would it be possible to have two separate fields in the Split class, a name /instruction and a unique ID that is used as the key in the builder's split_dict ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/179/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/179/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/178
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/178/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/178/comments
|
https://api.github.com/repos/huggingface/datasets/issues/178/events
|
https://github.com/huggingface/datasets/pull/178
| 621,979,849
|
MDExOlB1bGxSZXF1ZXN0NDIwOTMyMDI5
| 178
|
[Manual data] improve error message for manual data in general
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-20 18:10:45+00:00
|
2020-05-20 18:18:52+00:00
|
2020-05-20 18:18:50+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/178.diff",
"html_url": "https://github.com/huggingface/datasets/pull/178",
"merged_at": "2020-05-20T18:18:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/178.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/178"
}
|
`nlp.load("xsum")` now leads to the following error message:

I guess the manual download instructions for `xsum` can also be improved.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/178/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/178/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/177
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/177/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/177/comments
|
https://api.github.com/repos/huggingface/datasets/issues/177/events
|
https://github.com/huggingface/datasets/pull/177
| 621,975,368
|
MDExOlB1bGxSZXF1ZXN0NDIwOTI4MzE0
| 177
|
Xsum manual download instruction
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-20 18:02:41+00:00
|
2020-05-20 18:16:50+00:00
|
2020-05-20 18:16:49+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/177.diff",
"html_url": "https://github.com/huggingface/datasets/pull/177",
"merged_at": "2020-05-20T18:16:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/177.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/177"
}
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/177/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/177/timeline
| null | null | null | null | true
|
|
https://api.github.com/repos/huggingface/datasets/issues/176
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/176/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/176/comments
|
https://api.github.com/repos/huggingface/datasets/issues/176/events
|
https://github.com/huggingface/datasets/pull/176
| 621,934,638
|
MDExOlB1bGxSZXF1ZXN0NDIwODkzNDky
| 176
|
[Tests] Refactor MockDownloadManager
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-20 17:07:36+00:00
|
2020-05-20 18:17:19+00:00
|
2020-05-20 18:17:18+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/176.diff",
"html_url": "https://github.com/huggingface/datasets/pull/176",
"merged_at": "2020-05-20T18:17:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/176.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/176"
}
|
Clean mock download manager class.
The print function was not of much help I think.
We should think about adding a command that creates the dummy folder structure for the user.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/176/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/176/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/175
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/175/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/175/comments
|
https://api.github.com/repos/huggingface/datasets/issues/175/events
|
https://github.com/huggingface/datasets/issues/175
| 621,929,428
|
MDU6SXNzdWU2MjE5Mjk0Mjg=
| 175
|
[Manual data dir] Error message: nlp.load_dataset('xsum') -> TypeError
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "https://api.github.com/users/sshleifer/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sshleifer",
"id": 6045025,
"login": "sshleifer",
"node_id": "MDQ6VXNlcjYwNDUwMjU=",
"organizations_url": "https://api.github.com/users/sshleifer/orgs",
"received_events_url": "https://api.github.com/users/sshleifer/received_events",
"repos_url": "https://api.github.com/users/sshleifer/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sshleifer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sshleifer/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sshleifer",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-20 17:00:32+00:00
|
2020-05-20 18:18:50+00:00
|
2020-05-20 18:18:50+00:00
|
CONTRIBUTOR
| null | null | null | null |
v 0.1.0 from pip
```python
import nlp
xsum = nlp.load_dataset('xsum')
```
Issue is `dl_manager.manual_dir`is `None`
```python
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-42-8a32f066f3bd> in <module>
----> 1 xsum = nlp.load_dataset('xsum')
~/miniconda3/envs/nb/lib/python3.7/site-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
515 download_mode=download_mode,
516 ignore_verifications=ignore_verifications,
--> 517 save_infos=save_infos,
518 )
519
~/miniconda3/envs/nb/lib/python3.7/site-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, dl_manager, **download_and_prepare_kwargs)
361 verify_infos = not save_infos and not ignore_verifications
362 self._download_and_prepare(
--> 363 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
364 )
365 # Sync info
~/miniconda3/envs/nb/lib/python3.7/site-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
397 split_dict = SplitDict(dataset_name=self.name)
398 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 399 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
400 # Checksums verification
401 if verify_infos:
~/miniconda3/envs/nb/lib/python3.7/site-packages/nlp/datasets/xsum/5c5fca23aaaa469b7a1c6f095cf12f90d7ab99bcc0d86f689a74fd62634a1472/xsum.py in _split_generators(self, dl_manager)
102 with open(dl_path, "r") as json_file:
103 split_ids = json.load(json_file)
--> 104 downloaded_path = os.path.join(dl_manager.manual_dir, "xsum-extracts-from-downloads")
105 return [
106 nlp.SplitGenerator(
~/miniconda3/envs/nb/lib/python3.7/posixpath.py in join(a, *p)
78 will be discarded. An empty last part will result in a path that
79 ends with a separator."""
---> 80 a = os.fspath(a)
81 sep = _get_sep(a)
82 path = a
TypeError: expected str, bytes or os.PathLike object, not NoneType
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/175/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/175/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/174
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/174/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/174/comments
|
https://api.github.com/repos/huggingface/datasets/issues/174/events
|
https://github.com/huggingface/datasets/issues/174
| 621,928,403
|
MDU6SXNzdWU2MjE5Mjg0MDM=
| 174
|
nlp.load_dataset('xsum') -> TypeError
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "https://api.github.com/users/sshleifer/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sshleifer",
"id": 6045025,
"login": "sshleifer",
"node_id": "MDQ6VXNlcjYwNDUwMjU=",
"organizations_url": "https://api.github.com/users/sshleifer/orgs",
"received_events_url": "https://api.github.com/users/sshleifer/received_events",
"repos_url": "https://api.github.com/users/sshleifer/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sshleifer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sshleifer/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sshleifer",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-20 16:59:09+00:00
|
2020-05-20 17:43:46+00:00
|
2020-05-20 17:43:46+00:00
|
CONTRIBUTOR
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "https://api.github.com/users/sshleifer/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sshleifer",
"id": 6045025,
"login": "sshleifer",
"node_id": "MDQ6VXNlcjYwNDUwMjU=",
"organizations_url": "https://api.github.com/users/sshleifer/orgs",
"received_events_url": "https://api.github.com/users/sshleifer/received_events",
"repos_url": "https://api.github.com/users/sshleifer/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sshleifer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sshleifer/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sshleifer",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/174/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/174/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
|
https://api.github.com/repos/huggingface/datasets/issues/173
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/173/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/173/comments
|
https://api.github.com/repos/huggingface/datasets/issues/173/events
|
https://github.com/huggingface/datasets/pull/173
| 621,764,932
|
MDExOlB1bGxSZXF1ZXN0NDIwNzUyNzQy
| 173
|
Rm extracted test dirs
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-05-20 13:30:48+00:00
|
2020-05-22 16:34:36+00:00
|
2020-05-22 16:34:35+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/173.diff",
"html_url": "https://github.com/huggingface/datasets/pull/173",
"merged_at": "2020-05-22T16:34:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/173.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/173"
}
|
All the dummy data used for tests were duplicated. For each dataset, we had one zip file but also its extracted directory. I removed all these directories
Furthermore instead of extracting next to the dummy_data.zip file, we extract in the temp `cached_dir` used for tests, so that all the extracted directories get removed after testing.
