
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
3.53B
| node_id
stringlengths 18
32
| number
int64 1
7.82k
| title
stringlengths 1
290
| user
dict | labels
listlengths 0
4
| state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
listlengths 0
4
| milestone
dict | comments
int64 0
70
| created_at
stringdate 2020-04-14 10:18:02
2025-10-20 06:38:19
| updated_at
stringdate 2020-04-27 16:04:17
2025-10-20 06:41:20
| closed_at
stringlengths 3
25
| author_association
stringclasses 4
values | type
float64 | active_lock_reason
float64 | draft
float64 0
1
⌀ | pull_request
dict | body
stringlengths 0
228k
⌀ | closed_by
dict | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
float64 | state_reason
stringclasses 4
values | sub_issues_summary
dict | issue_dependencies_summary
dict | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/449
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/449/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/449/comments
|
https://api.github.com/repos/huggingface/datasets/issues/449/events
|
https://github.com/huggingface/datasets/pull/449
| 666,898,923
|
MDExOlB1bGxSZXF1ZXN0NDU3NjY0NjYx
| 449
|
add reuters21578 dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-07-28 08:58:12+00:00
|
2023-09-24 09:49:28+00:00
|
2020-08-03 11:10:31+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/449.diff",
"html_url": "https://github.com/huggingface/datasets/pull/449",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/449.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/449"
}
|
This PR adds the `Reuters_21578` dataset https://kdd.ics.uci.edu/databases/reuters21578/reuters21578.html
#353
The datasets is a lit of `.sgm` files which are a bit different from xml file indeed `xml.etree` couldn't be used to read files. I consider them as text file (to avoid using external library) and read line by line (maybe there is a better way to do, happy to get your opinion on it)
In the Readme file 3 ways to split the dataset are given.:
- The Modified Lewis ("ModLewis") Split: train, test and unused-set
- The Modified Apte ("ModApte") Split : train, test and unused-set
- The Modified Hayes ("ModHayes") Split: train and test
Here I consider the last one as the readme file highlight that this split provides the ability to compare results with those of the 2 first splits.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/449/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/449/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/448
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/448/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/448/comments
|
https://api.github.com/repos/huggingface/datasets/issues/448/events
|
https://github.com/huggingface/datasets/pull/448
| 666,893,443
|
MDExOlB1bGxSZXF1ZXN0NDU3NjYwMDU2
| 448
|
add aws load metric test
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5303103?v=4",
"events_url": "https://api.github.com/users/idoh/events{/privacy}",
"followers_url": "https://api.github.com/users/idoh/followers",
"following_url": "https://api.github.com/users/idoh/following{/other_user}",
"gists_url": "https://api.github.com/users/idoh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/idoh",
"id": 5303103,
"login": "idoh",
"node_id": "MDQ6VXNlcjUzMDMxMDM=",
"organizations_url": "https://api.github.com/users/idoh/orgs",
"received_events_url": "https://api.github.com/users/idoh/received_events",
"repos_url": "https://api.github.com/users/idoh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/idoh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/idoh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/idoh",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-07-28 08:50:22+00:00
|
2020-07-28 15:02:27+00:00
|
2020-07-28 15:02:27+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/448.diff",
"html_url": "https://github.com/huggingface/datasets/pull/448",
"merged_at": "2020-07-28T15:02:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/448.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/448"
}
|
Following issue #445
Added a test to recognize import errors of all metrics
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/448/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/448/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/447
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/447/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/447/comments
|
https://api.github.com/repos/huggingface/datasets/issues/447/events
|
https://github.com/huggingface/datasets/pull/447
| 666,842,115
|
MDExOlB1bGxSZXF1ZXN0NDU3NjE2NDA0
| 447
|
[BugFix] fix wrong import of DEFAULT_TOKENIZER
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5303103?v=4",
"events_url": "https://api.github.com/users/idoh/events{/privacy}",
"followers_url": "https://api.github.com/users/idoh/followers",
"following_url": "https://api.github.com/users/idoh/following{/other_user}",
"gists_url": "https://api.github.com/users/idoh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/idoh",
"id": 5303103,
"login": "idoh",
"node_id": "MDQ6VXNlcjUzMDMxMDM=",
"organizations_url": "https://api.github.com/users/idoh/orgs",
"received_events_url": "https://api.github.com/users/idoh/received_events",
"repos_url": "https://api.github.com/users/idoh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/idoh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/idoh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/idoh",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-28 07:41:10+00:00
|
2020-07-28 12:58:01+00:00
|
2020-07-28 12:52:05+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/447.diff",
"html_url": "https://github.com/huggingface/datasets/pull/447",
"merged_at": "2020-07-28T12:52:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/447.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/447"
}
|
Fixed the path to `DEFAULT_TOKENIZER`
#445
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/447/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/447/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/446
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/446/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/446/comments
|
https://api.github.com/repos/huggingface/datasets/issues/446/events
|
https://github.com/huggingface/datasets/pull/446
| 666,837,351
|
MDExOlB1bGxSZXF1ZXN0NDU3NjEyNTg5
| 446
|
[BugFix] fix wrong import of DEFAULT_TOKENIZER
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5303103?v=4",
"events_url": "https://api.github.com/users/idoh/events{/privacy}",
"followers_url": "https://api.github.com/users/idoh/followers",
"following_url": "https://api.github.com/users/idoh/following{/other_user}",
"gists_url": "https://api.github.com/users/idoh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/idoh",
"id": 5303103,
"login": "idoh",
"node_id": "MDQ6VXNlcjUzMDMxMDM=",
"organizations_url": "https://api.github.com/users/idoh/orgs",
"received_events_url": "https://api.github.com/users/idoh/received_events",
"repos_url": "https://api.github.com/users/idoh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/idoh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/idoh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/idoh",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-28 07:32:47+00:00
|
2020-07-28 07:34:46+00:00
|
2020-07-28 07:33:59+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/446.diff",
"html_url": "https://github.com/huggingface/datasets/pull/446",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/446.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/446"
}
|
Fixed the path to `DEFAULT_TOKENIZER`
#445
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5303103?v=4",
"events_url": "https://api.github.com/users/idoh/events{/privacy}",
"followers_url": "https://api.github.com/users/idoh/followers",
"following_url": "https://api.github.com/users/idoh/following{/other_user}",
"gists_url": "https://api.github.com/users/idoh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/idoh",
"id": 5303103,
"login": "idoh",
"node_id": "MDQ6VXNlcjUzMDMxMDM=",
"organizations_url": "https://api.github.com/users/idoh/orgs",
"received_events_url": "https://api.github.com/users/idoh/received_events",
"repos_url": "https://api.github.com/users/idoh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/idoh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/idoh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/idoh",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/446/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/446/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/445
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/445/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/445/comments
|
https://api.github.com/repos/huggingface/datasets/issues/445/events
|
https://github.com/huggingface/datasets/issues/445
| 666,836,658
|
MDU6SXNzdWU2NjY4MzY2NTg=
| 445
|
DEFAULT_TOKENIZER import error in sacrebleu
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5303103?v=4",
"events_url": "https://api.github.com/users/idoh/events{/privacy}",
"followers_url": "https://api.github.com/users/idoh/followers",
"following_url": "https://api.github.com/users/idoh/following{/other_user}",
"gists_url": "https://api.github.com/users/idoh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/idoh",
"id": 5303103,
"login": "idoh",
"node_id": "MDQ6VXNlcjUzMDMxMDM=",
"organizations_url": "https://api.github.com/users/idoh/orgs",
"received_events_url": "https://api.github.com/users/idoh/received_events",
"repos_url": "https://api.github.com/users/idoh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/idoh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/idoh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/idoh",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-07-28 07:31:30+00:00
|
2020-07-28 12:58:56+00:00
|
2020-07-28 12:58:56+00:00
|
CONTRIBUTOR
| null | null | null | null |
Latest Version 0.3.0
When loading the metric "sacrebleu" there is an import error due to the wrong path

|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5303103?v=4",
"events_url": "https://api.github.com/users/idoh/events{/privacy}",
"followers_url": "https://api.github.com/users/idoh/followers",
"following_url": "https://api.github.com/users/idoh/following{/other_user}",
"gists_url": "https://api.github.com/users/idoh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/idoh",
"id": 5303103,
"login": "idoh",
"node_id": "MDQ6VXNlcjUzMDMxMDM=",
"organizations_url": "https://api.github.com/users/idoh/orgs",
"received_events_url": "https://api.github.com/users/idoh/received_events",
"repos_url": "https://api.github.com/users/idoh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/idoh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/idoh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/idoh",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/445/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/445/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/444
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/444/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/444/comments
|
https://api.github.com/repos/huggingface/datasets/issues/444/events
|
https://github.com/huggingface/datasets/issues/444
| 666,280,842
|
MDU6SXNzdWU2NjYyODA4NDI=
| 444
|
Keep loading old file even I specify a new file in load_dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10594453?v=4",
"events_url": "https://api.github.com/users/joshhu/events{/privacy}",
"followers_url": "https://api.github.com/users/joshhu/followers",
"following_url": "https://api.github.com/users/joshhu/following{/other_user}",
"gists_url": "https://api.github.com/users/joshhu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/joshhu",
"id": 10594453,
"login": "joshhu",
"node_id": "MDQ6VXNlcjEwNTk0NDUz",
"organizations_url": "https://api.github.com/users/joshhu/orgs",
"received_events_url": "https://api.github.com/users/joshhu/received_events",
"repos_url": "https://api.github.com/users/joshhu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/joshhu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/joshhu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/joshhu",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null | 2
|
2020-07-27 13:08:06+00:00
|
2020-07-29 13:57:22+00:00
|
2020-07-29 13:57:22+00:00
|
NONE
| null | null | null | null |
I used load a file called 'a.csv' by
```
dataset = load_dataset('csv', data_file='./a.csv')
```
And after a while, I tried to load another csv called 'b.csv'
```
dataset = load_dataset('csv', data_file='./b.csv')
```
However, the new dataset seems to remain the old 'a.csv' and not loading new csv file.
Even worse, after I load a.csv, the load_dataset function keeps loading the 'a.csv' afterward.
Is this a cache problem?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/444/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/444/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/443
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/443/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/443/comments
|
https://api.github.com/repos/huggingface/datasets/issues/443/events
|
https://github.com/huggingface/datasets/issues/443
| 666,246,716
|
MDU6SXNzdWU2NjYyNDY3MTY=
| 443
|
Cannot unpickle saved .pt dataset with torch.save()/load()
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/24683907?v=4",
"events_url": "https://api.github.com/users/vegarab/events{/privacy}",
"followers_url": "https://api.github.com/users/vegarab/followers",
"following_url": "https://api.github.com/users/vegarab/following{/other_user}",
"gists_url": "https://api.github.com/users/vegarab/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vegarab",
"id": 24683907,
"login": "vegarab",
"node_id": "MDQ6VXNlcjI0NjgzOTA3",
"organizations_url": "https://api.github.com/users/vegarab/orgs",
"received_events_url": "https://api.github.com/users/vegarab/received_events",
"repos_url": "https://api.github.com/users/vegarab/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vegarab/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vegarab/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vegarab",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-07-27 12:13:37+00:00
|
2020-07-27 13:05:11+00:00
|
2020-07-27 13:05:11+00:00
|
CONTRIBUTOR
| null | null | null | null |
Saving a formatted torch dataset to file using `torch.save()`. Loading the same file fails during unpickling:
```python
>>> import torch
>>> import nlp
>>> squad = nlp.load_dataset("squad.py", split="train")
>>> squad
Dataset(features: {'source_text': Value(dtype='string', id=None), 'target_text': Value(dtype='string', id=None)}, num_rows: 87599)
>>> squad = squad.map(create_features, batched=True)
>>> squad.set_format(type="torch", columns=["source_ids", "target_ids", "attention_mask"])
>>> torch.save(squad, "squad.pt")
>>> squad_pt = torch.load("squad.pt")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/vegarab/.conda/envs/torch/lib/python3.7/site-packages/torch/serialization.py", line 593, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "/home/vegarab/.conda/envs/torch/lib/python3.7/site-packages/torch/serialization.py", line 773, in _legacy_load
result = unpickler.load()
File "/home/vegarab/.conda/envs/torch/lib/python3.7/site-packages/nlp/splits.py", line 493, in __setitem__
raise ValueError("Cannot add elem. Use .add() instead.")
ValueError: Cannot add elem. Use .add() instead.
```
where `create_features` is a function that tokenizes the data using `batch_encode_plus` and returns a Dict with `input_ids`, `target_ids` and `attention_mask`.
```python
def create_features(batch):
source_text_encoding = tokenizer.batch_encode_plus(
batch["source_text"],
max_length=max_source_length,
pad_to_max_length=True,
truncation=True)
target_text_encoding = tokenizer.batch_encode_plus(
batch["target_text"],
max_length=max_target_length,
pad_to_max_length=True,
truncation=True)
features = {
"source_ids": source_text_encoding["input_ids"],
"target_ids": target_text_encoding["input_ids"],
"attention_mask": source_text_encoding["attention_mask"]
}
return features
```
I found a similar issue in [issue 5267 in the huggingface/transformers repo](https://github.com/huggingface/transformers/issues/5267) which was solved by downgrading to `nlp==0.2.0`. That did not solve this problem, however.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/24683907?v=4",
"events_url": "https://api.github.com/users/vegarab/events{/privacy}",
"followers_url": "https://api.github.com/users/vegarab/followers",
"following_url": "https://api.github.com/users/vegarab/following{/other_user}",
"gists_url": "https://api.github.com/users/vegarab/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vegarab",
"id": 24683907,
"login": "vegarab",
"node_id": "MDQ6VXNlcjI0NjgzOTA3",
"organizations_url": "https://api.github.com/users/vegarab/orgs",
"received_events_url": "https://api.github.com/users/vegarab/received_events",
"repos_url": "https://api.github.com/users/vegarab/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vegarab/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vegarab/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vegarab",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/443/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/443/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/442
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/442/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/442/comments
|
https://api.github.com/repos/huggingface/datasets/issues/442/events
|
https://github.com/huggingface/datasets/issues/442
| 666,201,810
|
MDU6SXNzdWU2NjYyMDE4MTA=
| 442
|
[Suggestion] Glue Diagnostic Data with Labels
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/3662782?v=4",
"events_url": "https://api.github.com/users/ggbetz/events{/privacy}",
"followers_url": "https://api.github.com/users/ggbetz/followers",
"following_url": "https://api.github.com/users/ggbetz/following{/other_user}",
"gists_url": "https://api.github.com/users/ggbetz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ggbetz",
"id": 3662782,
"login": "ggbetz",
"node_id": "MDQ6VXNlcjM2NjI3ODI=",
"organizations_url": "https://api.github.com/users/ggbetz/orgs",
"received_events_url": "https://api.github.com/users/ggbetz/received_events",
"repos_url": "https://api.github.com/users/ggbetz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ggbetz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ggbetz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ggbetz",
"user_view_type": "public"
}
|
[
{
"color": "72f99f",
"default": false,
"description": "Discussions on the datasets",
"id": 2067401494,
"name": "Dataset discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAxNDk0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/Dataset%20discussion"
}
] |
open
| false
| null |
[] | null | 0
|
2020-07-27 10:59:58+00:00
|
2020-08-24 15:13:20+00:00
|
NaT
|
NONE
| null | null | null | null |
Hello! First of all, thanks for setting up this useful project!
I've just realised you provide the the [Glue Diagnostics Data](https://huggingface.co/nlp/viewer/?dataset=glue&config=ax) without labels, indicating in the `GlueConfig` that you've only a test set.
Yet, the data with labels is available, too (see also [here](https://gluebenchmark.com/diagnostics#introduction)):
https://www.dropbox.com/s/ju7d95ifb072q9f/diagnostic-full.tsv?dl=1
Have you considered incorporating it?
| null |
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/442/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/442/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/441
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/441/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/441/comments
|
https://api.github.com/repos/huggingface/datasets/issues/441/events
|
https://github.com/huggingface/datasets/pull/441
| 666,148,413
|
MDExOlB1bGxSZXF1ZXN0NDU3MDQyMjY3
| 441
|
Add features parameter in load dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-07-27 09:50:01+00:00
|
2020-07-30 12:51:17+00:00
|
2020-07-30 12:51:16+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/441.diff",
"html_url": "https://github.com/huggingface/datasets/pull/441",
"merged_at": "2020-07-30T12:51:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/441.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/441"
}
|
Added `features` argument in `nlp.load_dataset`.
If they don't match the data type, it raises a `ValueError`.
It's a draft PR because #440 needs to be merged first.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/441/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/441/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/440
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/440/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/440/comments
|
https://api.github.com/repos/huggingface/datasets/issues/440/events
|
https://github.com/huggingface/datasets/pull/440
| 666,116,823
|
MDExOlB1bGxSZXF1ZXN0NDU3MDE2MjQy
| 440
|
Fix user specified features in map
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-27 09:04:26+00:00
|
2020-07-28 09:25:23+00:00
|
2020-07-28 09:25:22+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/440.diff",
"html_url": "https://github.com/huggingface/datasets/pull/440",
"merged_at": "2020-07-28T09:25:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/440.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/440"
}
|
`.map` didn't keep the user specified features because of an issue in the writer.