Finally there was a bug in the `mock_download_manager` that would let it create directories with invalid names, as in #172. I fixed that by encoding url arguments. I had to rename the dummy data for `scientific_papers` and `cnn_dailymail` (the aws tests don't pass for those 2 in this PR, but they will once aws will be synced, as the local ones do)
Let me know if it sounds good to you @patrickvonplaten . I'm still not entirely familiar with the mock downloader
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/173/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/173/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/172
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/172/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/172/comments
|
https://api.github.com/repos/huggingface/datasets/issues/172/events
|
https://github.com/huggingface/datasets/issues/172
| 621,377,386
|
MDU6SXNzdWU2MjEzNzczODY=
| 172
|
Clone not working on Windows environment
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/51091425?v=4",
"events_url": "https://api.github.com/users/codehunk628/events{/privacy}",
"followers_url": "https://api.github.com/users/codehunk628/followers",
"following_url": "https://api.github.com/users/codehunk628/following{/other_user}",
"gists_url": "https://api.github.com/users/codehunk628/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/codehunk628",
"id": 51091425,
"login": "codehunk628",
"node_id": "MDQ6VXNlcjUxMDkxNDI1",
"organizations_url": "https://api.github.com/users/codehunk628/orgs",
"received_events_url": "https://api.github.com/users/codehunk628/received_events",
"repos_url": "https://api.github.com/users/codehunk628/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/codehunk628/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/codehunk628/subscriptions",
"type": "User",
"url": "https://api.github.com/users/codehunk628",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null | 2
|
2020-05-20 00:45:14+00:00
|
2020-05-23 12:49:13+00:00
|
2020-05-23 11:27:52+00:00
|
CONTRIBUTOR
| null | null | null | null |
Cloning in a windows environment is not working because of use of special character '?' in folder name ..
Please consider changing the folder name ....
Reference to folder -
nlp/datasets/cnn_dailymail/dummy/3.0.0/3.0.0/dummy_data-zip-extracted/dummy_data/uc?export=download&id=0BwmD_VLjROrfM1BxdkxVaTY2bWs/dailymail/stories/
error log:
fatal: cannot create directory at 'datasets/cnn_dailymail/dummy/3.0.0/3.0.0/dummy_data-zip-extracted/dummy_data/uc?export=download&id=0BwmD_VLjROrfM1BxdkxVaTY2bWs': Invalid argument
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/172/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/172/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/171
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/171/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/171/comments
|
https://api.github.com/repos/huggingface/datasets/issues/171/events
|
https://github.com/huggingface/datasets/pull/171
| 621,199,128
|
MDExOlB1bGxSZXF1ZXN0NDIwMjk0ODM0
| 171
|
fix squad metric format
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 5
|
2020-05-19 18:37:36+00:00
|
2020-05-22 13:36:50+00:00
|
2020-05-22 13:36:48+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/171.diff",
"html_url": "https://github.com/huggingface/datasets/pull/171",
"merged_at": "2020-05-22T13:36:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/171.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/171"
}
|
The format of the squad metric was wrong.
This should fix #143
I tested with
```python3
predictions = [
{'id': '56be4db0acb8001400a502ec', 'prediction_text': 'Denver Broncos'}
]
references = [
{'answers': [{'text': 'Denver Broncos'}], 'id': '56be4db0acb8001400a502ec'}
]
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/171/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/171/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/170
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/170/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/170/comments
|
https://api.github.com/repos/huggingface/datasets/issues/170/events
|
https://github.com/huggingface/datasets/pull/170
| 621,119,747
|
MDExOlB1bGxSZXF1ZXN0NDIwMjMwMDIx
| 170
|
Rename anli dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-19 16:26:57+00:00
|
2020-05-20 12:23:09+00:00
|
2020-05-20 12:23:08+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/170.diff",
"html_url": "https://github.com/huggingface/datasets/pull/170",
"merged_at": "2020-05-20T12:23:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/170.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/170"
}
|
What we have now as the `anli` dataset is actually the αNLI dataset from the ART challenge dataset. This name is confusing because `anli` is also the name of adversarial NLI (see [https://github.com/facebookresearch/anli](https://github.com/facebookresearch/anli)).
I renamed the current `anli` dataset by `art`.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/170/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/170/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/169
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/169/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/169/comments
|
https://api.github.com/repos/huggingface/datasets/issues/169/events
|
https://github.com/huggingface/datasets/pull/169
| 621,099,682
|
MDExOlB1bGxSZXF1ZXN0NDIwMjE1NDkw
| 169
|
Adding Qanta (Quizbowl) Dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1382460?v=4",
"events_url": "https://api.github.com/users/EntilZha/events{/privacy}",
"followers_url": "https://api.github.com/users/EntilZha/followers",
"following_url": "https://api.github.com/users/EntilZha/following{/other_user}",
"gists_url": "https://api.github.com/users/EntilZha/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/EntilZha",
"id": 1382460,
"login": "EntilZha",
"node_id": "MDQ6VXNlcjEzODI0NjA=",
"organizations_url": "https://api.github.com/users/EntilZha/orgs",
"received_events_url": "https://api.github.com/users/EntilZha/received_events",
"repos_url": "https://api.github.com/users/EntilZha/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/EntilZha/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/EntilZha/subscriptions",
"type": "User",
"url": "https://api.github.com/users/EntilZha",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
] | null | 5
|
2020-05-19 16:03:01+00:00
|
2020-05-26 12:52:31+00:00
|
2020-05-26 12:52:31+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/169.diff",
"html_url": "https://github.com/huggingface/datasets/pull/169",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/169.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/169"
}
|
This PR adds the qanta question answering datasets from [Quizbowl: The Case for Incremental Question Answering](https://arxiv.org/abs/1904.04792) and [Trick Me If You Can: Human-in-the-loop Generation of Adversarial Question Answering Examples](https://www.aclweb.org/anthology/Q19-1029/) (adversarial fold)
This partially continues a discussion around fixing dummy data from https://github.com/huggingface/nlp/issues/161
I ran the following code to double check that it works and did some sanity checks on the output. The majority of the code itself is from our `allennlp` version of the dataset reader.
```python
import nlp
# Default is full question
data = nlp.load_dataset('./datasets/qanta')
# Four configs
# Primarily useful for training
data = nlp.load_dataset('./datasets/qanta', 'mode=sentences,char_skip=25')
# Primarily used in evaluation
data = nlp.load_dataset('./datasets/qanta', 'mode=first,char_skip=25')
data = nlp.load_dataset('./datasets/qanta', 'mode=full,char_skip=25')
# Primarily useful in evaluation and "live" play
data = nlp.load_dataset('./datasets/qanta', 'mode=runs,char_skip=25')
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/169/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/169/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/168
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/168/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/168/comments
|
https://api.github.com/repos/huggingface/datasets/issues/168/events
|
https://github.com/huggingface/datasets/issues/168
| 620,959,819
|
MDU6SXNzdWU2MjA5NTk4MTk=
| 168
|
Loading 'wikitext' dataset fails
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/25987633?v=4",
"events_url": "https://api.github.com/users/itay1itzhak/events{/privacy}",
"followers_url": "https://api.github.com/users/itay1itzhak/followers",
"following_url": "https://api.github.com/users/itay1itzhak/following{/other_user}",
"gists_url": "https://api.github.com/users/itay1itzhak/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/itay1itzhak",
"id": 25987633,
"login": "itay1itzhak",
"node_id": "MDQ6VXNlcjI1OTg3NjMz",
"organizations_url": "https://api.github.com/users/itay1itzhak/orgs",
"received_events_url": "https://api.github.com/users/itay1itzhak/received_events",
"repos_url": "https://api.github.com/users/itay1itzhak/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/itay1itzhak/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/itay1itzhak/subscriptions",
"type": "User",
"url": "https://api.github.com/users/itay1itzhak",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 6
|
2020-05-19 13:04:29+00:00
|
2020-05-26 21:46:52+00:00
|
2020-05-26 21:46:52+00:00
|
NONE
| null | null | null | null |
Loading the 'wikitext' dataset fails with Attribute error:
Code to reproduce (From example notebook):
import nlp
wikitext_dataset = nlp.load_dataset('wikitext')
Error:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-17-d5d9df94b13c> in <module>()
11
12 # Load a dataset and print the first examples in the training set
---> 13 wikitext_dataset = nlp.load_dataset('wikitext')
14 print(wikitext_dataset['train'][0])
6 frames
/usr/local/lib/python3.6/dist-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
518 download_mode=download_mode,
519 ignore_verifications=ignore_verifications,
--> 520 save_infos=save_infos,
521 )
522
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, dl_manager, **download_and_prepare_kwargs)
363 verify_infos = not save_infos and not ignore_verifications
364 self._download_and_prepare(
--> 365 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
366 )
367 # Sync info
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
416 try:
417 # Prepare split will record examples associated to the split
--> 418 self._prepare_split(split_generator, **prepare_split_kwargs)
419 except OSError:
420 raise OSError("Cannot find data file. " + (self.MANUAL_DOWNLOAD_INSTRUCTIONS or ""))
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _prepare_split(self, split_generator)
594 example = self.info.features.encode_example(record)
595 writer.write(example)
--> 596 num_examples, num_bytes = writer.finalize()
597
598 assert num_examples == num_examples, f"Expected to write {split_info.num_examples} but wrote {num_examples}"
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in finalize(self, close_stream)
173 def finalize(self, close_stream=True):
174 if self.pa_writer is not None:
--> 175 self.write_on_file()
176 self.pa_writer.close()
177 if close_stream:
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in write_on_file(self)
124 else:
125 # All good
--> 126 self._write_array_on_file(pa_array)
127 self.current_rows = []
128
/usr/local/lib/python3.6/dist-packages/nlp/arrow_writer.py in _write_array_on_file(self, pa_array)
93 def _write_array_on_file(self, pa_array):
94 """Write a PyArrow Array"""
---> 95 pa_batch = pa.RecordBatch.from_struct_array(pa_array)
96 self._num_bytes += pa_array.nbytes
97 self.pa_writer.write_batch(pa_batch)
AttributeError: type object 'pyarrow.lib.RecordBatch' has no attribute 'from_struct_array'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/168/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/168/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/167
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/167/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/167/comments
|
https://api.github.com/repos/huggingface/datasets/issues/167/events
|
https://github.com/huggingface/datasets/pull/167
| 620,908,786
|
MDExOlB1bGxSZXF1ZXN0NDIwMDY0NDMw
| 167
|
[Tests] refactor tests
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-05-19 11:43:32+00:00
|
2020-05-19 16:17:12+00:00
|
2020-05-19 16:17:10+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/167.diff",
"html_url": "https://github.com/huggingface/datasets/pull/167",
"merged_at": "2020-05-19T16:17:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/167.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/167"
}
|
This PR separates AWS and Local tests to remove these ugly statements in the script:
```python
if "/" not in dataset_name:
logging.info("Skip {} because it is a canonical dataset")
return
```
To run a `aws` test, one should now run the following command:
```python
pytest -s tests/test_dataset_common.py::AWSDatasetTest::test_builder_class_wmt14
```
The same `local` test, can be run with:
```python
pytest -s tests/test_dataset_common.py::LocalDatasetTest::test_builder_class_wmt14
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/167/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/167/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/166
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/166/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/166/comments
|
https://api.github.com/repos/huggingface/datasets/issues/166/events
|
https://github.com/huggingface/datasets/issues/166
| 620,850,218
|
MDU6SXNzdWU2MjA4NTAyMTg=
| 166
|
Add a method to shuffle a dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] |
closed
| false
| null |
[] | null | 4
|
2020-05-19 10:08:46+00:00
|
2020-06-23 15:07:33+00:00
|
2020-06-23 15:07:32+00:00
|
MEMBER
| null | null | null | null |
Could maybe be a `dataset.shuffle(generator=None, seed=None)` signature method.