The writer used to overwrite the user specified features with inferred features.
I also added tests to make sure it doesn't happen again.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/440/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/440/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/439
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/439/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/439/comments
|
https://api.github.com/repos/huggingface/datasets/issues/439/events
|
https://github.com/huggingface/datasets/issues/439
| 665,964,673
|
MDU6SXNzdWU2NjU5NjQ2NzM=
| 439
|
Issues: Adding a FAISS or Elastic Search index to a Dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/431890?v=4",
"events_url": "https://api.github.com/users/nsankar/events{/privacy}",
"followers_url": "https://api.github.com/users/nsankar/followers",
"following_url": "https://api.github.com/users/nsankar/following{/other_user}",
"gists_url": "https://api.github.com/users/nsankar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nsankar",
"id": 431890,
"login": "nsankar",
"node_id": "MDQ6VXNlcjQzMTg5MA==",
"organizations_url": "https://api.github.com/users/nsankar/orgs",
"received_events_url": "https://api.github.com/users/nsankar/received_events",
"repos_url": "https://api.github.com/users/nsankar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nsankar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nsankar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nsankar",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 5
|
2020-07-27 04:25:17+00:00
|
2020-10-28 01:46:24+00:00
|
2020-10-28 01:46:24+00:00
|
NONE
| null | null | null | null |
It seems the DPRContextEncoder, DPRContextEncoderTokenizer cited[ in this documentation](https://huggingface.co/nlp/faiss_and_ea.html) is not implemented ? It didnot work with the standard nlp installation . Also, I couldn't find or use it with the latest nlp install from github in Colab. Is there any dependency on the latest PyArrow 1.0.0 ? Is it yet to be made generally available ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/431890?v=4",
"events_url": "https://api.github.com/users/nsankar/events{/privacy}",
"followers_url": "https://api.github.com/users/nsankar/followers",
"following_url": "https://api.github.com/users/nsankar/following{/other_user}",
"gists_url": "https://api.github.com/users/nsankar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nsankar",
"id": 431890,
"login": "nsankar",
"node_id": "MDQ6VXNlcjQzMTg5MA==",
"organizations_url": "https://api.github.com/users/nsankar/orgs",
"received_events_url": "https://api.github.com/users/nsankar/received_events",
"repos_url": "https://api.github.com/users/nsankar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nsankar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nsankar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nsankar",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/439/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/439/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/438
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/438/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/438/comments
|
https://api.github.com/repos/huggingface/datasets/issues/438/events
|
https://github.com/huggingface/datasets/issues/438
| 665,865,490
|
MDU6SXNzdWU2NjU4NjU0OTA=
| 438
|
New Datasets: IWSLT15+, ITTB
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "https://api.github.com/users/sshleifer/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sshleifer",
"id": 6045025,
"login": "sshleifer",
"node_id": "MDQ6VXNlcjYwNDUwMjU=",
"organizations_url": "https://api.github.com/users/sshleifer/orgs",
"received_events_url": "https://api.github.com/users/sshleifer/received_events",
"repos_url": "https://api.github.com/users/sshleifer/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sshleifer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sshleifer/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sshleifer",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
open
| false
| null |
[] | null | 2
|
2020-07-26 21:43:04+00:00
|
2020-08-24 15:12:15+00:00
|
NaT
|
CONTRIBUTOR
| null | null | null | null |
**Links:**
[iwslt](https://pytorchnlp.readthedocs.io/en/latest/_modules/torchnlp/datasets/iwslt.html)
Don't know if that link is up to date.
[ittb](http://www.cfilt.iitb.ac.in/iitb_parallel/)
**Motivation**: replicate mbart finetuning results (table below)
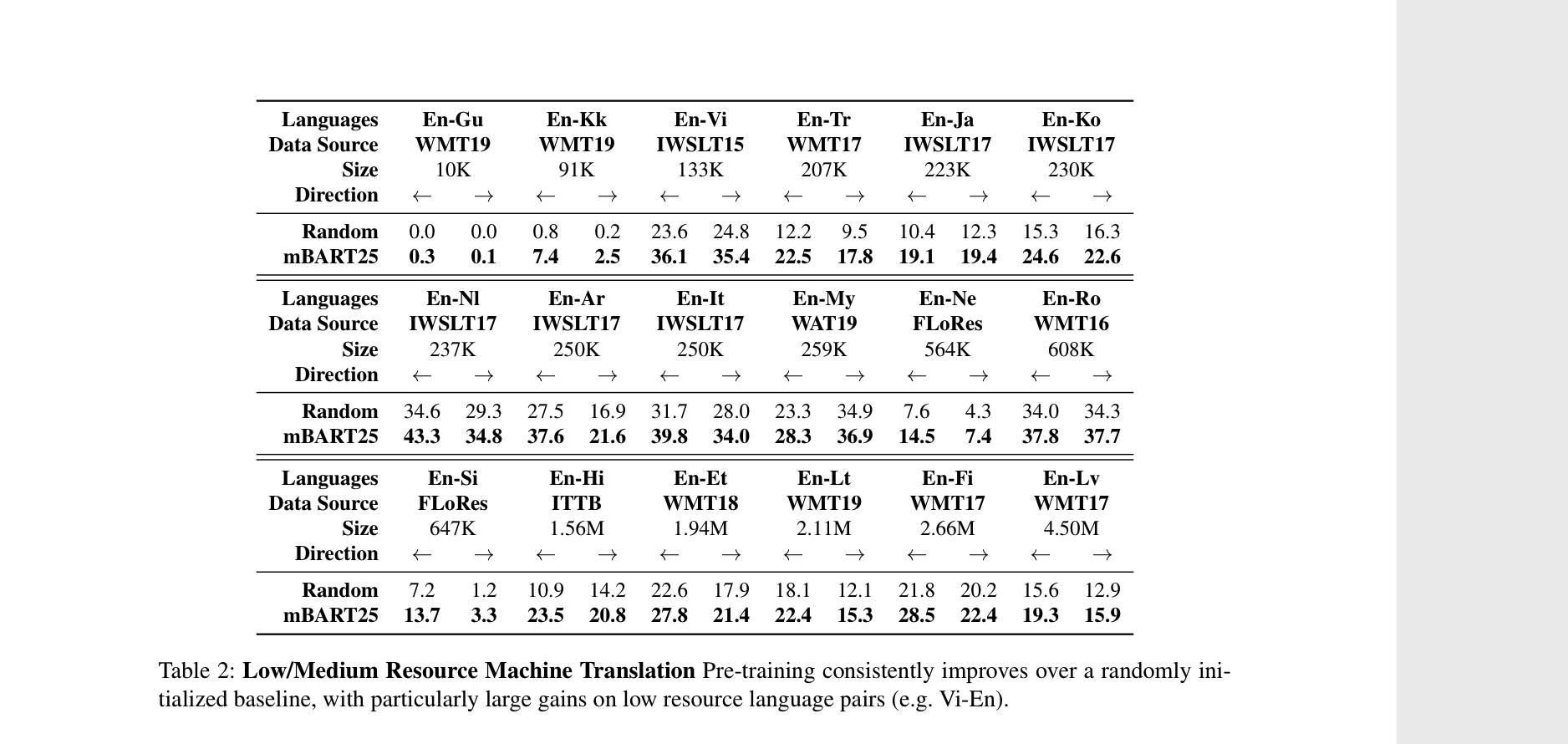
For future readers, we already have the following language pairs in the wmt namespaces:
```
wmt14: ['cs-en', 'de-en', 'fr-en', 'hi-en', 'ru-en']
wmt15: ['cs-en', 'de-en', 'fi-en', 'fr-en', 'ru-en']
wmt16: ['cs-en', 'de-en', 'fi-en', 'ro-en', 'ru-en', 'tr-en']
wmt17: ['cs-en', 'de-en', 'fi-en', 'lv-en', 'ru-en', 'tr-en', 'zh-en']
wmt18: ['cs-en', 'de-en', 'et-en', 'fi-en', 'kk-en', 'ru-en', 'tr-en', 'zh-en']
wmt19: ['cs-en', 'de-en', 'fi-en', 'gu-en', 'kk-en', 'lt-en', 'ru-en', 'zh-en', 'fr-de']
```
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/438/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/438/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/437
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/437/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/437/comments
|
https://api.github.com/repos/huggingface/datasets/issues/437/events
|
https://github.com/huggingface/datasets/pull/437
| 665,597,176
|
MDExOlB1bGxSZXF1ZXN0NDU2NjIzNjc3
| 437
|
Fix XTREME PAN-X loading
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"events_url": "https://api.github.com/users/lvwerra/events{/privacy}",
"followers_url": "https://api.github.com/users/lvwerra/followers",
"following_url": "https://api.github.com/users/lvwerra/following{/other_user}",
"gists_url": "https://api.github.com/users/lvwerra/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lvwerra",
"id": 8264887,
"login": "lvwerra",
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"organizations_url": "https://api.github.com/users/lvwerra/orgs",
"received_events_url": "https://api.github.com/users/lvwerra/received_events",
"repos_url": "https://api.github.com/users/lvwerra/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lvwerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lvwerra/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lvwerra",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 4
|
2020-07-25 14:44:57+00:00
|
2020-07-30 08:28:15+00:00
|
2020-07-30 08:28:15+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/437.diff",
"html_url": "https://github.com/huggingface/datasets/pull/437",
"merged_at": "2020-07-30T08:28:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/437.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/437"
}
|
Hi 🤗
In response to the discussion in #425 @lewtun and I made some fixes to the repo. In the original XTREME implementation the PAN-X dataset for named entity recognition loaded each word/tag pair as a single row and the sentence relation was lost. With the fix each row contains the list of all words in a single sentence and their NER tags. This is also in agreement with the [NER example](https://github.com/huggingface/transformers/tree/master/examples/token-classification) in the transformers repo.
With the fix the output of the dataset should look as follows:
```python
>>> dataset = load_dataset("xtreme", "PAN-X.en", data_dir='./data')
>>> dataset['train'][0]
{'words': ['R.H.', 'Saunders', '(', 'St.', 'Lawrence', 'River', ')', '(', '968', 'MW', ')'],
'ner_tags': ['B-ORG', 'I-ORG', 'O', 'B-ORG', 'I-ORG', 'I-ORG', 'O', 'O', 'O', 'O', 'O'],
'langs': ['en', 'en', 'en', 'en', 'en', 'en', 'en', 'en', 'en', 'en', 'en']}
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/437/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/437/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/436
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/436/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/436/comments
|
https://api.github.com/repos/huggingface/datasets/issues/436/events
|
https://github.com/huggingface/datasets/issues/436
| 665,582,167
|
MDU6SXNzdWU2NjU1ODIxNjc=
| 436
|
Google Colab - load_dataset - PyArrow exception
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/431890?v=4",
"events_url": "https://api.github.com/users/nsankar/events{/privacy}",
"followers_url": "https://api.github.com/users/nsankar/followers",
"following_url": "https://api.github.com/users/nsankar/following{/other_user}",
"gists_url": "https://api.github.com/users/nsankar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nsankar",
"id": 431890,
"login": "nsankar",
"node_id": "MDQ6VXNlcjQzMTg5MA==",
"organizations_url": "https://api.github.com/users/nsankar/orgs",
"received_events_url": "https://api.github.com/users/nsankar/received_events",
"repos_url": "https://api.github.com/users/nsankar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nsankar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nsankar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nsankar",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 9
|
2020-07-25 13:05:20+00:00
|
2020-08-20 08:08:18+00:00
|
2020-08-20 08:08:18+00:00
|
NONE
| null | null | null | null |
With latest PyArrow 1.0.0 installed, I get the following exception . Restarting colab has the same issue
ImportWarning: To use `nlp`, the module `pyarrow>=0.16.0` is required, and the current version of `pyarrow` doesn't match this condition. If you are running this in a Google Colab, you should probably just restart the runtime to use the right version of `pyarrow`.
The error goes only when I install version 0.16.0
i.e. !pip install pyarrow==0.16.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/436/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/436/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/435
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/435/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/435/comments
|
https://api.github.com/repos/huggingface/datasets/issues/435/events
|
https://github.com/huggingface/datasets/issues/435
| 665,507,141
|
MDU6SXNzdWU2NjU1MDcxNDE=
| 435
|
ImportWarning for pyarrow 1.0.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/18187806?v=4",
"events_url": "https://api.github.com/users/HanGuo97/events{/privacy}",
"followers_url": "https://api.github.com/users/HanGuo97/followers",
"following_url": "https://api.github.com/users/HanGuo97/following{/other_user}",
"gists_url": "https://api.github.com/users/HanGuo97/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/HanGuo97",
"id": 18187806,
"login": "HanGuo97",
"node_id": "MDQ6VXNlcjE4MTg3ODA2",
"organizations_url": "https://api.github.com/users/HanGuo97/orgs",
"received_events_url": "https://api.github.com/users/HanGuo97/received_events",
"repos_url": "https://api.github.com/users/HanGuo97/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/HanGuo97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HanGuo97/subscriptions",
"type": "User",
"url": "https://api.github.com/users/HanGuo97",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 4
|
2020-07-25 03:44:39+00:00
|
2020-09-08 17:57:15+00:00
|
2020-08-03 16:37:32+00:00
|
NONE
| null | null | null | null |
The following PR raised ImportWarning at `pyarrow ==1.0.0` https://github.com/huggingface/nlp/pull/265/files
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/18187806?v=4",
"events_url": "https://api.github.com/users/HanGuo97/events{/privacy}",
"followers_url": "https://api.github.com/users/HanGuo97/followers",
"following_url": "https://api.github.com/users/HanGuo97/following{/other_user}",
"gists_url": "https://api.github.com/users/HanGuo97/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/HanGuo97",
"id": 18187806,
"login": "HanGuo97",
"node_id": "MDQ6VXNlcjE4MTg3ODA2",
"organizations_url": "https://api.github.com/users/HanGuo97/orgs",
"received_events_url": "https://api.github.com/users/HanGuo97/received_events",
"repos_url": "https://api.github.com/users/HanGuo97/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/HanGuo97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HanGuo97/subscriptions",
"type": "User",
"url": "https://api.github.com/users/HanGuo97",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/435/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/435/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/434
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/434/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/434/comments
|
https://api.github.com/repos/huggingface/datasets/issues/434/events
|
https://github.com/huggingface/datasets/pull/434
| 665,477,638
|
MDExOlB1bGxSZXF1ZXN0NDU2NTM3Njgz
| 434
|
Fixed check for pyarrow
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/58701810?v=4",
"events_url": "https://api.github.com/users/nadahlberg/events{/privacy}",
"followers_url": "https://api.github.com/users/nadahlberg/followers",
"following_url": "https://api.github.com/users/nadahlberg/following{/other_user}",
"gists_url": "https://api.github.com/users/nadahlberg/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nadahlberg",
"id": 58701810,
"login": "nadahlberg",
"node_id": "MDQ6VXNlcjU4NzAxODEw",
"organizations_url": "https://api.github.com/users/nadahlberg/orgs",
"received_events_url": "https://api.github.com/users/nadahlberg/received_events",
"repos_url": "https://api.github.com/users/nadahlberg/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nadahlberg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nadahlberg/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nadahlberg",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-07-25 00:16:53+00:00
|
2020-07-25 06:36:34+00:00
|
2020-07-25 06:36:34+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/434.diff",
"html_url": "https://github.com/huggingface/datasets/pull/434",
"merged_at": "2020-07-25T06:36:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/434.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/434"
}
|
Fix check for pyarrow in __init__.py. Previously would raise an error for pyarrow >= 1.0.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/434/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/434/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/433
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/433/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/433/comments
|
https://api.github.com/repos/huggingface/datasets/issues/433/events
|
https://github.com/huggingface/datasets/issues/433
| 665,311,025
|
MDU6SXNzdWU2NjUzMTEwMjU=
| 433
|
How to reuse functionality of a (generic) dataset?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/3375489?v=4",
"events_url": "https://api.github.com/users/ArneBinder/events{/privacy}",
"followers_url": "https://api.github.com/users/ArneBinder/followers",
"following_url": "https://api.github.com/users/ArneBinder/following{/other_user}",
"gists_url": "https://api.github.com/users/ArneBinder/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ArneBinder",
"id": 3375489,
"login": "ArneBinder",
"node_id": "MDQ6VXNlcjMzNzU0ODk=",
"organizations_url": "https://api.github.com/users/ArneBinder/orgs",
"received_events_url": "https://api.github.com/users/ArneBinder/received_events",
"repos_url": "https://api.github.com/users/ArneBinder/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ArneBinder/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArneBinder/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ArneBinder",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 4
|
2020-07-24 17:27:37+00:00
|
2022-10-04 17:59:34+00:00
|
2022-10-04 17:59:33+00:00
|
NONE
| null | null | null | null |
I have written a generic dataset for corpora created with the Brat annotation tool ([specification](https://brat.nlplab.org/standoff.html), [dataset code](https://github.com/ArneBinder/nlp/blob/brat/datasets/brat/brat.py)). Now I wonder how to use that to create specific dataset instances. What's the recommended way to reuse formats and loading functionality for datasets with a common format?