Also, we could maybe have a clear indication of which method modify in-place and which methods return/cache a modified dataset. I kinda like torch conversion of having an underscore suffix for all the methods which modify a dataset in-place. What do you think?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/166/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/166/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/165
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/165/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/165/comments
|
https://api.github.com/repos/huggingface/datasets/issues/165/events
|
https://github.com/huggingface/datasets/issues/165
| 620,758,221
|
MDU6SXNzdWU2MjA3NTgyMjE=
| 165
|
ANLI
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6024930?v=4",
"events_url": "https://api.github.com/users/douwekiela/events{/privacy}",
"followers_url": "https://api.github.com/users/douwekiela/followers",
"following_url": "https://api.github.com/users/douwekiela/following{/other_user}",
"gists_url": "https://api.github.com/users/douwekiela/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/douwekiela",
"id": 6024930,
"login": "douwekiela",
"node_id": "MDQ6VXNlcjYwMjQ5MzA=",
"organizations_url": "https://api.github.com/users/douwekiela/orgs",
"received_events_url": "https://api.github.com/users/douwekiela/received_events",
"repos_url": "https://api.github.com/users/douwekiela/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/douwekiela/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/douwekiela/subscriptions",
"type": "User",
"url": "https://api.github.com/users/douwekiela",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-19 07:50:57+00:00
|
2020-05-20 12:23:07+00:00
|
2020-05-20 12:23:07+00:00
|
NONE
| null | null | null | null |
Can I recommend the following:
For ANLI, use https://github.com/facebookresearch/anli. As that paper says, "Our dataset is not
to be confused with abductive NLI (Bhagavatula et al., 2019), which calls itself αNLI, or ART.".
Indeed, the paper cited under what is currently called anli says in the abstract "We introduce a challenge dataset, ART".
The current naming will confuse people :)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/165/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/165/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/164
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/164/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/164/comments
|
https://api.github.com/repos/huggingface/datasets/issues/164/events
|
https://github.com/huggingface/datasets/issues/164
| 620,540,250
|
MDU6SXNzdWU2MjA1NDAyNTA=
| 164
|
Add Spanish POR and NER Datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/3653789?v=4",
"events_url": "https://api.github.com/users/mrm8488/events{/privacy}",
"followers_url": "https://api.github.com/users/mrm8488/followers",
"following_url": "https://api.github.com/users/mrm8488/following{/other_user}",
"gists_url": "https://api.github.com/users/mrm8488/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mrm8488",
"id": 3653789,
"login": "mrm8488",
"node_id": "MDQ6VXNlcjM2NTM3ODk=",
"organizations_url": "https://api.github.com/users/mrm8488/orgs",
"received_events_url": "https://api.github.com/users/mrm8488/received_events",
"repos_url": "https://api.github.com/users/mrm8488/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mrm8488/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mrm8488/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mrm8488",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
closed
| false
| null |
[] | null | 2
|
2020-05-18 22:18:21+00:00
|
2020-05-25 16:28:45+00:00
|
2020-05-25 16:28:45+00:00
|
CONTRIBUTOR
| null | null | null | null |
Hi guys,
In order to cover multilingual support a little step could be adding standard Datasets used for Spanish NER and POS tasks.
I can provide it in raw and preprocessed formats.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/164/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/164/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/163
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/163/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/163/comments
|
https://api.github.com/repos/huggingface/datasets/issues/163/events
|
https://github.com/huggingface/datasets/issues/163
| 620,534,307
|
MDU6SXNzdWU2MjA1MzQzMDc=
| 163
|
[Feature request] Add cos-e v1.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sarahwie",
"id": 8027676,
"login": "sarahwie",
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sarahwie",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
closed
| false
| null |
[] | null | 10
|
2020-05-18 22:05:26+00:00
|
2020-06-16 23:15:25+00:00
|
2020-06-16 18:52:06+00:00
|
NONE
| null | null | null | null |
I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/salesforce/cos-e/issues/2) [issues](https://arxiv.org/pdf/2004.14546.pdf).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sarahwie",
"id": 8027676,
"login": "sarahwie",
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sarahwie",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/163/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/163/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/162
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/162/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/162/comments
|
https://api.github.com/repos/huggingface/datasets/issues/162/events
|
https://github.com/huggingface/datasets/pull/162
| 620,513,554
|
MDExOlB1bGxSZXF1ZXN0NDE5NzQ4Mzky
| 162
|
fix prev files hash in map
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-05-18 21:20:51+00:00
|
2020-05-18 21:36:21+00:00
|
2020-05-18 21:36:20+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/162.diff",
"html_url": "https://github.com/huggingface/datasets/pull/162",
"merged_at": "2020-05-18T21:36:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/162.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/162"
}
|
Fix the `.map` issue in #160.
This makes sure it takes the previous files when computing the hash.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/162/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/162/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/161
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/161/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/161/comments
|
https://api.github.com/repos/huggingface/datasets/issues/161/events
|
https://github.com/huggingface/datasets/issues/161
| 620,487,535
|
MDU6SXNzdWU2MjA0ODc1MzU=
| 161
|
Discussion on version identifier & MockDataLoaderManager for test data
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1382460?v=4",
"events_url": "https://api.github.com/users/EntilZha/events{/privacy}",
"followers_url": "https://api.github.com/users/EntilZha/followers",
"following_url": "https://api.github.com/users/EntilZha/following{/other_user}",
"gists_url": "https://api.github.com/users/EntilZha/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/EntilZha",
"id": 1382460,
"login": "EntilZha",
"node_id": "MDQ6VXNlcjEzODI0NjA=",
"organizations_url": "https://api.github.com/users/EntilZha/orgs",
"received_events_url": "https://api.github.com/users/EntilZha/received_events",
"repos_url": "https://api.github.com/users/EntilZha/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/EntilZha/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/EntilZha/subscriptions",
"type": "User",
"url": "https://api.github.com/users/EntilZha",
"user_view_type": "public"
}
|
[
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] |
open
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
] | null | 12
|
2020-05-18 20:31:30+00:00
|
2020-05-24 18:10:03+00:00
|
NaT
|
CONTRIBUTOR
| null | null | null | null |
Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_localmydatasetname` triggers the error. If I can get something to work, I can include it in my data PR once I'm done.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/161/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/161/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/160
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/160/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/160/comments
|
https://api.github.com/repos/huggingface/datasets/issues/160/events
|
https://github.com/huggingface/datasets/issues/160
| 620,448,236
|
MDU6SXNzdWU2MjA0NDgyMzY=
| 160
|
caching in map causes same result to be returned for train, validation and test
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/247881?v=4",
"events_url": "https://api.github.com/users/dpressel/events{/privacy}",
"followers_url": "https://api.github.com/users/dpressel/followers",
"following_url": "https://api.github.com/users/dpressel/following{/other_user}",
"gists_url": "https://api.github.com/users/dpressel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dpressel",
"id": 247881,
"login": "dpressel",
"node_id": "MDQ6VXNlcjI0Nzg4MQ==",
"organizations_url": "https://api.github.com/users/dpressel/orgs",
"received_events_url": "https://api.github.com/users/dpressel/received_events",
"repos_url": "https://api.github.com/users/dpressel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dpressel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dpressel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dpressel",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null | 7
|
2020-05-18 19:22:03+00:00
|
2020-05-18 21:36:20+00:00
|
2020-05-18 21:36:20+00:00
|
NONE
| null | null | null | null |
hello,
I am working on a program that uses the `nlp` library with the `SST2` dataset.
The rough outline of the program is:
```
import nlp as nlp_datasets
...
parser.add_argument('--dataset', help='HuggingFace Datasets id', default=['glue', 'sst2'], nargs='+')
...
dataset = nlp_datasets.load_dataset(*args.dataset)
...
# Create feature vocabs
vocabs = create_vocabs(dataset.values(), vectorizers)
...
# Create a function to vectorize based on vectorizers and vocabs:
print('TS', train_set.num_rows)
print('VS', valid_set.num_rows)
print('ES', test_set.num_rows)
# factory method to create a `convert_to_features` function based on vocabs
convert_to_features = create_featurizer(vectorizers, vocabs)
train_set = train_set.map(convert_to_features, batched=True)
train_set.set_format(type='torch', columns=list(vectorizers.keys()) + ['y', 'lengths'])
train_loader = torch.utils.data.DataLoader(train_set, batch_size=args.batchsz)
valid_set = valid_set.map(convert_to_features, batched=True)
valid_set.set_format(type='torch', columns=list(vectorizers.keys()) + ['y', 'lengths'])
valid_loader = torch.utils.data.DataLoader(valid_set, batch_size=args.batchsz)
test_set = test_set.map(convert_to_features, batched=True)
test_set.set_format(type='torch', columns=list(vectorizers.keys()) + ['y', 'lengths'])
test_loader = torch.utils.data.DataLoader(test_set, batch_size=args.batchsz)
print('TS', train_set.num_rows)
print('VS', valid_set.num_rows)
print('ES', test_set.num_rows)
```
Im not sure if Im using it incorrectly, but the results are not what I expect. Namely, the `.map()` seems to grab the datset from the cache and then loses track of what the specific dataset is, instead using my training data for all datasets:
```
TS 67349
VS 872
ES 1821
TS 67349
VS 67349
ES 67349
```
The behavior changes if I turn off the caching but then the results fail:
```
train_set = train_set.map(convert_to_features, batched=True, load_from_cache_file=False)
...
valid_set = valid_set.map(convert_to_features, batched=True, load_from_cache_file=False)
...
test_set = test_set.map(convert_to_features, batched=True, load_from_cache_file=False)
```
Now I get the right set of features back...
```
TS 67349
VS 872
ES 1821
100%|██████████| 68/68 [00:00<00:00, 92.78it/s]
100%|██████████| 1/1 [00:00<00:00, 75.47it/s]
0%| | 0/2 [00:00<?, ?it/s]TS 67349
VS 872
ES 1821
100%|██████████| 2/2 [00:00<00:00, 77.19it/s]
```
but I think its losing track of the original training set:
```
Traceback (most recent call last):
File "/home/dpressel/dev/work/baseline/api-examples/layers-classify-hf-datasets.py", line 148, in <module>
for x in train_loader:
File "/home/dpressel/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/dpressel/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 385, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/home/dpressel/anaconda3/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/dpressel/anaconda3/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/dpressel/anaconda3/lib/python3.7/site-packages/nlp/arrow_dataset.py", line 338, in __getitem__
output_all_columns=self._output_all_columns,
File "/home/dpressel/anaconda3/lib/python3.7/site-packages/nlp/arrow_dataset.py", line 294, in _getitem
outputs = self._unnest(self._data.slice(key, 1).to_pydict())
File "pyarrow/table.pxi", line 1211, in pyarrow.lib.Table.slice
File "pyarrow/public-api.pxi", line 390, in pyarrow.lib.pyarrow_wrap_table
File "pyarrow/error.pxi", line 85, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Column 3: In chunk 0: Invalid: Length spanned by list offsets (15859698) larger than values array (length 100000)
Process finished with exit code 1
```
The full-example program (minus the print stmts) is here:
https://github.com/dpressel/mead-baseline/pull/620/files
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/160/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/160/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/159
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/159/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/159/comments
|
https://api.github.com/repos/huggingface/datasets/issues/159/events
|
https://github.com/huggingface/datasets/issues/159
| 620,420,700
|
MDU6SXNzdWU2MjA0MjA3MDA=
| 159
|
How can we add more datasets to nlp library?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17886829?v=4",
"events_url": "https://api.github.com/users/Tahsin-Mayeesha/events{/privacy}",
"followers_url": "https://api.github.com/users/Tahsin-Mayeesha/followers",
"following_url": "https://api.github.com/users/Tahsin-Mayeesha/following{/other_user}",
"gists_url": "https://api.github.com/users/Tahsin-Mayeesha/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Tahsin-Mayeesha",
"id": 17886829,
"login": "Tahsin-Mayeesha",
"node_id": "MDQ6VXNlcjE3ODg2ODI5",
"organizations_url": "https://api.github.com/users/Tahsin-Mayeesha/orgs",
"received_events_url": "https://api.github.com/users/Tahsin-Mayeesha/received_events",
"repos_url": "https://api.github.com/users/Tahsin-Mayeesha/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Tahsin-Mayeesha/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Tahsin-Mayeesha/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Tahsin-Mayeesha",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-05-18 18:35:31+00:00
|
2020-05-18 18:37:08+00:00
|
2020-05-18 18:37:07+00:00
|
NONE
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/17886829?v=4",
"events_url": "https://api.github.com/users/Tahsin-Mayeesha/events{/privacy}",
"followers_url": "https://api.github.com/users/Tahsin-Mayeesha/followers",
"following_url": "https://api.github.com/users/Tahsin-Mayeesha/following{/other_user}",
"gists_url": "https://api.github.com/users/Tahsin-Mayeesha/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Tahsin-Mayeesha",
"id": 17886829,
"login": "Tahsin-Mayeesha",
"node_id": "MDQ6VXNlcjE3ODg2ODI5",
"organizations_url": "https://api.github.com/users/Tahsin-Mayeesha/orgs",
"received_events_url": "https://api.github.com/users/Tahsin-Mayeesha/received_events",
"repos_url": "https://api.github.com/users/Tahsin-Mayeesha/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Tahsin-Mayeesha/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Tahsin-Mayeesha/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Tahsin-Mayeesha",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/159/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/159/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
|
https://api.github.com/repos/huggingface/datasets/issues/158
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/158/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/158/comments
|
https://api.github.com/repos/huggingface/datasets/issues/158/events
|
https://github.com/huggingface/datasets/pull/158
| 620,396,658
|
MDExOlB1bGxSZXF1ZXN0NDE5NjUyNTQy
| 158
|
add Toronto Books Corpus
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-18 17:54:45+00:00
|
2020-06-11 07:49:15+00:00
|
2020-05-19 07:34:56+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/158.diff",
"html_url": "https://github.com/huggingface/datasets/pull/158",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/158.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/158"
}
|
This PR adds the Toronto Books Corpus.