In my case, it took a bit of time to create the Brat dataset and I think others would appreciate to not have to think about that again. Also, I assume there are other formats (e.g. conll) that are widely used, so having this would really ease dataset onboarding and adoption of the library.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/433/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/433/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/432
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/432/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/432/comments
|
https://api.github.com/repos/huggingface/datasets/issues/432/events
|
https://github.com/huggingface/datasets/pull/432
| 665,234,340
|
MDExOlB1bGxSZXF1ZXN0NDU2MzQxNDk3
| 432
|
Fix handling of config files while loading datasets from multiple processes
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/99543?v=4",
"events_url": "https://api.github.com/users/orsharir/events{/privacy}",
"followers_url": "https://api.github.com/users/orsharir/followers",
"following_url": "https://api.github.com/users/orsharir/following{/other_user}",
"gists_url": "https://api.github.com/users/orsharir/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/orsharir",
"id": 99543,
"login": "orsharir",
"node_id": "MDQ6VXNlcjk5NTQz",
"organizations_url": "https://api.github.com/users/orsharir/orgs",
"received_events_url": "https://api.github.com/users/orsharir/received_events",
"repos_url": "https://api.github.com/users/orsharir/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/orsharir/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/orsharir/subscriptions",
"type": "User",
"url": "https://api.github.com/users/orsharir",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 4
|
2020-07-24 15:10:57+00:00
|
2020-08-01 17:11:42+00:00
|
2020-07-30 08:25:28+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/432.diff",
"html_url": "https://github.com/huggingface/datasets/pull/432",
"merged_at": "2020-07-30T08:25:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/432.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/432"
}
|
When loading shards on several processes, each process upon loading the dataset will overwrite dataset_infos.json in <package path>/datasets/<dataset name>/<hash>/dataset_infos.json. It does so every time, even when the target file already exists and is identical. Because multiple processes rewrite the same file in parallel, it creates a race condition when a process tries to load the file, often resulting in a JSON decoding exception because the file is only partially written.
This pull requests partially address this by comparing if the files are already identical before copying over the downloaded copy to the cached destination. There's still a race condition, but now it's less likely to occur if some basic precautions are taken by the library user, e.g., download all datasets to cache before spawning multiple processes.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/432/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/432/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/431
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/431/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/431/comments
|
https://api.github.com/repos/huggingface/datasets/issues/431/events
|
https://github.com/huggingface/datasets/pull/431
| 665,044,416
|
MDExOlB1bGxSZXF1ZXN0NDU2MTgyNDE2
| 431
|
Specify split post processing + Add post processing resources downloading
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 4
|
2020-07-24 09:29:19+00:00
|
2020-07-31 09:05:04+00:00
|
2020-07-31 09:05:03+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/431.diff",
"html_url": "https://github.com/huggingface/datasets/pull/431",
"merged_at": "2020-07-31T09:05:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/431.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/431"
}
|
Previously if you tried to do
```python
from nlp import load_dataset
wiki = load_dataset("wiki_dpr", "psgs_w100_with_nq_embeddings", split="train[:100]", with_index=True)
```
Then you'd get an error `Index size should match Dataset size...`
This was because it was trying to use the full index (21M elements).
To fix that I made it so post processing resources can be named according to the split.
I'm going to add tests on post processing too.
Note that the CI will fail as I added a new argument in `_post_processing_resources`: the AWS version of wiki_dpr fails, and there's also an error telling that it is not synced (it'll be synced once it's merged):
```
=========================== short test summary info ============================
FAILED tests/test_dataset_common.py::AWSDatasetTest::test_load_dataset_wiki_dpr
FAILED tests/test_hf_gcp.py::TestDatasetSynced::test_script_synced_with_s3_wiki_dpr
```
EDIT: I did a change to ignore the script hash to locate the arrow files on GCS, so I removed the sync test. It was there just because of the hash logic for files on GCS
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/431/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/431/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/430
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/430/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/430/comments
|
https://api.github.com/repos/huggingface/datasets/issues/430/events
|
https://github.com/huggingface/datasets/pull/430
| 664,583,837
|
MDExOlB1bGxSZXF1ZXN0NDU1ODAxOTI2
| 430
|
add DatasetDict
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 4
|
2020-07-23 15:43:49+00:00
|
2020-08-04 01:01:53+00:00
|
2020-07-29 09:06:22+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/430.diff",
"html_url": "https://github.com/huggingface/datasets/pull/430",
"merged_at": "2020-07-29T09:06:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/430.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/430"
}
|
## Add DatasetDict
### Overview
When you call `load_dataset` it can return a dictionary of datasets if there are several splits (train/test for example).
If you wanted to apply dataset transforms you had to iterate over each split and apply the transform.
Instead of returning a dict, it now returns a `nlp.DatasetDict` object which inherits from dict and contains the same data as before, except that now users can call dataset transforms directly from the output, and they'll be applied on each split.
Before:
```python
from nlp import load_dataset
squad = load_dataset("squad")
print(squad.keys())
# dict_keys(['train', 'validation'])
squad = {
split_name: dataset.map(my_func) for split_name, dataset in squad.items()
}
print(squad.keys())
# dict_keys(['train', 'validation'])
```
Now:
```python
from nlp import load_dataset
squad = load_dataset("squad")
print(squad.keys())
# dict_keys(['train', 'validation'])
squad = squad.map(my_func)
print(squad.keys())
# dict_keys(['train', 'validation'])
```
### Dataset transforms
`nlp.DatasetDict` implements the following dataset transforms:
- map
- filter
- sort
- shuffle
### Arguments
The arguments of the methods are the same except for split-specific arguments like `cache_file_name`.
For such arguments, the expected input is a dictionary `{split_name: argument_value}`
It concerns:
- `cache_file_name` in map, filter, sort, shuffle
- `seed` and `generator` in shuffle
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/430/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/430/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/429
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/429/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/429/comments
|
https://api.github.com/repos/huggingface/datasets/issues/429/events
|
https://github.com/huggingface/datasets/pull/429
| 664,412,137
|
MDExOlB1bGxSZXF1ZXN0NDU1NjU2MDk5
| 429
|
mlsum
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/36986299?v=4",
"events_url": "https://api.github.com/users/RachelKer/events{/privacy}",
"followers_url": "https://api.github.com/users/RachelKer/followers",
"following_url": "https://api.github.com/users/RachelKer/following{/other_user}",
"gists_url": "https://api.github.com/users/RachelKer/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/RachelKer",
"id": 36986299,
"login": "RachelKer",
"node_id": "MDQ6VXNlcjM2OTg2Mjk5",
"organizations_url": "https://api.github.com/users/RachelKer/orgs",
"received_events_url": "https://api.github.com/users/RachelKer/received_events",
"repos_url": "https://api.github.com/users/RachelKer/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/RachelKer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RachelKer/subscriptions",
"type": "User",
"url": "https://api.github.com/users/RachelKer",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 6
|
2020-07-23 11:52:39+00:00
|
2020-07-31 11:46:20+00:00
|
2020-07-31 11:46:20+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/429.diff",
"html_url": "https://github.com/huggingface/datasets/pull/429",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/429.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/429"
}
|
Hello,
The tests for the load_real_data fail, as there is no default language subset to download it looks for a file that does not exist. This bug does not happen when using the load_dataset function, as it asks you to specify a language if you do not, so I submit this PR anyway. The dataset is avalaible on : https://gitlab.lip6.fr/scialom/mlsum_data
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/36986299?v=4",
"events_url": "https://api.github.com/users/RachelKer/events{/privacy}",
"followers_url": "https://api.github.com/users/RachelKer/followers",
"following_url": "https://api.github.com/users/RachelKer/following{/other_user}",
"gists_url": "https://api.github.com/users/RachelKer/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/RachelKer",
"id": 36986299,
"login": "RachelKer",
"node_id": "MDQ6VXNlcjM2OTg2Mjk5",
"organizations_url": "https://api.github.com/users/RachelKer/orgs",
"received_events_url": "https://api.github.com/users/RachelKer/received_events",
"repos_url": "https://api.github.com/users/RachelKer/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/RachelKer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RachelKer/subscriptions",
"type": "User",
"url": "https://api.github.com/users/RachelKer",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/429/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/429/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/428
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/428/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/428/comments
|
https://api.github.com/repos/huggingface/datasets/issues/428/events
|
https://github.com/huggingface/datasets/pull/428
| 664,367,086
|
MDExOlB1bGxSZXF1ZXN0NDU1NjE3Nzcy
| 428
|
fix concatenate_datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-23 10:30:59+00:00
|
2020-07-23 10:35:00+00:00
|
2020-07-23 10:34:58+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/428.diff",
"html_url": "https://github.com/huggingface/datasets/pull/428",
"merged_at": "2020-07-23T10:34:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/428.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/428"
}
|
`concatenate_datatsets` used to test that the different`nlp.Dataset.schema` match, but this attribute was removed in #423
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/428/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/428/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/427
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/427/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/427/comments
|
https://api.github.com/repos/huggingface/datasets/issues/427/events
|
https://github.com/huggingface/datasets/pull/427
| 664,341,623
|
MDExOlB1bGxSZXF1ZXN0NDU1NTk1Nzc3
| 427
|
Allow sequence features for beam + add processed Natural Questions
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-23 09:52:41+00:00
|
2020-07-23 13:09:30+00:00
|
2020-07-23 13:09:29+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/427.diff",
"html_url": "https://github.com/huggingface/datasets/pull/427",
"merged_at": "2020-07-23T13:09:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/427.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/427"
}
|
## Allow Sequence features for Beam Datasets + add Natural Questions
### The issue
The steps of beam datasets processing is the following:
- download the source files and send them in a remote storage (gcs)
- process the files using a beam runner (dataflow)
- save output in remote storage (gcs)
- convert output to arrow in remote storage (gcs)
However it wasn't possible to process `natural_questions` because apache beam's processing outputs parquet files, and it's not yet possible to read parquet files with list features.
### The proposed solution
To allow sequence features for beam I added a workaround that serializes the values using `json.dumps`, so that we end up with strings instead of the original features. Then when the arrow file is created, the serialized objects are transformed back to normal with `json.loads`. Not sure if there's a better way to do it.
### Natural Questions
I was able to process NQ with it, and so I added the json infos file in this PR too.
The processed arrow files are also stored in gcs.
It allows you to load NQ with
```python
from nlp import load_dataset
nq = load_dataset("natural_questions") # download the 90GB arrow files from gcs and return the dataset
```
### Tests
I added a test case to make sure it works as expected.
Note that the CI will fail because I am updating `natural_questions.py`: it's not synced with the script on S3. It will be synced as soon as this PR is merged.
```
=========================== short test summary info ============================
FAILED tests/test_hf_gcp.py::TestDatasetOnHfGcp::test_script_synced_with_s3_natural_questions/default
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 1,
"laugh": 0,
"rocket": 3,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/427/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/427/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/426
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/426/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/426/comments
|
https://api.github.com/repos/huggingface/datasets/issues/426/events
|
https://github.com/huggingface/datasets/issues/426
| 664,203,897
|
MDU6SXNzdWU2NjQyMDM4OTc=
| 426
|
[FEATURE REQUEST] Multiprocessing with for dataset.map, dataset.filter
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2000204?v=4",
"events_url": "https://api.github.com/users/timothyjlaurent/events{/privacy}",
"followers_url": "https://api.github.com/users/timothyjlaurent/followers",
"following_url": "https://api.github.com/users/timothyjlaurent/following{/other_user}",
"gists_url": "https://api.github.com/users/timothyjlaurent/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/timothyjlaurent",
"id": 2000204,
"login": "timothyjlaurent",
"node_id": "MDQ6VXNlcjIwMDAyMDQ=",
"organizations_url": "https://api.github.com/users/timothyjlaurent/orgs",
"received_events_url": "https://api.github.com/users/timothyjlaurent/received_events",
"repos_url": "https://api.github.com/users/timothyjlaurent/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/timothyjlaurent/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/timothyjlaurent/subscriptions",
"type": "User",
"url": "https://api.github.com/users/timothyjlaurent",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
| null |
[] | null | 6
|
2020-07-23 05:00:41+00:00
|
2021-03-12 09:34:12+00:00
|
2020-09-07 14:48:04+00:00
|
NONE
| null | null | null | null |
It would be nice to be able to speed up `dataset.map` or `dataset.filter`. Perhaps this is as easy as sharding the dataset sending each shard to a process/thread/dask pool and using the new `nlp.concatenate_dataset()` function to join them all together?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/426/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/426/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/425
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/425/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/425/comments
|
https://api.github.com/repos/huggingface/datasets/issues/425/events
|
https://github.com/huggingface/datasets/issues/425
| 664,029,848
|
MDU6SXNzdWU2NjQwMjk4NDg=
| 425
|
Correct data structure for PAN-X task in XTREME dataset?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 7
|
2020-07-22 20:29:20+00:00
|
2020-08-02 13:30:34+00:00
|
2020-08-02 13:30:34+00:00
|
MEMBER
| null | null | null | null |
Hi 🤗 team!
## Description of the problem
Thanks to the fix from #416 I am now able to load the NER task in the XTREME dataset as follows:
```python
from nlp import load_dataset
# AmazonPhotos.zip is located in data/
dataset = load_dataset("xtreme", "PAN-X.en", data_dir='./data')
dataset_train = dataset['train']
```
However, I am not sure that `load_dataset()` is returning the correct data structure for NER.
Currently, every row in `dataset_train` is of the form
```python
{'word': str, 'ner_tag': str, 'lang': str}
```
but I think we actually want something like
```python
{'words': List[str], 'ner_tags': List[str], 'langs': List[str]}
```
so that each row corresponds to a _sequence_ of words associated with each example. With the current data structure I do not think it is possible to transform `dataset_train` into a form suitable for training because we do not know the boundaries between examples.
Indeed, [this line](https://github.com/google-research/xtreme/blob/522434d1aece34131d997a97ce7e9242a51a688a/third_party/utils_tag.py#L58) in the XTREME repo, processes the texts as lists of sentences, tags, and languages.
## Proposed solution
Replace
```python
with open(filepath) as f:
data = csv.reader(f, delimiter="\t", quoting=csv.QUOTE_NONE)
for id_, row in enumerate(data):
if row:
lang, word = row[0].split(":")[0], row[0].split(":")[1]
tag = row[1]
yield id_, {"word": word, "ner_tag": tag, "lang": lang}
```
from [these lines](https://github.com/huggingface/nlp/blob/ce7d3a1d630b78fe27188d1706f3ea980e8eec43/datasets/xtreme/xtreme.py#L881-L887) of the `_generate_examples()` function with something like
```python
guid_index = 1
with open(filepath, encoding="utf-8") as f:
words = []
ner_tags = []
langs = []
for line in f:
if line.startswith("-DOCSTART-") or line == "" or line == "\n":
if words:
yield guid_index, {"words": words, "ner_tags": ner_tags, "langs": langs}
guid_index += 1
words = []
ner_tags = []
else:
# pan-x data is tab separated
splits = line.split("\t")
# strip out en: prefix
langs.append(splits[0][:2])
words.append(splits[0][3:])
if len(splits) > 1:
labels.append(splits[-1].replace("\n", ""))
else:
# examples have no label in test set
labels.append("O")
```
If you agree, me or @lvwerra would be happy to implement this and create a PR.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun",
"user_view_type": "public"
}
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/425/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/425/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/424
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/424/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/424/comments
|
https://api.github.com/repos/huggingface/datasets/issues/424/events
|
https://github.com/huggingface/datasets/pull/424
| 663,858,552
|
MDExOlB1bGxSZXF1ZXN0NDU1MTk4MTY0
| 424
|
Web of science
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-22 15:38:31+00:00
|
2020-07-23 14:27:58+00:00
|
2020-07-23 14:27:56+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/424.diff",
"html_url": "https://github.com/huggingface/datasets/pull/424",
"merged_at": "2020-07-23T14:27:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/424.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/424"
}
|
this PR adds the WebofScience dataset
#353
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/424/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/424/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/423
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/423/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/423/comments
|
https://api.github.com/repos/huggingface/datasets/issues/423/events
|
https://github.com/huggingface/datasets/pull/423
| 663,079,359
|
MDExOlB1bGxSZXF1ZXN0NDU0NTU4OTA0
| 423
|
Change features vs schema logic
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-07-21 14:52:47+00:00
|
2020-07-25 09:08:34+00:00
|
2020-07-23 10:15:17+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/423.diff",
"html_url": "https://github.com/huggingface/datasets/pull/423",
"merged_at": "2020-07-23T10:15:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/423.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/423"
}
|
## New logic for `nlp.Features` in datasets
Previously, it was confusing to have `features` and pyarrow's `schema` in `nlp.Dataset`.