.
It on consider TMX and plain text files (Moses) defined in the table **Statistics and TMX/Moses Downloads** [here](http://opus.nlpl.eu/Books.php )
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/158/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/158/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/157
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/157/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/157/comments
|
https://api.github.com/repos/huggingface/datasets/issues/157/events
|
https://github.com/huggingface/datasets/issues/157
| 620,356,542
|
MDU6SXNzdWU2MjAzNTY1NDI=
| 157
|
nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)"
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47444392?v=4",
"events_url": "https://api.github.com/users/saahiluppal/events{/privacy}",
"followers_url": "https://api.github.com/users/saahiluppal/followers",
"following_url": "https://api.github.com/users/saahiluppal/following{/other_user}",
"gists_url": "https://api.github.com/users/saahiluppal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/saahiluppal",
"id": 47444392,
"login": "saahiluppal",
"node_id": "MDQ6VXNlcjQ3NDQ0Mzky",
"organizations_url": "https://api.github.com/users/saahiluppal/orgs",
"received_events_url": "https://api.github.com/users/saahiluppal/received_events",
"repos_url": "https://api.github.com/users/saahiluppal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/saahiluppal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/saahiluppal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/saahiluppal",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
] | null | 11
|
2020-05-18 16:46:38+00:00
|
2020-06-05 08:08:58+00:00
|
2020-06-05 08:08:58+00:00
|
NONE
| null | null | null | null |
I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/157/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/157/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/156
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/156/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/156/comments
|
https://api.github.com/repos/huggingface/datasets/issues/156/events
|
https://github.com/huggingface/datasets/issues/156
| 620,263,687
|
MDU6SXNzdWU2MjAyNjM2ODc=
| 156
|
SyntaxError with WMT datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/9419158?v=4",
"events_url": "https://api.github.com/users/tomhosking/events{/privacy}",
"followers_url": "https://api.github.com/users/tomhosking/followers",
"following_url": "https://api.github.com/users/tomhosking/following{/other_user}",
"gists_url": "https://api.github.com/users/tomhosking/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tomhosking",
"id": 9419158,
"login": "tomhosking",
"node_id": "MDQ6VXNlcjk0MTkxNTg=",
"organizations_url": "https://api.github.com/users/tomhosking/orgs",
"received_events_url": "https://api.github.com/users/tomhosking/received_events",
"repos_url": "https://api.github.com/users/tomhosking/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tomhosking/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tomhosking/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tomhosking",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
] | null | 7
|
2020-05-18 14:38:18+00:00
|
2020-07-23 16:41:55+00:00
|
2020-07-23 16:41:55+00:00
|
NONE
| null | null | null | null |
The following snippet produces a syntax error:
```
import nlp
dataset = nlp.load_dataset('wmt14')
print(dataset['train'][0])
```
```
Traceback (most recent call last):
File "/home/tom/.local/lib/python3.6/site-packages/IPython/core/interactiveshell.py", line 3326, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-8-3206959998b9>", line 3, in <module>
dataset = nlp.load_dataset('wmt14')
File "/home/tom/.local/lib/python3.6/site-packages/nlp/load.py", line 505, in load_dataset
builder_cls = import_main_class(module_path, dataset=True)
File "/home/tom/.local/lib/python3.6/site-packages/nlp/load.py", line 56, in import_main_class
module = importlib.import_module(module_path)
File "/usr/lib/python3.6/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 994, in _gcd_import
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 955, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 665, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 678, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/home/tom/.local/lib/python3.6/site-packages/nlp/datasets/wmt14/c258d646f4f5870b0245f783b7aa0af85c7117e06aacf1e0340bd81935094de2/wmt14.py", line 21, in <module>
from .wmt_utils import Wmt, WmtConfig
File "/home/tom/.local/lib/python3.6/site-packages/nlp/datasets/wmt14/c258d646f4f5870b0245f783b7aa0af85c7117e06aacf1e0340bd81935094de2/wmt_utils.py", line 659
<<<<<<< HEAD
^
SyntaxError: invalid syntax
```
Python version:
`3.6.9 (default, Apr 18 2020, 01:56:04) [GCC 8.4.0]`
Running on Ubuntu 18.04, via a Jupyter notebook
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/156/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/156/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/155
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/155/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/155/comments
|
https://api.github.com/repos/huggingface/datasets/issues/155/events
|
https://github.com/huggingface/datasets/pull/155
| 620,067,946
|
MDExOlB1bGxSZXF1ZXN0NDE5Mzg1ODM0
| 155
|
Include more links in README, fix typos
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13381361?v=4",
"events_url": "https://api.github.com/users/bharatr21/events{/privacy}",
"followers_url": "https://api.github.com/users/bharatr21/followers",
"following_url": "https://api.github.com/users/bharatr21/following{/other_user}",
"gists_url": "https://api.github.com/users/bharatr21/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bharatr21",
"id": 13381361,
"login": "bharatr21",
"node_id": "MDQ6VXNlcjEzMzgxMzYx",
"organizations_url": "https://api.github.com/users/bharatr21/orgs",
"received_events_url": "https://api.github.com/users/bharatr21/received_events",
"repos_url": "https://api.github.com/users/bharatr21/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bharatr21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bharatr21/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bharatr21",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-05-18 09:47:08+00:00
|
2020-05-28 08:31:57+00:00
|
2020-05-28 08:31:57+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/155.diff",
"html_url": "https://github.com/huggingface/datasets/pull/155",
"merged_at": "2020-05-28T08:31:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/155.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/155"
}
|
Include more links and fix typos in README
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/155/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/155/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/154
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/154/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/154/comments
|
https://api.github.com/repos/huggingface/datasets/issues/154/events
|
https://github.com/huggingface/datasets/pull/154
| 620,059,066
|
MDExOlB1bGxSZXF1ZXN0NDE5Mzc4Mzgw
| 154
|
add Ubuntu Dialogs Corpus datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-18 09:34:48+00:00
|
2020-05-18 10:12:28+00:00
|
2020-05-18 10:12:27+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/154.diff",
"html_url": "https://github.com/huggingface/datasets/pull/154",
"merged_at": "2020-05-18T10:12:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/154.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/154"
}
|
This PR adds the Ubuntu Dialog Corpus datasets version 2.0.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/154/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/154/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/153
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/153/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/153/comments
|
https://api.github.com/repos/huggingface/datasets/issues/153/events
|
https://github.com/huggingface/datasets/issues/153
| 619,972,246
|
MDU6SXNzdWU2MTk5NzIyNDY=
| 153
|
Meta-datasets (GLUE/XTREME/...) – Special care to attributions and citations
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] |
open
| false
| null |
[] | null | 4
|
2020-05-18 07:24:22+00:00
|
2020-05-18 21:18:16+00:00
|
NaT
|
MEMBER
| null | null | null | null |
Meta-datasets are interesting in terms of standardized benchmarks but they also have specific behaviors, in particular in terms of attribution and authorship. It's very important that each specific dataset inside a meta dataset is properly referenced and the citation/specific homepage/etc are very visible and accessible and not only the generic citation of the meta-dataset itself.