However `features` is supposed to be the front-facing object to define the different fields of a dataset, while `schema` is only used to write arrow files.
Changes:
- Remove `schema` field in `nlp.Dataset`
- Make `features` the source of truth to read/write examples
- `features` can no longer be `None` in `nlp.Dataset`
- Update `features` after each dataset transform such as `nlp.Dataset.map`
Todo: change the tests to take these changes into account
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/423/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/423/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/422
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/422/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/422/comments
|
https://api.github.com/repos/huggingface/datasets/issues/422/events
|
https://github.com/huggingface/datasets/pull/422
| 663,028,497
|
MDExOlB1bGxSZXF1ZXN0NDU0NTE3MDU2
| 422
|
- Corrected encoding for IMDB.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/25091538?v=4",
"events_url": "https://api.github.com/users/ghazi-f/events{/privacy}",
"followers_url": "https://api.github.com/users/ghazi-f/followers",
"following_url": "https://api.github.com/users/ghazi-f/following{/other_user}",
"gists_url": "https://api.github.com/users/ghazi-f/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ghazi-f",
"id": 25091538,
"login": "ghazi-f",
"node_id": "MDQ6VXNlcjI1MDkxNTM4",
"organizations_url": "https://api.github.com/users/ghazi-f/orgs",
"received_events_url": "https://api.github.com/users/ghazi-f/received_events",
"repos_url": "https://api.github.com/users/ghazi-f/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ghazi-f/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghazi-f/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ghazi-f",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-21 13:46:59+00:00
|
2020-07-22 16:02:53+00:00
|
2020-07-22 16:02:53+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/422.diff",
"html_url": "https://github.com/huggingface/datasets/pull/422",
"merged_at": "2020-07-22T16:02:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/422.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/422"
}
|
The preparation phase (after the download phase) crashed on windows because of charmap encoding not being able to decode certain characters. This change suggested in Issue #347 fixes it for the IMDB dataset.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/422/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/422/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/421
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/421/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/421/comments
|
https://api.github.com/repos/huggingface/datasets/issues/421/events
|
https://github.com/huggingface/datasets/pull/421
| 662,213,864
|
MDExOlB1bGxSZXF1ZXN0NDUzNzkzMzQ1
| 421
|
Style change
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35500534?v=4",
"events_url": "https://api.github.com/users/lordtt13/events{/privacy}",
"followers_url": "https://api.github.com/users/lordtt13/followers",
"following_url": "https://api.github.com/users/lordtt13/following{/other_user}",
"gists_url": "https://api.github.com/users/lordtt13/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lordtt13",
"id": 35500534,
"login": "lordtt13",
"node_id": "MDQ6VXNlcjM1NTAwNTM0",
"organizations_url": "https://api.github.com/users/lordtt13/orgs",
"received_events_url": "https://api.github.com/users/lordtt13/received_events",
"repos_url": "https://api.github.com/users/lordtt13/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lordtt13/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lordtt13/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lordtt13",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-07-20 20:08:29+00:00
|
2020-07-22 16:08:40+00:00
|
2020-07-22 16:08:39+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/421.diff",
"html_url": "https://github.com/huggingface/datasets/pull/421",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/421.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/421"
}
|
make quality and make style ran on scripts
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/421/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/421/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/420
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/420/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/420/comments
|
https://api.github.com/repos/huggingface/datasets/issues/420/events
|
https://github.com/huggingface/datasets/pull/420
| 662,029,782
|
MDExOlB1bGxSZXF1ZXN0NDUzNjI5OTk2
| 420
|
Better handle nested features
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-20 16:44:13+00:00
|
2020-07-21 08:20:49+00:00
|
2020-07-21 08:09:52+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/420.diff",
"html_url": "https://github.com/huggingface/datasets/pull/420",
"merged_at": "2020-07-21T08:09:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/420.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/420"
}
|
Changes:
- added arrow schema to features conversion (it's going to be useful to fix #342 )
- make flatten handle deep features (useful for tfrecords conversion in #339 )
- add tests for flatten and features conversions
- the reader now returns the kwargs to instantiate a Dataset (fix circular dependencies)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/420/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/420/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/419
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/419/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/419/comments
|
https://api.github.com/repos/huggingface/datasets/issues/419/events
|
https://github.com/huggingface/datasets/pull/419
| 661,974,747
|
MDExOlB1bGxSZXF1ZXN0NDUzNTgxNzQz
| 419
|
EmoContext dataset add
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35500534?v=4",
"events_url": "https://api.github.com/users/lordtt13/events{/privacy}",
"followers_url": "https://api.github.com/users/lordtt13/followers",
"following_url": "https://api.github.com/users/lordtt13/following{/other_user}",
"gists_url": "https://api.github.com/users/lordtt13/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lordtt13",
"id": 35500534,
"login": "lordtt13",
"node_id": "MDQ6VXNlcjM1NTAwNTM0",
"organizations_url": "https://api.github.com/users/lordtt13/orgs",
"received_events_url": "https://api.github.com/users/lordtt13/received_events",
"repos_url": "https://api.github.com/users/lordtt13/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lordtt13/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lordtt13/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lordtt13",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-20 15:48:45+00:00
|
2020-07-24 08:22:01+00:00
|
2020-07-24 08:22:00+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/419.diff",
"html_url": "https://github.com/huggingface/datasets/pull/419",
"merged_at": "2020-07-24T08:22:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/419.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/419"
}
|
EmoContext Dataset add
Signed-off-by: lordtt13 <[email protected]>
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/419/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/419/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/418
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/418/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/418/comments
|
https://api.github.com/repos/huggingface/datasets/issues/418/events
|
https://github.com/huggingface/datasets/issues/418
| 661,914,873
|
MDU6SXNzdWU2NjE5MTQ4NzM=
| 418
|
Addition of google drive links to dl_manager
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35500534?v=4",
"events_url": "https://api.github.com/users/lordtt13/events{/privacy}",
"followers_url": "https://api.github.com/users/lordtt13/followers",
"following_url": "https://api.github.com/users/lordtt13/following{/other_user}",
"gists_url": "https://api.github.com/users/lordtt13/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lordtt13",
"id": 35500534,
"login": "lordtt13",
"node_id": "MDQ6VXNlcjM1NTAwNTM0",
"organizations_url": "https://api.github.com/users/lordtt13/orgs",
"received_events_url": "https://api.github.com/users/lordtt13/received_events",
"repos_url": "https://api.github.com/users/lordtt13/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lordtt13/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lordtt13/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lordtt13",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-07-20 14:52:02+00:00
|
2020-07-20 15:39:32+00:00
|
2020-07-20 15:39:32+00:00
|
CONTRIBUTOR
| null | null | null | null |
Hello there, I followed the template to create a download script of my own, which works fine for me, although I had to shun the dl_manager because it was downloading nothing from the drive links and instead use gdown.
This is the script for me:
```python
class EmoConfig(nlp.BuilderConfig):
"""BuilderConfig for SQUAD."""
def __init__(self, **kwargs):
"""BuilderConfig for EmoContext.
Args:
**kwargs: keyword arguments forwarded to super.
"""
super(EmoConfig, self).__init__(**kwargs)
_TEST_URL = "https://drive.google.com/file/d/1Hn5ytHSSoGOC4sjm3wYy0Dh0oY_oXBbb/view?usp=sharing"
_TRAIN_URL = "https://drive.google.com/file/d/12Uz59TYg_NtxOy7SXraYeXPMRT7oaO7X/view?usp=sharing"
class EmoDataset(nlp.GeneratorBasedBuilder):
""" SemEval-2019 Task 3: EmoContext Contextual Emotion Detection in Text. Version 1.0.0 """
VERSION = nlp.Version("1.0.0")
force = False
def _info(self):
return nlp.DatasetInfo(
description=_DESCRIPTION,
features=nlp.Features(
{
"text": nlp.Value("string"),
"label": nlp.features.ClassLabel(names=["others", "happy", "sad", "angry"]),
}
),
supervised_keys=None,
homepage="https://www.aclweb.org/anthology/S19-2005/",
citation=_CITATION,
)
def _get_drive_url(self, url):
base_url = 'https://drive.google.com/uc?id='
split_url = url.split('/')
return base_url + split_url[5]
def _split_generators(self, dl_manager):
"""Returns SplitGenerators."""
if(not os.path.exists("emo-train.json") or self.force):
gdown.download(self._get_drive_url(_TRAIN_URL), "emo-train.json", quiet = True)
if(not os.path.exists("emo-test.json") or self.force):
gdown.download(self._get_drive_url(_TEST_URL), "emo-test.json", quiet = True)
return [
nlp.SplitGenerator(
name=nlp.Split.TRAIN,
gen_kwargs={
"filepath": "emo-train.json",
"split": "train",
},
),
nlp.SplitGenerator(
name=nlp.Split.TEST,
gen_kwargs={"filepath": "emo-test.json", "split": "test"},
),
]
def _generate_examples(self, filepath, split):
""" Yields examples. """
with open(filepath, 'rb') as f:
data = json.load(f)
for id_, text, label in zip(data["text"].keys(), data["text"].values(), data["Label"].values()):
yield id_, {
"text": text,
"label": label,
}
```
Can someone help me in adding gdrive links to be used with default dl_manager or adding gdown as another dl_manager, because I'd like to add this dataset to nlp's official database.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35500534?v=4",
"events_url": "https://api.github.com/users/lordtt13/events{/privacy}",
"followers_url": "https://api.github.com/users/lordtt13/followers",
"following_url": "https://api.github.com/users/lordtt13/following{/other_user}",
"gists_url": "https://api.github.com/users/lordtt13/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lordtt13",
"id": 35500534,
"login": "lordtt13",
"node_id": "MDQ6VXNlcjM1NTAwNTM0",
"organizations_url": "https://api.github.com/users/lordtt13/orgs",
"received_events_url": "https://api.github.com/users/lordtt13/received_events",
"repos_url": "https://api.github.com/users/lordtt13/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lordtt13/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lordtt13/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lordtt13",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/418/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/418/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/417
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/417/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/417/comments
|
https://api.github.com/repos/huggingface/datasets/issues/417/events
|
https://github.com/huggingface/datasets/pull/417
| 661,804,054
|
MDExOlB1bGxSZXF1ZXN0NDUzNDMyODE5
| 417
|
Fix docstrins multiple metrics instances
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-20 13:08:59+00:00
|
2020-07-22 09:51:00+00:00
|
2020-07-22 09:50:59+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/417.diff",
"html_url": "https://github.com/huggingface/datasets/pull/417",
"merged_at": "2020-07-22T09:50:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/417.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/417"
}
|
We change the docstrings of `nlp.Metric.compute`, `nlp.Metric.add` and `nlp.Metric.add_batch` depending on which metric is instantiated. However we had issues when instantiating multiple metrics (docstrings were duplicated).
This should fix #304
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/417/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/417/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/416
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/416/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/416/comments
|
https://api.github.com/repos/huggingface/datasets/issues/416/events
|
https://github.com/huggingface/datasets/pull/416
| 661,635,393
|
MDExOlB1bGxSZXF1ZXN0NDUzMjg1NTM4
| 416
|
Fix xtreme panx directory
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-07-20 10:09:17+00:00
|
2020-07-21 08:15:46+00:00
|
2020-07-21 08:15:44+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/416.diff",
"html_url": "https://github.com/huggingface/datasets/pull/416",
"merged_at": "2020-07-21T08:15:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/416.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/416"
}
|
Fix #412
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/416/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/416/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/415
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/415/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/415/comments
|
https://api.github.com/repos/huggingface/datasets/issues/415/events
|
https://github.com/huggingface/datasets/issues/415
| 660,687,076
|
MDU6SXNzdWU2NjA2ODcwNzY=
| 415
|
Something is wrong with WMT 19 kk-en dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/32014649?v=4",
"events_url": "https://api.github.com/users/ChenghaoMou/events{/privacy}",
"followers_url": "https://api.github.com/users/ChenghaoMou/followers",
"following_url": "https://api.github.com/users/ChenghaoMou/following{/other_user}",
"gists_url": "https://api.github.com/users/ChenghaoMou/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ChenghaoMou",
"id": 32014649,
"login": "ChenghaoMou",
"node_id": "MDQ6VXNlcjMyMDE0NjQ5",
"organizations_url": "https://api.github.com/users/ChenghaoMou/orgs",
"received_events_url": "https://api.github.com/users/ChenghaoMou/received_events",
"repos_url": "https://api.github.com/users/ChenghaoMou/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ChenghaoMou/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ChenghaoMou/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ChenghaoMou",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
open
| false
| null |
[] | null | 0
|
2020-07-19 08:18:51+00:00
|
2020-07-20 09:54:26+00:00
|
NaT
|
NONE
| null | null | null | null |
The translation in the `train` set does not look right:
```
>>>import nlp
>>>from nlp import load_dataset
>>>dataset = load_dataset('wmt19', 'kk-en')
>>>dataset["train"]["translation"][0]
{'kk': 'Trumpian Uncertainty', 'en': 'Трамптық белгісіздік'}
>>>dataset["validation"]["translation"][0]
{'kk': 'Ақша-несие саясатының сценарийін қайта жазсақ', 'en': 'Rewriting the Monetary-Policy Script'}
```
| null |
{
"+1": 0,
"-1": 0,
"confused": 1,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/415/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/415/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/414
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/414/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/414/comments
|
https://api.github.com/repos/huggingface/datasets/issues/414/events
|
https://github.com/huggingface/datasets/issues/414
| 660,654,013
|
MDU6SXNzdWU2NjA2NTQwMTM=
| 414
|
from_dict delete?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22817243?v=4",
"events_url": "https://api.github.com/users/hackerxiaobai/events{/privacy}",
"followers_url": "https://api.github.com/users/hackerxiaobai/followers",
"following_url": "https://api.github.com/users/hackerxiaobai/following{/other_user}",
"gists_url": "https://api.github.com/users/hackerxiaobai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hackerxiaobai",
"id": 22817243,
"login": "hackerxiaobai",
"node_id": "MDQ6VXNlcjIyODE3MjQz",
"organizations_url": "https://api.github.com/users/hackerxiaobai/orgs",
"received_events_url": "https://api.github.com/users/hackerxiaobai/received_events",
"repos_url": "https://api.github.com/users/hackerxiaobai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hackerxiaobai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hackerxiaobai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hackerxiaobai",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-07-19 07:08:36+00:00
|
2020-07-21 02:21:17+00:00
|
2020-07-21 02:21:17+00:00
|
NONE
| null | null | null | null |
AttributeError: type object 'Dataset' has no attribute 'from_dict'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22817243?v=4",
"events_url": "https://api.github.com/users/hackerxiaobai/events{/privacy}",
"followers_url": "https://api.github.com/users/hackerxiaobai/followers",
"following_url": "https://api.github.com/users/hackerxiaobai/following{/other_user}",
"gists_url": "https://api.github.com/users/hackerxiaobai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hackerxiaobai",
"id": 22817243,
"login": "hackerxiaobai",
"node_id": "MDQ6VXNlcjIyODE3MjQz",
"organizations_url": "https://api.github.com/users/hackerxiaobai/orgs",
"received_events_url": "https://api.github.com/users/hackerxiaobai/received_events",
"repos_url": "https://api.github.com/users/hackerxiaobai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hackerxiaobai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hackerxiaobai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hackerxiaobai",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/414/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/414/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/413
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/413/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/413/comments
|
https://api.github.com/repos/huggingface/datasets/issues/413/events
|
https://github.com/huggingface/datasets/issues/413
| 660,063,655
|
MDU6SXNzdWU2NjAwNjM2NTU=
| 413
|
Is there a way to download only NQ dev?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1563902?v=4",
"events_url": "https://api.github.com/users/tholor/events{/privacy}",
"followers_url": "https://api.github.com/users/tholor/followers",
"following_url": "https://api.github.com/users/tholor/following{/other_user}",
"gists_url": "https://api.github.com/users/tholor/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tholor",
"id": 1563902,
"login": "tholor",
"node_id": "MDQ6VXNlcjE1NjM5MDI=",
"organizations_url": "https://api.github.com/users/tholor/orgs",
"received_events_url": "https://api.github.com/users/tholor/received_events",
"repos_url": "https://api.github.com/users/tholor/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tholor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tholor/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tholor",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-07-18 10:28:23+00:00
|
2022-02-11 09:50:21+00:00
|
2022-02-11 09:50:21+00:00
|
NONE
| null | null | null | null |
Maybe I missed that in the docs, but is there a way to only download the dev set of natural questions (~1 GB)?
As we want to benchmark QA models on different datasets, I would like to avoid downloading the 41GB of training data.
I tried
```
dataset = nlp.load_dataset('natural_questions', split="validation", beam_runner="DirectRunner")
```
But this still triggered a big download of presumably the whole dataset. Is there any way of doing this or are splits / slicing options only available after downloading?
Thanks!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/413/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/413/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/412
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/412/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/412/comments
|
https://api.github.com/repos/huggingface/datasets/issues/412/events
|
https://github.com/huggingface/datasets/issues/412
| 660,047,139
|
MDU6SXNzdWU2NjAwNDcxMzk=
| 412
|
Unable to load XTREME dataset from disk
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-07-18 09:55:00+00:00
|
2020-07-21 08:15:44+00:00
|
2020-07-21 08:15:44+00:00
|
MEMBER
| null | null | null | null |
Hi 🤗 team!
## Description of the problem
Following the [docs](https://huggingface.co/nlp/loading_datasets.html?highlight=xtreme#manually-downloading-files) I'm trying to load the `PAN-X.fr` dataset from the [XTREME](https://github.com/google-research/xtreme) benchmark.
I have manually downloaded the `AmazonPhotos.zip` file from [here](https://www.amazon.com/clouddrive/share/d3KGCRCIYwhKJF0H3eWA26hjg2ZCRhjpEQtDL70FSBN?_encoding=UTF8&%2AVersion%2A=1&%2Aentries%2A=0&mgh=1) and am running into a `FileNotFoundError` when I point to the location of the dataset.
As far as I can tell, the problem is that `AmazonPhotos.zip` decompresses to `panx_dataset` and `load_dataset()` is not looking in the correct path:
```
# path where load_dataset is looking for fr.tar.gz
/root/.cache/huggingface/datasets/9b8c4f1578e45cb2539332c79738beb3b54afbcd842b079cabfd79e3ed6704f6/
# path where it actually exists
/root/.cache/huggingface/datasets/9b8c4f1578e45cb2539332c79738beb3b54afbcd842b079cabfd79e3ed6704f6/panx_dataset/
```
## Steps to reproduce the problem
1. Manually download the XTREME benchmark from [here](https://www.amazon.com/clouddrive/share/d3KGCRCIYwhKJF0H3eWA26hjg2ZCRhjpEQtDL70FSBN?_encoding=UTF8&%2AVersion%2A=1&%2Aentries%2A=0&mgh=1)
2. Run the following code snippet
```python
from nlp import load_dataset
# AmazonPhotos.zip is in the root of the folder
dataset = load_dataset("xtreme", "PAN-X.fr", data_dir='./')
```
3. Here is the stack trace
```
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-4-26786bb5fa93> in <module>
----> 1 dataset = load_dataset("xtreme", "PAN-X.fr", data_dir='./')
/usr/local/lib/python3.6/dist-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
522 download_mode=download_mode,
523 ignore_verifications=ignore_verifications,
--> 524 save_infos=save_infos,
525 )
526
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
430 verify_infos = not save_infos and not ignore_verifications
431 self._download_and_prepare(
--> 432 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
433 )
434 # Sync info
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
464 split_dict = SplitDict(dataset_name=self.name)
465 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 466 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
467 # Checksums verification
468 if verify_infos:
/usr/local/lib/python3.6/dist-packages/nlp/datasets/xtreme/b8c2ed3583a7a7ac60b503576dfed3271ac86757628897e945bd329c43b8a746/xtreme.py in _split_generators(self, dl_manager)
725 panx_dl_dir = dl_manager.extract(panx_path)
726 lang = self.config.name.split(".")[1]
--> 727 lang_folder = dl_manager.extract(os.path.join(panx_dl_dir, lang + ".tar.gz"))
728 return [
729 nlp.SplitGenerator(
/usr/local/lib/python3.6/dist-packages/nlp/utils/download_manager.py in extract(self, path_or_paths)
196 """
197 return map_nested(
--> 198 lambda path: cached_path(path, extract_compressed_file=True, force_extract=False), path_or_paths,
199 )
200
/usr/local/lib/python3.6/dist-packages/nlp/utils/py_utils.py in map_nested(function, data_struct, dict_only, map_tuple)
170 return tuple(mapped)
171 # Singleton
--> 172 return function(data_struct)
173
174
/usr/local/lib/python3.6/dist-packages/nlp/utils/download_manager.py in <lambda>(path)
196 """
197 return map_nested(
--> 198 lambda path: cached_path(path, extract_compressed_file=True, force_extract=False), path_or_paths,
199 )
200
/usr/local/lib/python3.6/dist-packages/nlp/utils/file_utils.py in cached_path(url_or_filename, download_config, **download_kwargs)
203 elif urlparse(url_or_filename).scheme == "":
204 # File, but it doesn't exist.
--> 205 raise FileNotFoundError("Local file {} doesn't exist".format(url_or_filename))
206 else:
207 # Something unknown
FileNotFoundError: Local file /root/.cache/huggingface/datasets/9b8c4f1578e45cb2539332c79738beb3b54afbcd842b079cabfd79e3ed6704f6/fr.tar.gz doesn't exist
```
## OS and hardware
```
- `nlp` version: 0.3.0
- Platform: Linux-4.15.0-72-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.4.0 (True)
- Tensorflow version (GPU?): 2.1.0 (True)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/412/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/412/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/411
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/411/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/411/comments
|
https://api.github.com/repos/huggingface/datasets/issues/411/events
|
https://github.com/huggingface/datasets/pull/411
| 659,393,398
|
MDExOlB1bGxSZXF1ZXN0NDUxMjQxOTQy
| 411
|
Sbf
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-17 16:19:45+00:00
|
2020-07-21 09:13:46+00:00
|
2020-07-21 09:13:45+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/411.diff",
"html_url": "https://github.com/huggingface/datasets/pull/411",
"merged_at": "2020-07-21T09:13:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/411.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/411"
}
|
This PR adds the Social Bias Frames Dataset (ACL 2020) .
dataset homepage: https://homes.cs.washington.edu/~msap/social-bias-frames/
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/411/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/411/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/410
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/410/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/410/comments
|
https://api.github.com/repos/huggingface/datasets/issues/410/events
|
https://github.com/huggingface/datasets/pull/410
| 659,242,871
|
MDExOlB1bGxSZXF1ZXN0NDUxMTEzMTI3
| 410
|
20newsgroup
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-17 13:07:57+00:00
|
2020-07-20 07:05:29+00:00
|
2020-07-20 07:05:28+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/410.diff",
"html_url": "https://github.com/huggingface/datasets/pull/410",
"merged_at": "2020-07-20T07:05:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/410.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/410"
}
|
Add 20Newsgroup dataset.
#353
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/410/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/410/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/409
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/409/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/409/comments
|
https://api.github.com/repos/huggingface/datasets/issues/409/events
|
https://github.com/huggingface/datasets/issues/409
| 659,128,611
|
MDU6SXNzdWU2NTkxMjg2MTE=
| 409
|
train_test_split error: 'dict' object has no attribute 'deepcopy'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20516801?v=4",
"events_url": "https://api.github.com/users/morganmcg1/events{/privacy}",
"followers_url": "https://api.github.com/users/morganmcg1/followers",
"following_url": "https://api.github.com/users/morganmcg1/following{/other_user}",
"gists_url": "https://api.github.com/users/morganmcg1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/morganmcg1",
"id": 20516801,
"login": "morganmcg1",
"node_id": "MDQ6VXNlcjIwNTE2ODAx",
"organizations_url": "https://api.github.com/users/morganmcg1/orgs",
"received_events_url": "https://api.github.com/users/morganmcg1/received_events",
"repos_url": "https://api.github.com/users/morganmcg1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/morganmcg1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/morganmcg1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/morganmcg1",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null | 2
|
2020-07-17 10:36:28+00:00
|
2020-07-21 14:34:52+00:00
|
2020-07-21 14:34:52+00:00
|
NONE
| null | null | null | null |
`train_test_split` is giving me an error when I try and call it:
`'dict' object has no attribute 'deepcopy'`
## To reproduce
```
dataset = load_dataset('glue', 'mrpc', split='train')
dataset = dataset.train_test_split(test_size=0.2)
```
## Full Stacktrace
```
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-12-feb740dbec9a> in <module>
1 dataset = load_dataset('glue', 'mrpc', split='train')
----> 2 dataset = dataset.train_test_split(test_size=0.2)
~/anaconda3/envs/fastai2_me/lib/python3.7/site-packages/nlp/arrow_dataset.py in train_test_split(self, test_size, train_size, shuffle, seed, generator, keep_in_memory, load_from_cache_file, train_cache_file_name, test_cache_file_name, writer_batch_size)
1032 "writer_batch_size": writer_batch_size,
1033 }
-> 1034 train_kwargs = cache_kwargs.deepcopy()
1035 train_kwargs["split"] = "train"
1036 test_kwargs = cache_kwargs.deepcopy()
AttributeError: 'dict' object has no attribute 'deepcopy'
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20516801?v=4",
"events_url": "https://api.github.com/users/morganmcg1/events{/privacy}",
"followers_url": "https://api.github.com/users/morganmcg1/followers",
"following_url": "https://api.github.com/users/morganmcg1/following{/other_user}",
"gists_url": "https://api.github.com/users/morganmcg1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/morganmcg1",
"id": 20516801,
"login": "morganmcg1",
"node_id": "MDQ6VXNlcjIwNTE2ODAx",
"organizations_url": "https://api.github.com/users/morganmcg1/orgs",
"received_events_url": "https://api.github.com/users/morganmcg1/received_events",
"repos_url": "https://api.github.com/users/morganmcg1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/morganmcg1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/morganmcg1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/morganmcg1",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/409/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/409/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/408
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/408/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/408/comments
|
https://api.github.com/repos/huggingface/datasets/issues/408/events
|
https://github.com/huggingface/datasets/pull/408
| 659,064,144
|
MDExOlB1bGxSZXF1ZXN0NDUwOTU1MTE0
| 408
|
Add tests datasets gcp
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-17 09:23:27+00:00
|
2020-07-17 09:26:57+00:00
|
2020-07-17 09:26:56+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/408.diff",
"html_url": "https://github.com/huggingface/datasets/pull/408",
"merged_at": "2020-07-17T09:26:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/408.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/408"
}
|
Some datasets are available on our google cloud storage in arrow format, so that the users don't need to process the data.
These tests make sure that they're always available. It also makes sure that their scripts are in sync between S3 and the repo.
This should avoid future issues like #407
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/408/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/408/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/407
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/407/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/407/comments
|
https://api.github.com/repos/huggingface/datasets/issues/407/events
|
https://github.com/huggingface/datasets/issues/407
| 658,672,736
|
MDU6SXNzdWU2NTg2NzI3MzY=
| 407
|
MissingBeamOptions for Wikipedia 20200501.en
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7490438?v=4",
"events_url": "https://api.github.com/users/mitchellgordon95/events{/privacy}",
"followers_url": "https://api.github.com/users/mitchellgordon95/followers",
"following_url": "https://api.github.com/users/mitchellgordon95/following{/other_user}",
"gists_url": "https://api.github.com/users/mitchellgordon95/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mitchellgordon95",
"id": 7490438,
"login": "mitchellgordon95",
"node_id": "MDQ6VXNlcjc0OTA0Mzg=",
"organizations_url": "https://api.github.com/users/mitchellgordon95/orgs",
"received_events_url": "https://api.github.com/users/mitchellgordon95/received_events",
"repos_url": "https://api.github.com/users/mitchellgordon95/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mitchellgordon95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mitchellgordon95/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mitchellgordon95",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null | 4
|
2020-07-16 23:48:03+00:00
|
2021-01-12 11:41:16+00:00
|
2020-07-17 14:24:28+00:00
|
CONTRIBUTOR
| null | null | null | null |
There may or may not be a regression for the pre-processed Wikipedia dataset. This was working fine 10 commits ago (without having Apache Beam available):
```
nlp.load_dataset('wikipedia', "20200501.en", split='train')
```
And now, having pulled master, I get:
```
Downloading and preparing dataset wikipedia/20200501.en (download: 16.99 GiB, generated: 17.07 GiB, total: 34.06 GiB) to /home/hltcoe/mgordon/.cache/huggingface/datasets/wikipedia/20200501.en/1.0.0/76b0b2747b679bb0ee7a1621e50e5a6378477add0c662668a324a5bc07d516dd...
Traceback (most recent call last):
File "scripts/download.py", line 11, in <module>
fire.Fire(download_pretrain)
File "/home/hltcoe/mgordon/.conda/envs/huggingface/lib/python3.6/site-packages/fire/core.py", line 138, in Fire
component_trace = _Fire(component, args, parsed_flag_args, context, name)
File "/home/hltcoe/mgordon/.conda/envs/huggingface/lib/python3.6/site-packages/fire/core.py", line 468, in _Fire
target=component.__name__)
File "/home/hltcoe/mgordon/.conda/envs/huggingface/lib/python3.6/site-packages/fire/core.py", line 672, in _CallAndUpdateTrace
component = fn(*varargs, **kwargs)
File "scripts/download.py", line 6, in download_pretrain
nlp.load_dataset('wikipedia', "20200501.en", split='train')
File "/exp/mgordon/nlp/src/nlp/load.py", line 534, in load_dataset
save_infos=save_infos,
File "/exp/mgordon/nlp/src/nlp/builder.py", line 460, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/exp/mgordon/nlp/src/nlp/builder.py", line 870, in _download_and_prepare
"\n\t`{}`".format(usage_example)
nlp.builder.MissingBeamOptions: Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided in `load_dataset` or in the builder arguments. For big datasets it has to run on large-scale data processing tools like Dataflow, S
park, etc. More information about Apache Beam runners at https://beam.apache.org/documentation/runners/capability-matrix/
If you really want to run it locally because you feel like the Dataset is small enough, you can use the local beam runner called `DirectRunner` (you may run out of memory).
Example of usage:
`load_dataset('wikipedia', '20200501.en', beam_runner='DirectRunner')`
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7490438?v=4",
"events_url": "https://api.github.com/users/mitchellgordon95/events{/privacy}",
"followers_url": "https://api.github.com/users/mitchellgordon95/followers",
"following_url": "https://api.github.com/users/mitchellgordon95/following{/other_user}",
"gists_url": "https://api.github.com/users/mitchellgordon95/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mitchellgordon95",
"id": 7490438,
"login": "mitchellgordon95",
"node_id": "MDQ6VXNlcjc0OTA0Mzg=",
"organizations_url": "https://api.github.com/users/mitchellgordon95/orgs",
"received_events_url": "https://api.github.com/users/mitchellgordon95/received_events",
"repos_url": "https://api.github.com/users/mitchellgordon95/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mitchellgordon95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mitchellgordon95/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mitchellgordon95",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/407/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/407/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/406
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/406/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/406/comments
|
https://api.github.com/repos/huggingface/datasets/issues/406/events
|
https://github.com/huggingface/datasets/issues/406
| 658,581,764
|
MDU6SXNzdWU2NTg1ODE3NjQ=
| 406
|
Faster Shuffling?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7490438?v=4",
"events_url": "https://api.github.com/users/mitchellgordon95/events{/privacy}",
"followers_url": "https://api.github.com/users/mitchellgordon95/followers",
"following_url": "https://api.github.com/users/mitchellgordon95/following{/other_user}",
"gists_url": "https://api.github.com/users/mitchellgordon95/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mitchellgordon95",
"id": 7490438,
"login": "mitchellgordon95",
"node_id": "MDQ6VXNlcjc0OTA0Mzg=",
"organizations_url": "https://api.github.com/users/mitchellgordon95/orgs",
"received_events_url": "https://api.github.com/users/mitchellgordon95/received_events",
"repos_url": "https://api.github.com/users/mitchellgordon95/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mitchellgordon95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mitchellgordon95/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mitchellgordon95",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 7
|
2020-07-16 21:21:53+00:00
|
2023-08-16 09:52:39+00:00
|
2020-09-07 14:45:25+00:00
|
CONTRIBUTOR
| null | null | null | null |
Consider shuffling bookcorpus:
```
dataset = nlp.load_dataset('bookcorpus', split='train')
dataset.shuffle()
```
According to tqdm, this will take around 2.5 hours on my machine to complete (even with the faster version of select from #405). I've also tried with `keep_in_memory=True` and `writer_batch_size=1000`.
But I can also just write the lines to a text file:
```
batch_size = 100000
with open('tmp.txt', 'w+') as out_f:
for i in tqdm(range(0, len(dataset), batch_size)):
batch = dataset[i:i+batch_size]['text']
print("\n".join(batch), file=out_f)
```
Which completes in a couple minutes, followed by `shuf tmp.txt > tmp2.txt` which completes in under a minute. And finally,
```
dataset = nlp.load_dataset('text', data_files='tmp2.txt')
```
Which completes in under 10 minutes. I read up on Apache Arrow this morning, and it seems like the columnar data format is not especially well-suited to shuffling rows, since moving items around requires a lot of book-keeping.