Let's take GLUE as an example:
The configuration has the citation for each dataset included (e.g. [here](https://github.com/huggingface/nlp/blob/master/datasets/glue/glue.py#L154-L161)) but it should be copied inside the dataset info so that, when people access `dataset.info.citation` they get both the citation for GLUE and the citation for the specific datasets inside GLUE that they have loaded.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/153/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/153/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/152
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/152/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/152/comments
|
https://api.github.com/repos/huggingface/datasets/issues/152/events
|
https://github.com/huggingface/datasets/pull/152
| 619,971,900
|
MDExOlB1bGxSZXF1ZXN0NDE5MzA4OTE2
| 152
|
Add GLUE config name check
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13381361?v=4",
"events_url": "https://api.github.com/users/bharatr21/events{/privacy}",
"followers_url": "https://api.github.com/users/bharatr21/followers",
"following_url": "https://api.github.com/users/bharatr21/following{/other_user}",
"gists_url": "https://api.github.com/users/bharatr21/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bharatr21",
"id": 13381361,
"login": "bharatr21",
"node_id": "MDQ6VXNlcjEzMzgxMzYx",
"organizations_url": "https://api.github.com/users/bharatr21/orgs",
"received_events_url": "https://api.github.com/users/bharatr21/received_events",
"repos_url": "https://api.github.com/users/bharatr21/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bharatr21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bharatr21/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bharatr21",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 5
|
2020-05-18 07:23:43+00:00
|
2020-05-27 22:09:12+00:00
|
2020-05-27 22:09:12+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/152.diff",
"html_url": "https://github.com/huggingface/datasets/pull/152",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/152.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/152"
}
|
Fixes #130 by adding a name check to the Glue class
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/152/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/152/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/151
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/151/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/151/comments
|
https://api.github.com/repos/huggingface/datasets/issues/151/events
|
https://github.com/huggingface/datasets/pull/151
| 619,968,480
|
MDExOlB1bGxSZXF1ZXN0NDE5MzA2MTYz
| 151
|
Fix JSON tests.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-18 07:17:38+00:00
|
2020-05-18 07:21:52+00:00
|
2020-05-18 07:21:51+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/151.diff",
"html_url": "https://github.com/huggingface/datasets/pull/151",
"merged_at": "2020-05-18T07:21:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/151.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/151"
}
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/151/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/151/timeline
| null | null | null | null | true
|
|
https://api.github.com/repos/huggingface/datasets/issues/150
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/150/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/150/comments
|
https://api.github.com/repos/huggingface/datasets/issues/150/events
|
https://github.com/huggingface/datasets/pull/150
| 619,809,645
|
MDExOlB1bGxSZXF1ZXN0NDE5MTgyODU4
| 150
|
Add WNUT 17 NER dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stefan-it",
"id": 20651387,
"login": "stefan-it",
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stefan-it",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 4
|
2020-05-17 22:19:04+00:00
|
2020-05-26 20:37:59+00:00
|
2020-05-26 20:37:59+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/150.diff",
"html_url": "https://github.com/huggingface/datasets/pull/150",
"merged_at": "2020-05-26T20:37:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/150.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/150"
}
|
Hi,
this PR adds the WNUT 17 dataset to `nlp`.
> Emerging and Rare entity recognition
> This shared task focuses on identifying unusual, previously-unseen entities in the context of emerging discussions. Named entities form the basis of many modern approaches to other tasks (like event clustering and summarisation), but recall on them is a real problem in noisy text - even among annotators. This drop tends to be due to novel entities and surface forms. Take for example the tweet “so.. kktny in 30 mins?” - even human experts find entity kktny hard to detect and resolve. This task will evaluate the ability to detect and classify novel, emerging, singleton named entities in noisy text.
>
> The goal of this task is to provide a definition of emerging and of rare entities, and based on that, also datasets for detecting these entities.
More information about the dataset can be found on the [shared task page](https://noisy-text.github.io/2017/emerging-rare-entities.html).
Dataset is taken is taken from their [GitHub repository](https://github.com/leondz/emerging_entities_17), because the data provided in this repository contains minor fixes in the dataset format.
## Usage
Then the WNUT 17 dataset can be used in `nlp` like this:
```python
import nlp
wnut_17 = nlp.load_dataset("./datasets/wnut_17/wnut_17.py")
print(wnut_17)
```
This outputs:
```txt
'train': Dataset(schema: {'id': 'string', 'tokens': 'list<item: string>', 'labels': 'list<item: string>'}, num_rows: 3394)
'validation': Dataset(schema: {'id': 'string', 'tokens': 'list<item: string>', 'labels': 'list<item: string>'}, num_rows: 1009)
'test': Dataset(schema: {'id': 'string', 'tokens': 'list<item: string>', 'labels': 'list<item: string>'}, num_rows: 1287)
```
Number are identical with the ones in [this paper](https://www.ijcai.org/Proceedings/2019/0702.pdf) and are the same as using the `dataset` reader in Flair.