Is shuffle inherently slow, or am I just using it wrong? And if it is slow, would it make sense to try converting the data to a row-based format on disk and then shuffling? (Instead of calling select with a random permutation, as is currently done.)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/406/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/406/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/405
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/405/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/405/comments
|
https://api.github.com/repos/huggingface/datasets/issues/405/events
|
https://github.com/huggingface/datasets/pull/405
| 658,580,192
|
MDExOlB1bGxSZXF1ZXN0NDUwNTI1MTc3
| 405
|
Make select() faster by batching reads
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7490438?v=4",
"events_url": "https://api.github.com/users/mitchellgordon95/events{/privacy}",
"followers_url": "https://api.github.com/users/mitchellgordon95/followers",
"following_url": "https://api.github.com/users/mitchellgordon95/following{/other_user}",
"gists_url": "https://api.github.com/users/mitchellgordon95/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mitchellgordon95",
"id": 7490438,
"login": "mitchellgordon95",
"node_id": "MDQ6VXNlcjc0OTA0Mzg=",
"organizations_url": "https://api.github.com/users/mitchellgordon95/orgs",
"received_events_url": "https://api.github.com/users/mitchellgordon95/received_events",
"repos_url": "https://api.github.com/users/mitchellgordon95/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mitchellgordon95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mitchellgordon95/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mitchellgordon95",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-16 21:19:45+00:00
|
2020-07-17 17:05:44+00:00
|
2020-07-17 16:51:26+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/405.diff",
"html_url": "https://github.com/huggingface/datasets/pull/405",
"merged_at": "2020-07-17T16:51:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/405.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/405"
}
|
Here's a benchmark:
```
dataset = nlp.load_dataset('bookcorpus', split='train')
start = time.time()
dataset.select(np.arange(1000), reader_batch_size=1, load_from_cache_file=False)
end = time.time()
print(f'{end - start}')
start = time.time()
dataset.select(np.arange(1000), reader_batch_size=1000, load_from_cache_file=False)
end = time.time()
print(f'{end - start}')
```
Without batching, select takes around 1.27 seconds. With batching, it takes around 0.01 seconds. The slowness was upsetting me because dataset.shuffle() was supposed to take ~27 hours for bookcorpus. Now with the fix it takes ~2.5 hours (which still is pretty slow, but I'll open a separate issue for that).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/405/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/405/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/404
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/404/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/404/comments
|
https://api.github.com/repos/huggingface/datasets/issues/404/events
|
https://github.com/huggingface/datasets/pull/404
| 658,400,987
|
MDExOlB1bGxSZXF1ZXN0NDUwMzY4Mjg4
| 404
|
Add seed in metrics
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-16 17:27:05+00:00
|
2020-07-20 10:12:35+00:00
|
2020-07-20 10:12:34+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/404.diff",
"html_url": "https://github.com/huggingface/datasets/pull/404",
"merged_at": "2020-07-20T10:12:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/404.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/404"
}
|
With #361 we noticed that some metrics were not deterministic.
In this PR I allow the user to specify numpy's seed when instantiating a metric with `load_metric`.
The seed is set only when `compute` is called, and reset afterwards.
Moreover when calling `compute` with the same metric instance (i.e. same experiment_id), the metric will always return the same results given the same inputs. This is the case even if the seed is was not specified by the user, as the previous seed is going to be reused.
However, instantiating twice a metric (two different experiments) without specifying a seed can create different results.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/404/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/404/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/403
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/403/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/403/comments
|
https://api.github.com/repos/huggingface/datasets/issues/403/events
|
https://github.com/huggingface/datasets/pull/403
| 658,325,756
|
MDExOlB1bGxSZXF1ZXN0NDUwMzAzNjI2
| 403
|
return python objects instead of arrays by default
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-16 15:51:52+00:00
|
2020-07-17 11:37:01+00:00
|
2020-07-17 11:37:00+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/403.diff",
"html_url": "https://github.com/huggingface/datasets/pull/403",
"merged_at": "2020-07-17T11:37:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/403.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/403"
}
|
We were using to_pandas() to convert from arrow types, however it returns numpy arrays instead of python lists.
I fixed it by using to_pydict/to_pylist instead.
Fix #387
It was mentioned in https://github.com/huggingface/transformers/issues/5729
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/403/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/403/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/402
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/402/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/402/comments
|
https://api.github.com/repos/huggingface/datasets/issues/402/events
|
https://github.com/huggingface/datasets/pull/402
| 658,001,288
|
MDExOlB1bGxSZXF1ZXN0NDUwMDI2NTE0
| 402
|
Search qa
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-16 09:00:10+00:00
|
2020-07-16 14:27:00+00:00
|
2020-07-16 14:26:59+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/402.diff",
"html_url": "https://github.com/huggingface/datasets/pull/402",
"merged_at": "2020-07-16T14:26:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/402.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/402"
}
|
add SearchQA dataset
#336
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/402/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/402/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/401
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/401/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/401/comments
|
https://api.github.com/repos/huggingface/datasets/issues/401/events
|
https://github.com/huggingface/datasets/pull/401
| 657,996,252
|
MDExOlB1bGxSZXF1ZXN0NDUwMDIyNTc0
| 401
|
add web_questions
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-07-16 08:54:59+00:00
|
2020-08-06 06:16:20+00:00
|
2020-08-06 06:16:19+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/401.diff",
"html_url": "https://github.com/huggingface/datasets/pull/401",
"merged_at": "2020-08-06T06:16:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/401.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/401"
}
|
add Web Question dataset
#336
Maybe @patrickvonplaten you can help with the dummy_data structure? it still broken
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/401/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/401/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/400
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/400/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/400/comments
|
https://api.github.com/repos/huggingface/datasets/issues/400/events
|
https://github.com/huggingface/datasets/pull/400
| 657,975,600
|
MDExOlB1bGxSZXF1ZXN0NDUwMDA1MDU5
| 400
|
Web questions
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-16 08:28:29+00:00
|
2020-07-16 08:50:51+00:00
|
2020-07-16 08:42:54+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/400.diff",
"html_url": "https://github.com/huggingface/datasets/pull/400",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/400.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/400"
}
|
add the WebQuestion dataset
#336
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/400/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/400/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/399
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/399/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/399/comments
|
https://api.github.com/repos/huggingface/datasets/issues/399/events
|
https://github.com/huggingface/datasets/pull/399
| 657,841,433
|
MDExOlB1bGxSZXF1ZXN0NDQ5ODkxNTEy
| 399
|
Spelling mistake
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/9410067?v=4",
"events_url": "https://api.github.com/users/BlancRay/events{/privacy}",
"followers_url": "https://api.github.com/users/BlancRay/followers",
"following_url": "https://api.github.com/users/BlancRay/following{/other_user}",
"gists_url": "https://api.github.com/users/BlancRay/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/BlancRay",
"id": 9410067,
"login": "BlancRay",
"node_id": "MDQ6VXNlcjk0MTAwNjc=",
"organizations_url": "https://api.github.com/users/BlancRay/orgs",
"received_events_url": "https://api.github.com/users/BlancRay/received_events",
"repos_url": "https://api.github.com/users/BlancRay/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/BlancRay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BlancRay/subscriptions",
"type": "User",
"url": "https://api.github.com/users/BlancRay",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-07-16 04:37:58+00:00
|
2020-07-16 06:49:48+00:00
|
2020-07-16 06:49:37+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/399.diff",
"html_url": "https://github.com/huggingface/datasets/pull/399",
"merged_at": "2020-07-16T06:49:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/399.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/399"
}
|
In "Formatting the dataset" part, "The two toehr modifications..." should be "The two other modifications..." ,the word "other" wrong spelled as "toehr".
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/399/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/399/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/398
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/398/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/398/comments
|
https://api.github.com/repos/huggingface/datasets/issues/398/events
|
https://github.com/huggingface/datasets/pull/398
| 657,511,962
|
MDExOlB1bGxSZXF1ZXN0NDQ5NjE1OTk1
| 398
|
Add inline links
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13381361?v=4",
"events_url": "https://api.github.com/users/bharatr21/events{/privacy}",
"followers_url": "https://api.github.com/users/bharatr21/followers",
"following_url": "https://api.github.com/users/bharatr21/following{/other_user}",
"gists_url": "https://api.github.com/users/bharatr21/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bharatr21",
"id": 13381361,
"login": "bharatr21",
"node_id": "MDQ6VXNlcjEzMzgxMzYx",
"organizations_url": "https://api.github.com/users/bharatr21/orgs",
"received_events_url": "https://api.github.com/users/bharatr21/received_events",
"repos_url": "https://api.github.com/users/bharatr21/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bharatr21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bharatr21/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bharatr21",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-07-15 17:04:04+00:00
|
2020-07-22 10:14:22+00:00
|
2020-07-22 10:14:22+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/398.diff",
"html_url": "https://github.com/huggingface/datasets/pull/398",
"merged_at": "2020-07-22T10:14:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/398.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/398"
}
|
Add inline links to `Contributing.md`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/398/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/398/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/397
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/397/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/397/comments
|
https://api.github.com/repos/huggingface/datasets/issues/397/events
|
https://github.com/huggingface/datasets/pull/397
| 657,510,856
|
MDExOlB1bGxSZXF1ZXN0NDQ5NjE1MDA4
| 397
|
Add contiguous sharding
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists_url": "https://api.github.com/users/jarednielsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jarednielsen",
"id": 4564897,
"login": "jarednielsen",
"node_id": "MDQ6VXNlcjQ1NjQ4OTc=",
"organizations_url": "https://api.github.com/users/jarednielsen/orgs",
"received_events_url": "https://api.github.com/users/jarednielsen/received_events",
"repos_url": "https://api.github.com/users/jarednielsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jarednielsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jarednielsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jarednielsen",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-15 17:02:58+00:00
|
2020-07-17 16:59:31+00:00
|
2020-07-17 16:59:31+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/397.diff",
"html_url": "https://github.com/huggingface/datasets/pull/397",
"merged_at": "2020-07-17T16:59:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/397.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/397"
}
|
This makes dset.shard() play nice with nlp.concatenate_datasets(). When I originally wrote the shard() method, I was thinking about a distributed training scenario, but https://github.com/huggingface/nlp/pull/389 also uses it for splitting the dataset for distributed preprocessing.
Usage:
```
nlp.concatenate_datasets([dset.shard(n, i, contiguous=True) for i in range(n)])
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/397/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/397/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/396
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/396/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/396/comments
|
https://api.github.com/repos/huggingface/datasets/issues/396/events
|
https://github.com/huggingface/datasets/pull/396
| 657,477,952
|
MDExOlB1bGxSZXF1ZXN0NDQ5NTg3MDQ4
| 396
|
Fix memory issue when doing select
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-15 16:15:04+00:00
|
2020-07-16 08:07:32+00:00
|
2020-07-16 08:07:31+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/396.diff",
"html_url": "https://github.com/huggingface/datasets/pull/396",
"merged_at": "2020-07-16T08:07:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/396.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/396"
}
|
We were passing the `nlp.Dataset` object to get the hash for the new dataset's file name.
Fix #395
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/396/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/396/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/395
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/395/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/395/comments
|
https://api.github.com/repos/huggingface/datasets/issues/395/events
|
https://github.com/huggingface/datasets/issues/395
| 657,454,983
|
MDU6SXNzdWU2NTc0NTQ5ODM=
| 395
|
Memory issue when doing select
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null | 1
|
2020-07-15 15:43:38+00:00
|
2020-07-16 08:07:31+00:00
|
2020-07-16 08:07:31+00:00
|
MEMBER
| null | null | null | null |
As noticed in #389, the following code loads the entire wikipedia in memory.
```python
import nlp
w = nlp.load_dataset("wikipedia", "20200501.en", split="train")
w.select([0])
```
This is caused by [this line](https://github.com/huggingface/nlp/blob/master/src/nlp/arrow_dataset.py#L626) for some reason, that tries to serialize the function with all the wikipedia data with it.
It's not the case with `.map` or `.filter`.
However functions that are based on `.select` like `.shuffle`, `.shard`, `.train_test_split`, `.sort` are affected.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/395/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/395/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/394
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/394/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/394/comments
|
https://api.github.com/repos/huggingface/datasets/issues/394/events
|
https://github.com/huggingface/datasets/pull/394
| 657,425,548
|
MDExOlB1bGxSZXF1ZXN0NDQ5NTQzNTE0
| 394
|
Remove remaining nested dict
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-15 15:05:52+00:00
|
2020-07-16 07:39:52+00:00
|
2020-07-16 07:39:51+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/394.diff",
"html_url": "https://github.com/huggingface/datasets/pull/394",
"merged_at": "2020-07-16T07:39:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/394.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/394"
}
|
This PR deletes the remaining unnecessary nested dict
#378
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/394/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/394/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/393
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/393/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/393/comments
|
https://api.github.com/repos/huggingface/datasets/issues/393/events
|
https://github.com/huggingface/datasets/pull/393
| 657,330,911
|
MDExOlB1bGxSZXF1ZXN0NDQ5NDY1MTAz
| 393
|
Fix extracted files directory for the DownloadManager
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-15 12:59:55+00:00
|
2020-07-17 17:02:16+00:00
|
2020-07-17 17:02:14+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/393.diff",
"html_url": "https://github.com/huggingface/datasets/pull/393",
"merged_at": "2020-07-17T17:02:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/393.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/393"
}
|
The cache dir was often cluttered by extracted files because of the download manager.
For downloaded files, we are using the `downloads` directory to make things easier to navigate, but extracted files were still placed at the root of the cache directory. To fix that I changed the directory for extracted files to cache_dir/downloads/extracted.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/393/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/393/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/392
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/392/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/392/comments
|
https://api.github.com/repos/huggingface/datasets/issues/392/events
|
https://github.com/huggingface/datasets/pull/392
| 657,313,738
|
MDExOlB1bGxSZXF1ZXN0NDQ5NDUwOTkx
| 392
|
Style change detection
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13795113?v=4",
"events_url": "https://api.github.com/users/ghomasHudson/events{/privacy}",
"followers_url": "https://api.github.com/users/ghomasHudson/followers",
"following_url": "https://api.github.com/users/ghomasHudson/following{/other_user}",
"gists_url": "https://api.github.com/users/ghomasHudson/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ghomasHudson",
"id": 13795113,
"login": "ghomasHudson",
"node_id": "MDQ6VXNlcjEzNzk1MTEz",
"organizations_url": "https://api.github.com/users/ghomasHudson/orgs",
"received_events_url": "https://api.github.com/users/ghomasHudson/received_events",
"repos_url": "https://api.github.com/users/ghomasHudson/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ghomasHudson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghomasHudson/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ghomasHudson",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-15 12:32:14+00:00
|
2020-07-21 13:18:36+00:00
|
2020-07-17 17:13:23+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/392.diff",
"html_url": "https://github.com/huggingface/datasets/pull/392",
"merged_at": "2020-07-17T17:13:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/392.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/392"
}
|
Another [PAN task](https://pan.webis.de/clef20/pan20-web/style-change-detection.html). This time about identifying when the style/author changes in documents.
- There's the possibility of adding the [PAN19](https://zenodo.org/record/3577602) and PAN18 style change detection tasks too (these are datasets whose labels are a subset of PAN20's). These would probably make more sense as separate datasets (like wmt is now)
- I've converted the integer 0,1 values to a boolean
- Using manually downloaded data again. This might be changed at some point following the discussion in https://github.com/huggingface/nlp/pull/349.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/392/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/392/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/390
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/390/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/390/comments
|
https://api.github.com/repos/huggingface/datasets/issues/390/events
|
https://github.com/huggingface/datasets/pull/390
| 656,956,384
|
MDExOlB1bGxSZXF1ZXN0NDQ5MTYxMzY3
| 390
|
Concatenate datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists_url": "https://api.github.com/users/jarednielsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jarednielsen",
"id": 4564897,
"login": "jarednielsen",
"node_id": "MDQ6VXNlcjQ1NjQ4OTc=",
"organizations_url": "https://api.github.com/users/jarednielsen/orgs",
"received_events_url": "https://api.github.com/users/jarednielsen/received_events",
"repos_url": "https://api.github.com/users/jarednielsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jarednielsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jarednielsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jarednielsen",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 6
|
2020-07-14 23:24:37+00:00
|
2020-07-22 09:49:58+00:00
|
2020-07-22 09:49:58+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/390.diff",
"html_url": "https://github.com/huggingface/datasets/pull/390",
"merged_at": "2020-07-22T09:49:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/390.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/390"
}
|
I'm constructing the "WikiBooks" dataset, which is a concatenation of Wikipedia & BookCorpus. So I implemented the `Dataset.from_concat()` method, which concatenates two datasets with the same schema.
This would also be useful if someone wants to pretrain on a large generic dataset + their own custom dataset. Not in love with the method name, so would love to hear suggestions.
Usage:
```python
from nlp import Dataset, load_dataset
data1, data2 = {"id": [0, 1, 2]}, {"id": [3, 4, 5]}
dset1, dset2 = Dataset.from_dict(data1), Dataset.from_dict(data2)
dset_concat = Dataset.from_concat([dset1, dset2])
print(dset_concat)
# Dataset(schema: {'id': 'int64'}, num_rows: 6)
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/390/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/390/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/389
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/389/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/389/comments
|
https://api.github.com/repos/huggingface/datasets/issues/389/events
|
https://github.com/huggingface/datasets/pull/389
| 656,921,768
|
MDExOlB1bGxSZXF1ZXN0NDQ5MTMyOTU5
| 389
|
Fix pickling of SplitDict
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7490438?v=4",
"events_url": "https://api.github.com/users/mitchellgordon95/events{/privacy}",
"followers_url": "https://api.github.com/users/mitchellgordon95/followers",
"following_url": "https://api.github.com/users/mitchellgordon95/following{/other_user}",
"gists_url": "https://api.github.com/users/mitchellgordon95/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mitchellgordon95",
"id": 7490438,
"login": "mitchellgordon95",
"node_id": "MDQ6VXNlcjc0OTA0Mzg=",
"organizations_url": "https://api.github.com/users/mitchellgordon95/orgs",
"received_events_url": "https://api.github.com/users/mitchellgordon95/received_events",
"repos_url": "https://api.github.com/users/mitchellgordon95/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mitchellgordon95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mitchellgordon95/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mitchellgordon95",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 11
|
2020-07-14 21:53:39+00:00
|
2020-08-04 14:38:10+00:00
|
2020-08-04 14:38:10+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/389.diff",
"html_url": "https://github.com/huggingface/datasets/pull/389",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/389.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/389"
}
|
It would be nice to pickle and unpickle Datasets, as done in [this tutorial](https://github.com/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb). Example:
```
wiki = nlp.load_dataset('wikipedia', split='train')
def sentencize(examples):
...
wiki = wiki.map(sentencize, batched=True)
torch.save(wiki, 'sentencized_wiki_dataset.pt')
```
However, upon unpickling the dataset via torch.load(...), this error is raised:
```
ValueError("Cannot add elem. Use .add() instead.")
```
On line [492 of splits.py](https://github.com/huggingface/nlp/blob/master/src/nlp/splits.py#L492). This is because SplitDict subclasses dict, and pickle treats [dicts specially](https://github.com/huggingface/nlp/blob/master/src/nlp/splits.py#L492). Pickle expects access to `dict.__setitem__`, but this is disallowed by the class.
The workaround is to provide an explicit interface for pickle to call when pickling and unpickling, thereby avoiding the use of `__setitem__`.
Testing:
- Manually pickled and unpickled a modified wikipedia dataset.
- Ran `make style`
I would be happy to run any other tests, but I couldn't find any in the contributing guidelines.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7490438?v=4",
"events_url": "https://api.github.com/users/mitchellgordon95/events{/privacy}",
"followers_url": "https://api.github.com/users/mitchellgordon95/followers",
"following_url": "https://api.github.com/users/mitchellgordon95/following{/other_user}",
"gists_url": "https://api.github.com/users/mitchellgordon95/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mitchellgordon95",
"id": 7490438,
"login": "mitchellgordon95",
"node_id": "MDQ6VXNlcjc0OTA0Mzg=",
"organizations_url": "https://api.github.com/users/mitchellgordon95/orgs",
"received_events_url": "https://api.github.com/users/mitchellgordon95/received_events",
"repos_url": "https://api.github.com/users/mitchellgordon95/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mitchellgordon95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mitchellgordon95/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mitchellgordon95",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/389/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/389/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/388
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/388/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/388/comments
|
https://api.github.com/repos/huggingface/datasets/issues/388/events
|
https://github.com/huggingface/datasets/issues/388
| 656,707,497
|
MDU6SXNzdWU2NTY3MDc0OTc=
| 388
|
🐛 [Dataset] Cannot download wmt14, wmt15 and wmt17
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2826602?v=4",
"events_url": "https://api.github.com/users/SamuelCahyawijaya/events{/privacy}",
"followers_url": "https://api.github.com/users/SamuelCahyawijaya/followers",
"following_url": "https://api.github.com/users/SamuelCahyawijaya/following{/other_user}",
"gists_url": "https://api.github.com/users/SamuelCahyawijaya/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/SamuelCahyawijaya",
"id": 2826602,
"login": "SamuelCahyawijaya",
"node_id": "MDQ6VXNlcjI4MjY2MDI=",
"organizations_url": "https://api.github.com/users/SamuelCahyawijaya/orgs",
"received_events_url": "https://api.github.com/users/SamuelCahyawijaya/received_events",
"repos_url": "https://api.github.com/users/SamuelCahyawijaya/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/SamuelCahyawijaya/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SamuelCahyawijaya/subscriptions",
"type": "User",
"url": "https://api.github.com/users/SamuelCahyawijaya",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
] | null | 5
|
2020-07-14 15:36:41+00:00
|
2022-10-04 18:01:28+00:00
|
2022-10-04 18:01:28+00:00
|
NONE
| null | null | null | null |
1. I try downloading `wmt14`, `wmt15`, `wmt17`, `wmt19` with the following code:
```
nlp.load_dataset('wmt14','de-en')
nlp.load_dataset('wmt15','de-en')
nlp.load_dataset('wmt17','de-en')
nlp.load_dataset('wmt19','de-en')
```
The code runs but the download speed is **extremely slow**, the same behaviour is not observed on `wmt16` and `wmt18`
2. When trying to download `wmt17 zh-en`, I got the following error:
> ConnectionError: Couldn't reach https://storage.googleapis.com/tfdataset-data/downloadataset/uncorpus/UNv1.0.en-zh.tar.gz
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/388/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/388/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/387
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/387/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/387/comments
|
https://api.github.com/repos/huggingface/datasets/issues/387/events
|
https://github.com/huggingface/datasets/issues/387
| 656,361,357
|
MDU6SXNzdWU2NTYzNjEzNTc=
| 387
|
Conversion through to_pandas output numpy arrays for lists instead of python objects
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-07-14 06:24:01+00:00
|
2020-07-17 11:37:00+00:00
|
2020-07-17 11:37:00+00:00
|
MEMBER
| null | null | null | null |
In a related question, the conversion through to_pandas output numpy arrays for the lists instead of python objects.
Here is an example:
```python
>>> dataset._data.slice(key, 1).to_pandas().to_dict("list")
{'sentence1': ['Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .'], 'sentence2': ['Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .'], 'label': [1], 'idx': [0], 'input_ids': [array([ 101, 7277, 2180, 5303, 4806, 1117, 1711, 117, 2292,
1119, 1270, 107, 1103, 7737, 107, 117, 1104, 9938,
4267, 12223, 21811, 1117, 2554, 119, 102])], 'token_type_ids': [array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0])], 'attention_mask': [array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1])]}
>>> type(dataset._data.slice(key, 1).to_pandas().to_dict("list")['input_ids'][0])
<class 'numpy.ndarray'>
>>> dataset._data.slice(key, 1).to_pydict()
{'sentence1': ['Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .'], 'sentence2': ['Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .'], 'label': [1], 'idx': [0], 'input_ids': [[101, 7277, 2180, 5303, 4806, 1117, 1711, 117, 2292, 1119, 1270, 107, 1103, 7737, 107, 117, 1104, 9938, 4267, 12223, 21811, 1117, 2554, 119, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/387/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/387/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/386
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/386/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/386/comments
|
https://api.github.com/repos/huggingface/datasets/issues/386/events
|
https://github.com/huggingface/datasets/pull/386
| 655,839,067
|
MDExOlB1bGxSZXF1ZXN0NDQ4MjQ1NDI4
| 386
|
Update dataset loading and features - Add TREC dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-07-13 13:10:18+00:00
|
2020-07-16 08:17:58+00:00
|
2020-07-16 08:17:58+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/386.diff",
"html_url": "https://github.com/huggingface/datasets/pull/386",
"merged_at": "2020-07-16T08:17:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/386.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/386"
}
|
This PR:
- add a template for a new dataset script
- update the caching structure so that the path to the cached data files is also a function of the dataset loading script hash. This way when you update a loading script the data will be automatically updated instead of falling back to the previous version (which is usually a outdated). This makes it in particular easier to iterate when writing a new dataset loading script.
- fix a bug in the `ClassLabel` feature and make it more flexible so that its methods `str2int` and `int2str` can also accept list, numpy arrays and PyTorch/TensorFlow tensors.
- add the TREC-6 dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/386/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/386/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/385
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/385/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/385/comments
|
https://api.github.com/repos/huggingface/datasets/issues/385/events
|
https://github.com/huggingface/datasets/pull/385
| 655,663,997
|
MDExOlB1bGxSZXF1ZXN0NDQ4MTAzMjY5
| 385
|
Remove unnecessary nested dict
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 5
|
2020-07-13 08:46:23+00:00
|
2020-07-15 11:27:38+00:00
|
2020-07-15 10:03:53+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/385.diff",
"html_url": "https://github.com/huggingface/datasets/pull/385",
"merged_at": "2020-07-15T10:03:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/385.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/385"
}
|
This PR is removing unnecessary nested dictionary used in some datasets. For now the following datasets are updated:
- MLQA
- RACE
Will be adding more if necessary.
#378
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/385/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/385/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/383
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/383/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/383/comments
|
https://api.github.com/repos/huggingface/datasets/issues/383/events
|
https://github.com/huggingface/datasets/pull/383
| 655,291,201
|
MDExOlB1bGxSZXF1ZXN0NDQ3ODI0OTky
| 383
|
Adding the Linguistic Code-switching Evaluation (LinCE) benchmark
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5833357?v=4",
"events_url": "https://api.github.com/users/gaguilar/events{/privacy}",
"followers_url": "https://api.github.com/users/gaguilar/followers",
"following_url": "https://api.github.com/users/gaguilar/following{/other_user}",
"gists_url": "https://api.github.com/users/gaguilar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gaguilar",
"id": 5833357,
"login": "gaguilar",
"node_id": "MDQ6VXNlcjU4MzMzNTc=",
"organizations_url": "https://api.github.com/users/gaguilar/orgs",
"received_events_url": "https://api.github.com/users/gaguilar/received_events",
"repos_url": "https://api.github.com/users/gaguilar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gaguilar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gaguilar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gaguilar",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 5
|
2020-07-11 22:35:20+00:00
|
2020-07-16 16:19:46+00:00
|
2020-07-16 16:19:46+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/383.diff",
"html_url": "https://github.com/huggingface/datasets/pull/383",
"merged_at": "2020-07-16T16:19:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/383.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/383"
}
|
Hi,
First of all, this library is really cool! Thanks for putting all of this together!
This PR contains the [Linguistic Code-switching Evaluation (LinCE) benchmark](https://ritual.uh.edu/lince). As described in the official website (FAQ):
> 1. Why do we need LinCE?
>LinCE brings 10 code-switching datasets together for 4 tasks and 4 language pairs with 5 leaderboards in a single evaluation platform. We examined each dataset and fixed major issues on the partitions (or even define official partitions) with a comprehensive stratification method (see our paper for more details).
>Besides, we believe that online benchmarks like LinCE bring steady research progress and allow to compare state-of-the-art models at the pace of the progress in NLP. We expect to benefit greatly the code-switching community with this benchmark.
The data comes from social media and here's the summary table of tasks per language pair:
| Language Pairs | LID | POS | NER | SA |
|----------------------------------------|-----|-----|-----|----|
| Spanish-English | ✅ | ✅ | ✅ | ✅ |
| Hindi-English | ✅ | ✅ | ✅ | |
| Modern Standard Arabic-Egyptian Arabic | ✅ | | ✅ | |
| Nepali-English | ✅ | | | |
The tasks are as follows:
* LID: token-level language identification
* POS: part-of-speech tagging
* NER: named entity recognition
* SA: sentiment analysis
With the exception of MSA-EA, the rest of the datasets contain token-level LID labels.
## Usage
For Spanish-English LID, we can load the data as follows:
```
import nlp
data = nlp.load_dataset('./datasets/lince/lince.py', 'lid_spaeng')
for split in data:
print(data[split])
```
Here's the output:
```
Dataset(schema: {'idx': 'int32', 'tokens': 'list<item: string>', 'lid': 'list<item: string>'}, num_rows: 21030)
Dataset(schema: {'idx': 'int32', 'tokens': 'list<item: string>', 'lid': 'list<item: string>'}, num_rows: 3332)
Dataset(schema: {'idx': 'int32', 'tokens': 'list<item: string>', 'lid': 'list<item: string>'}, num_rows: 8289)
```
Here's the list of shortcut names for every dataset available in LinCE:
* `lid_spaeng`
* `lid_hineng`
* `lid_nepeng`
* `lid_msaea`
* `pos_spaeng`
* `pos_hineng`
* `ner_spaeng`
* `ner_hineng`
* `ner_msaea`
* `sa_spaeng`
All the numbers match with Table 3 in the LinCE [paper](https://www.aclweb.org/anthology/2020.lrec-1.223.pdf). Also, note that the MSA-EA datasets use the Persian script while the other datasets use the Roman script.
## Features
Here is how the features look in the case of language identification (LID) tasks:
| LID Feature | Type | Description |
|----------------------|---------------|-------------------------------------------|
| `idx` | `int` | Dataset index of current sentence |
| `tokens` | `list<str>` | List of tokens (string) of a sentence |
| `lid` | `list<str>` | List of LID labels (string) of a sentence |
For part-of-speech (POS) tagging:
| POS Feature | Type | Description |
|----------------------|---------------|-------------------------------------------|
| `idx` | `int` | Dataset index of current sentence |
| `tokens` | `list<str>` | List of tokens (string) of a sentence |
| `lid` | `list<str>` | List of LID labels (string) of a sentence |
| `pos` | `list<str>` | List of POS tags (string) of a sentence |
For named entity recognition (NER):
| NER Feature | Type | Description |
|----------------------|---------------|-------------------------------------------|
| `idx` | `int` | Dataset index of current sentence |
| `tokens` | `list<str>` | List of tokens (string) of a sentence |
| `lid` | `list<str>` | List of LID labels (string) of a sentence |
| `ner` | `list<str>` | List of NER labels (string) of a sentence |
**NOTE**: the MSA-EA NER dataset does not contain the `lid` feature.
For sentiment analysis (SA):
| SA Feature | Type | Description |
|---------------------|-------------|-------------------------------------------|
| `idx` | `int` | Dataset index of current sentence |
| `tokens` | `list<str>` | List of tokens (string) of a sentence |
| `lid` | `list<str>` | List of LID labels (string) of a sentence |
| `sa` | `str` | Sentiment label (string) of a sentence |
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/383/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/383/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/382
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/382/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/382/comments
|
https://api.github.com/repos/huggingface/datasets/issues/382/events
|
https://github.com/huggingface/datasets/issues/382
| 655,290,482
|
MDU6SXNzdWU2NTUyOTA0ODI=
| 382
|
1080
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/60942503?v=4",
"events_url": "https://api.github.com/users/saq194/events{/privacy}",
"followers_url": "https://api.github.com/users/saq194/followers",
"following_url": "https://api.github.com/users/saq194/following{/other_user}",
"gists_url": "https://api.github.com/users/saq194/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/saq194",
"id": 60942503,
"login": "saq194",
"node_id": "MDQ6VXNlcjYwOTQyNTAz",
"organizations_url": "https://api.github.com/users/saq194/orgs",
"received_events_url": "https://api.github.com/users/saq194/received_events",
"repos_url": "https://api.github.com/users/saq194/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/saq194/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/saq194/subscriptions",
"type": "User",
"url": "https://api.github.com/users/saq194",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-11 22:29:07+00:00
|
2020-07-11 22:49:38+00:00
|
2020-07-11 22:49:38+00:00
|
NONE
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/382/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/382/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
|
https://api.github.com/repos/huggingface/datasets/issues/381
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/381/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/381/comments
|
https://api.github.com/repos/huggingface/datasets/issues/381/events
|
https://github.com/huggingface/datasets/issues/381
| 655,277,119
|
MDU6SXNzdWU2NTUyNzcxMTk=
| 381
|
NLp
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/68147610?v=4",
"events_url": "https://api.github.com/users/Spartanthor/events{/privacy}",
"followers_url": "https://api.github.com/users/Spartanthor/followers",
"following_url": "https://api.github.com/users/Spartanthor/following{/other_user}",
"gists_url": "https://api.github.com/users/Spartanthor/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Spartanthor",
"id": 68147610,
"login": "Spartanthor",
"node_id": "MDQ6VXNlcjY4MTQ3NjEw",
"organizations_url": "https://api.github.com/users/Spartanthor/orgs",
"received_events_url": "https://api.github.com/users/Spartanthor/received_events",
"repos_url": "https://api.github.com/users/Spartanthor/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Spartanthor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Spartanthor/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Spartanthor",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-11 20:50:14+00:00
|
2020-07-11 20:50:39+00:00
|
2020-07-11 20:50:39+00:00
|
NONE
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/381/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/381/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
|
https://api.github.com/repos/huggingface/datasets/issues/378
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/378/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/378/comments
|
https://api.github.com/repos/huggingface/datasets/issues/378/events
|
https://github.com/huggingface/datasets/issues/378
| 655,226,316
|
MDU6SXNzdWU2NTUyMjYzMTY=
| 378
|
[dataset] Structure of MLQA seems unecessary nested
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-07-11 15:16:08+00:00
|
2020-07-15 16:17:20+00:00
|
2020-07-15 16:17:20+00:00
|
MEMBER
| null | null | null | null |
The features of the MLQA dataset comprise several nested dictionaries with a single element inside (for `questions` and `ids`): https://github.com/huggingface/nlp/blob/master/datasets/mlqa/mlqa.py#L90-L97
Should we keep this @mariamabarham @patrickvonplaten? Was this added for compatibility with tfds?