## Features
The following feature format is used to represent a sentence in the WNUT 17 dataset:
| Feature | Example | Description
| ---- | ---- | -----------------
| `id` | `0` | Number (id) of current sentence
| `tokens` | `["AHFA", "extends", "deadline"]` | List of tokens (strings) for a sentence
| `labels` | `["B-group", "O", "O"]` | List of labels (outer span)
The following labels are used in WNUT 17:
```txt
O
B-corporation
I-corporation
B-location
I-location
B-product
I-product
B-person
I-person
B-group
I-group
B-creative-work
I-creative-work
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/150/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/150/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/149
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/149/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/149/comments
|
https://api.github.com/repos/huggingface/datasets/issues/149/events
|
https://github.com/huggingface/datasets/issues/149
| 619,735,739
|
MDU6SXNzdWU2MTk3MzU3Mzk=
| 149
|
[Feature request] Add Ubuntu Dialogue Corpus dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/28959268?v=4",
"events_url": "https://api.github.com/users/danth/events{/privacy}",
"followers_url": "https://api.github.com/users/danth/followers",
"following_url": "https://api.github.com/users/danth/following{/other_user}",
"gists_url": "https://api.github.com/users/danth/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/danth",
"id": 28959268,
"login": "danth",
"node_id": "MDQ6VXNlcjI4OTU5MjY4",
"organizations_url": "https://api.github.com/users/danth/orgs",
"received_events_url": "https://api.github.com/users/danth/received_events",
"repos_url": "https://api.github.com/users/danth/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/danth/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danth/subscriptions",
"type": "User",
"url": "https://api.github.com/users/danth",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
closed
| false
| null |
[] | null | 1
|
2020-05-17 15:42:39+00:00
|
2020-05-18 17:01:46+00:00
|
2020-05-18 17:01:46+00:00
|
NONE
| null | null | null | null |
https://github.com/rkadlec/ubuntu-ranking-dataset-creator or http://dataset.cs.mcgill.ca/ubuntu-corpus-1.0/
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/28959268?v=4",
"events_url": "https://api.github.com/users/danth/events{/privacy}",
"followers_url": "https://api.github.com/users/danth/followers",
"following_url": "https://api.github.com/users/danth/following{/other_user}",
"gists_url": "https://api.github.com/users/danth/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/danth",
"id": 28959268,
"login": "danth",
"node_id": "MDQ6VXNlcjI4OTU5MjY4",
"organizations_url": "https://api.github.com/users/danth/orgs",
"received_events_url": "https://api.github.com/users/danth/received_events",
"repos_url": "https://api.github.com/users/danth/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/danth/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danth/subscriptions",
"type": "User",
"url": "https://api.github.com/users/danth",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/149/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/149/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/148
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/148/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/148/comments
|
https://api.github.com/repos/huggingface/datasets/issues/148/events
|
https://github.com/huggingface/datasets/issues/148
| 619,590,555
|
MDU6SXNzdWU2MTk1OTA1NTU=
| 148
|
_download_and_prepare() got an unexpected keyword argument 'verify_infos'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/richarddwang",
"id": 17963619,
"login": "richarddwang",
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/richarddwang",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
| null |
[] | null | 2
|
2020-05-17 01:48:53+00:00
|
2020-05-18 07:38:33+00:00
|
2020-05-18 07:38:33+00:00
|
CONTRIBUTOR
| null | null | null | null |
# Reproduce
In Colab,
```
%pip install -q nlp
%pip install -q apache_beam mwparserfromhell
dataset = nlp.load_dataset('wikipedia')
```
get
```
Downloading and preparing dataset wikipedia/20200501.aa (download: Unknown size, generated: Unknown size, total: Unknown size) to /root/.cache/huggingface/datasets/wikipedia/20200501.aa/1.0.0...
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-6-52471d2a0088> in <module>()
----> 1 dataset = nlp.load_dataset('wikipedia')
1 frames
/usr/local/lib/python3.6/dist-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
515 download_mode=download_mode,
516 ignore_verifications=ignore_verifications,
--> 517 save_infos=save_infos,
518 )
519
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, dl_manager, **download_and_prepare_kwargs)
361 verify_infos = not save_infos and not ignore_verifications
362 self._download_and_prepare(
--> 363 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
364 )
365 # Sync info
TypeError: _download_and_prepare() got an unexpected keyword argument 'verify_infos'
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/148/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/148/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/147
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/147/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/147/comments
|
https://api.github.com/repos/huggingface/datasets/issues/147/events
|
https://github.com/huggingface/datasets/issues/147
| 619,581,907
|
MDU6SXNzdWU2MTk1ODE5MDc=
| 147
|
Error with sklearn train_test_split
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6853743?v=4",
"events_url": "https://api.github.com/users/ClonedOne/events{/privacy}",
"followers_url": "https://api.github.com/users/ClonedOne/followers",
"following_url": "https://api.github.com/users/ClonedOne/following{/other_user}",
"gists_url": "https://api.github.com/users/ClonedOne/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ClonedOne",
"id": 6853743,
"login": "ClonedOne",
"node_id": "MDQ6VXNlcjY4NTM3NDM=",
"organizations_url": "https://api.github.com/users/ClonedOne/orgs",
"received_events_url": "https://api.github.com/users/ClonedOne/received_events",
"repos_url": "https://api.github.com/users/ClonedOne/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ClonedOne/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ClonedOne/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ClonedOne",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
| null |
[] | null | 2
|
2020-05-17 00:28:24+00:00
|
2020-06-18 16:23:23+00:00
|
2020-06-18 16:23:23+00:00
|
NONE
| null | null | null | null |
It would be nice if we could use sklearn `train_test_split` to quickly generate subsets from the dataset objects returned by `nlp.load_dataset`. At the moment the code:
```python
data = nlp.load_dataset('imdb', cache_dir=data_cache)
f_half, s_half = train_test_split(data['train'], test_size=0.5, random_state=seed)
```
throws:
```
ValueError: Can only get row(s) (int or slice) or columns (string).
```
It's not a big deal, since there are other ways to split the data, but it would be a cool thing to have.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/147/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/147/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/146
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/146/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/146/comments
|
https://api.github.com/repos/huggingface/datasets/issues/146/events
|
https://github.com/huggingface/datasets/pull/146
| 619,564,653
|
MDExOlB1bGxSZXF1ZXN0NDE5MDI5MjUx
| 146
|
Add BERTScore to metrics
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7753366?v=4",
"events_url": "https://api.github.com/users/felixgwu/events{/privacy}",
"followers_url": "https://api.github.com/users/felixgwu/followers",
"following_url": "https://api.github.com/users/felixgwu/following{/other_user}",
"gists_url": "https://api.github.com/users/felixgwu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/felixgwu",
"id": 7753366,
"login": "felixgwu",
"node_id": "MDQ6VXNlcjc3NTMzNjY=",
"organizations_url": "https://api.github.com/users/felixgwu/orgs",
"received_events_url": "https://api.github.com/users/felixgwu/received_events",
"repos_url": "https://api.github.com/users/felixgwu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/felixgwu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/felixgwu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/felixgwu",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-05-16 22:09:39+00:00
|
2020-05-17 22:22:10+00:00
|
2020-05-17 22:22:09+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/146.diff",
"html_url": "https://github.com/huggingface/datasets/pull/146",
"merged_at": "2020-05-17T22:22:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/146.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/146"
}
|
This PR adds [BERTScore](https://arxiv.org/abs/1904.09675) to metrics.
Here is an example of how to use it.
```sh
import nlp
bertscore = nlp.load_metric('metrics/bertscore') # or simply nlp.load_metric('bertscore') after this is added to huggingface's s3 bucket
predictions = ['example', 'fruit']
references = [['this is an example.', 'this is one example.'], ['apple']]
results = bertscore.compute(predictions, references, lang='en')
print(results)
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/146/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/146/timeline
| null | null | null | null | true
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.