```python
features=nlp.Features(
{
"context": nlp.Value("string"),
"questions": nlp.features.Sequence({"question": nlp.Value("string")}),
"answers": nlp.features.Sequence(
{"text": nlp.Value("string"), "answer_start": nlp.Value("int32"),}
),
"ids": nlp.features.Sequence({"idx": nlp.Value("string")})
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/378/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/378/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/377
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/377/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/377/comments
|
https://api.github.com/repos/huggingface/datasets/issues/377/events
|
https://github.com/huggingface/datasets/issues/377
| 655,215,790
|
MDU6SXNzdWU2NTUyMTU3OTA=
| 377
|
Iyy!!!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/68154535?v=4",
"events_url": "https://api.github.com/users/ajinomoh/events{/privacy}",
"followers_url": "https://api.github.com/users/ajinomoh/followers",
"following_url": "https://api.github.com/users/ajinomoh/following{/other_user}",
"gists_url": "https://api.github.com/users/ajinomoh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ajinomoh",
"id": 68154535,
"login": "ajinomoh",
"node_id": "MDQ6VXNlcjY4MTU0NTM1",
"organizations_url": "https://api.github.com/users/ajinomoh/orgs",
"received_events_url": "https://api.github.com/users/ajinomoh/received_events",
"repos_url": "https://api.github.com/users/ajinomoh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ajinomoh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ajinomoh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ajinomoh",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-11 14:11:07+00:00
|
2020-07-11 14:30:51+00:00
|
2020-07-11 14:30:51+00:00
|
NONE
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/377/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/377/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
|
https://api.github.com/repos/huggingface/datasets/issues/376
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/376/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/376/comments
|
https://api.github.com/repos/huggingface/datasets/issues/376/events
|
https://github.com/huggingface/datasets/issues/376
| 655,047,826
|
MDU6SXNzdWU2NTUwNDc4MjY=
| 376
|
to_pandas conversion doesn't always work
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-07-10 21:33:31+00:00
|
2022-10-04 18:05:39+00:00
|
2022-10-04 18:05:39+00:00
|
MEMBER
| null | null | null | null |
For some complex nested types, the conversion from Arrow to python dict through pandas doesn't seem to be possible.
Here is an example using the official SQUAD v2 JSON file.
This example was found while investigating #373.
```python
>>> squad = load_dataset('json', data_files={nlp.Split.TRAIN: ["./train-v2.0.json"]}, download_mode=nlp.GenerateMode.FORCE_REDOWNLOAD, version="1.0.0", field='data')
>>> squad['train']
Dataset(schema: {'title': 'string', 'paragraphs': 'list<item: struct<qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>, context: string>>'}, num_rows: 442)
>>> squad['train'][0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/thomwolf/Documents/GitHub/datasets/src/nlp/arrow_dataset.py", line 589, in __getitem__
format_kwargs=self._format_kwargs,
File "/Users/thomwolf/Documents/GitHub/datasets/src/nlp/arrow_dataset.py", line 529, in _getitem
outputs = self._unnest(self._data.slice(key, 1).to_pandas().to_dict("list"))
File "pyarrow/array.pxi", line 559, in pyarrow.lib._PandasConvertible.to_pandas
File "pyarrow/table.pxi", line 1367, in pyarrow.lib.Table._to_pandas
File "/Users/thomwolf/miniconda2/envs/datasets/lib/python3.7/site-packages/pyarrow/pandas_compat.py", line 766, in table_to_blockmanager
blocks = _table_to_blocks(options, table, categories, ext_columns_dtypes)
File "/Users/thomwolf/miniconda2/envs/datasets/lib/python3.7/site-packages/pyarrow/pandas_compat.py", line 1101, in _table_to_blocks
list(extension_columns.keys()))
File "pyarrow/table.pxi", line 881, in pyarrow.lib.table_to_blocks
File "pyarrow/error.pxi", line 105, in pyarrow.lib.check_status
pyarrow.lib.ArrowNotImplementedError: Not implemented type for Arrow list to pandas: struct<qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>, context: string>
```
cc @lhoestq would we have a way to detect this from the schema maybe?
Here is the schema for this pretty complex JSON:
```python
>>> squad['train'].schema
title: string
paragraphs: list<item: struct<qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>, context: string>>
child 0, item: struct<qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>, context: string>
child 0, qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>
child 0, item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>
child 0, question: string
child 1, id: string
child 2, answers: list<item: struct<text: string, answer_start: int64>>
child 0, item: struct<text: string, answer_start: int64>
child 0, text: string
child 1, answer_start: int64
child 3, is_impossible: bool
child 4, plausible_answers: list<item: struct<text: string, answer_start: int64>>
child 0, item: struct<text: string, answer_start: int64>
child 0, text: string
child 1, answer_start: int64
child 1, context: string
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/376/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/376/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/375
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/375/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/375/comments
|
https://api.github.com/repos/huggingface/datasets/issues/375/events
|
https://github.com/huggingface/datasets/issues/375
| 655,023,307
|
MDU6SXNzdWU2NTUwMjMzMDc=
| 375
|
TypeError when computing bertscore
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13269577?v=4",
"events_url": "https://api.github.com/users/willywsm1013/events{/privacy}",
"followers_url": "https://api.github.com/users/willywsm1013/followers",
"following_url": "https://api.github.com/users/willywsm1013/following{/other_user}",
"gists_url": "https://api.github.com/users/willywsm1013/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/willywsm1013",
"id": 13269577,
"login": "willywsm1013",
"node_id": "MDQ6VXNlcjEzMjY5NTc3",
"organizations_url": "https://api.github.com/users/willywsm1013/orgs",
"received_events_url": "https://api.github.com/users/willywsm1013/received_events",
"repos_url": "https://api.github.com/users/willywsm1013/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/willywsm1013/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/willywsm1013/subscriptions",
"type": "User",
"url": "https://api.github.com/users/willywsm1013",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-07-10 20:37:44+00:00
|
2022-06-01 15:15:59+00:00
|
2022-06-01 15:15:59+00:00
|
NONE
| null | null | null | null |
Hi,
I installed nlp 0.3.0 via pip, and my python version is 3.7.
When I tried to compute bertscore with the code:
```
import nlp
bertscore = nlp.load_metric('bertscore')
# load hyps and refs
...
print (bertscore.compute(hyps, refs, lang='en'))
```
I got the following error.
```
Traceback (most recent call last):
File "bert_score_evaluate.py", line 16, in <module>
print (bertscore.compute(hyps, refs, lang='en'))
File "/home/willywsm/anaconda3/envs/torcher/lib/python3.7/site-packages/nlp/metric.py", line 200, in compute
output = self._compute(predictions=predictions, references=references, **metrics_kwargs)
File "/home/willywsm/anaconda3/envs/torcher/lib/python3.7/site-packages/nlp/metrics/bertscore/fb176889831bf0ce995ed197edc94b2e9a83f647a869bb8c9477dbb2d04d0f08/bertscore.py", line 105, in _compute
hashcode = bert_score.utils.get_hash(model_type, num_layers, idf, rescale_with_baseline)
TypeError: get_hash() takes 3 positional arguments but 4 were given
```
It seems like there is something wrong with get_hash() function?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/375/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/375/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/374
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/374/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/374/comments
|
https://api.github.com/repos/huggingface/datasets/issues/374/events
|
https://github.com/huggingface/datasets/pull/374
| 654,895,066
|
MDExOlB1bGxSZXF1ZXN0NDQ3NTMxMzUy
| 374
|
Add dataset post processing for faiss indexes
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-07-10 16:25:59+00:00
|
2020-07-13 13:44:03+00:00
|
2020-07-13 13:44:01+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/374.diff",
"html_url": "https://github.com/huggingface/datasets/pull/374",
"merged_at": "2020-07-13T13:44:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/374.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/374"
}
|
# Post processing of datasets for faiss indexes
Now that we can have datasets with embeddings (see `wiki_pr` for example), we can allow users to load the dataset + get the Faiss index that comes with it to do nearest neighbors queries.
## Implementation proposition
- Faiss indexes have to be added to the `nlp.Dataset` object, and therefore it's in a different scope that what are doing the `_split_generators` and `_generate_examples` methods of `nlp.DatasetBuilder`. Therefore I added a new method for post processing of the `nlp.Dataset` object called `_post_process` (name could change)
- The role of `_post_process` is to apply dataset transforms (filter/map etc.) or indexing functions (add_faiss_index) to modify/enrich the `nlp.Dataset` object. It is not part of the `download_and_prepare` process (that is focused on arrow files creation) so the post processing is run inside the `as_dataset` method.
- `_post_process` can generate new files (cached files from dataset transforms or serialized faiss indexes) and their names are defined by `_post_processing_resources`
- as we know what are the post processing resources, we can download them automatically from google storage instead of computing them if they're available (as we do for arrow files)
I'd happy to discuss these choices !
## The `wiki_dpr` index
It takes 1h20 and ~7GB of memory to compute. The final index is 1.42GB and takes ~1.5GB of memory.
This is pretty cool given that a naive flat index would take 170GB of memory to store the 21M vectors of dim 768.
I couldn't use directly the Faiss `index_factory` as I needed to set the metric to inner product.
## Example of usage
```python
import nlp
dset = nlp.load_dataset(
"wiki_dpr",
"psgs_w100_with_nq_embeddings",
split="train",
with_index=True
)
print(len(dset), dset.list_indexes()) # (21015300, ['embeddings'])
```
(it also works with the dataset configuration without the embeddings because I added the index file in google storage for this one too)
## Demo
You can also check a demo on google colab that shows how to use it with the DPRQuestionEncoder from transformers:
https://colab.research.google.com/drive/1FakNU8W5EPMcWff7iP1H6REg3XSS0YLp?usp=sharing
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/374/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/374/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/373
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/373/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/373/comments
|
https://api.github.com/repos/huggingface/datasets/issues/373/events
|
https://github.com/huggingface/datasets/issues/373
| 654,845,133
|
MDU6SXNzdWU2NTQ4NDUxMzM=
| 373
|
Segmentation fault when loading local JSON dataset as of #372
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/24683907?v=4",
"events_url": "https://api.github.com/users/vegarab/events{/privacy}",
"followers_url": "https://api.github.com/users/vegarab/followers",
"following_url": "https://api.github.com/users/vegarab/following{/other_user}",
"gists_url": "https://api.github.com/users/vegarab/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vegarab",
"id": 24683907,
"login": "vegarab",
"node_id": "MDQ6VXNlcjI0NjgzOTA3",
"organizations_url": "https://api.github.com/users/vegarab/orgs",
"received_events_url": "https://api.github.com/users/vegarab/received_events",
"repos_url": "https://api.github.com/users/vegarab/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vegarab/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vegarab/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vegarab",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 11
|
2020-07-10 15:04:25+00:00
|
2022-10-04 18:05:47+00:00
|
2022-10-04 18:05:47+00:00
|
CONTRIBUTOR
| null | null | null | null |
The last issue was closed (#369) once the #372 update was merged. However, I'm still not able to load a SQuAD formatted JSON file. Instead of the previously recorded pyarrow error, I now get a segmentation fault.
```
dataset = nlp.load_dataset('json', data_files={nlp.Split.TRAIN: ["./datasets/train-v2.0.json"]}, field='data')
```
causes
```
Using custom data configuration default
Downloading and preparing dataset json/default (download: Unknown size, generated: Unknown size, total: Unknown size) to /home/XXX/.cache/huggingface/datasets/json/default/0.0.0...
0 tables [00:00, ? tables/s]Segmentation fault (core dumped)
```
where `./datasets/train-v2.0.json` is downloaded directly from https://rajpurkar.github.io/SQuAD-explorer/.
This is consistent with other SQuAD-formatted JSON files.
When attempting to load the dataset again, I get the following:
```
Using custom data configuration default
Traceback (most recent call last):
File "dataloader.py", line 6, in <module>
'json', data_files={nlp.Split.TRAIN: ["./datasets/train-v2.0.json"]}, field='data')
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/load.py", line 524, in load_dataset
save_infos=save_infos,
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/builder.py", line 382, in download_and_prepare
with incomplete_dir(self._cache_dir) as tmp_data_dir:
File "/home/XXX/.conda/envs/torch/lib/python3.7/contextlib.py", line 112, in __enter__
return next(self.gen)
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/builder.py", line 368, in incomplete_dir
os.makedirs(tmp_dir)
File "/home/XXX/.conda/envs/torch/lib/python3.7/os.py", line 223, in makedirs
mkdir(name, mode)
FileExistsError: [Errno 17] File exists: '/home/XXX/.cache/huggingface/datasets/json/default/0.0.0.incomplete'
```
(Not sure if you wanted this in the previous issue #369 or not as it was closed.)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/373/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/373/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/372
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/372/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/372/comments
|
https://api.github.com/repos/huggingface/datasets/issues/372/events
|
https://github.com/huggingface/datasets/pull/372
| 654,774,420
|
MDExOlB1bGxSZXF1ZXN0NDQ3NDMzNTA4
| 372
|
Make the json script more flexible
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-10 13:15:15+00:00
|
2020-07-10 14:52:07+00:00
|
2020-07-10 14:52:06+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/372.diff",
"html_url": "https://github.com/huggingface/datasets/pull/372",
"merged_at": "2020-07-10T14:52:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/372.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/372"
}
|
Fix https://github.com/huggingface/nlp/issues/359
Fix https://github.com/huggingface/nlp/issues/369
JSON script now can accept JSON files containing a single dict with the records as a list in one attribute to the dict (previously it only accepted JSON files containing records as rows of dicts in the file).
In this case, you should indicate using `field=XXX` the name of the field in the JSON structure which contains the records you want to load. The records can be a dict of lists or a list of dicts.
E.g. to load the SQuAD dataset JSON (without using the `squad` specific dataset loading script), in which the data rows are in the `data` field of the JSON dict, you can do:
```python
from nlp import load_dataset
dataset = load_dataset('json', data_files='/PATH/TO/JSON', field='data')
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/372/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/372/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/371
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/371/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/371/comments
|
https://api.github.com/repos/huggingface/datasets/issues/371/events
|
https://github.com/huggingface/datasets/pull/371
| 654,668,242
|
MDExOlB1bGxSZXF1ZXN0NDQ3MzQ4NDgw
| 371
|
Fix cached file path for metrics with different config names
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-07-10 10:02:24+00:00
|
2020-07-10 13:45:22+00:00
|
2020-07-10 13:45:20+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/371.diff",
"html_url": "https://github.com/huggingface/datasets/pull/371",
"merged_at": "2020-07-10T13:45:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/371.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/371"
}
|
The config name was not taken into account to build the cached file path.
It should fix #368
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/371/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/371/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/370
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/370/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/370/comments
|
https://api.github.com/repos/huggingface/datasets/issues/370/events
|
https://github.com/huggingface/datasets/pull/370
| 654,304,193
|
MDExOlB1bGxSZXF1ZXN0NDQ3MDU3NTIw
| 370
|
Allow indexing Dataset via np.ndarray
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists_url": "https://api.github.com/users/jarednielsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jarednielsen",
"id": 4564897,
"login": "jarednielsen",
"node_id": "MDQ6VXNlcjQ1NjQ4OTc=",
"organizations_url": "https://api.github.com/users/jarednielsen/orgs",
"received_events_url": "https://api.github.com/users/jarednielsen/received_events",
"repos_url": "https://api.github.com/users/jarednielsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jarednielsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jarednielsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jarednielsen",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-07-09 19:43:15+00:00
|
2020-07-10 14:05:44+00:00
|
2020-07-10 14:05:43+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/370.diff",
"html_url": "https://github.com/huggingface/datasets/pull/370",
"merged_at": "2020-07-10T14:05:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/370.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/370"
}
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/370/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/370/timeline
| null | null | null | null | true
|
|
https://api.github.com/repos/huggingface/datasets/issues/369
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/369/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/369/comments
|
https://api.github.com/repos/huggingface/datasets/issues/369/events
|
https://github.com/huggingface/datasets/issues/369
| 654,186,890
|
MDU6SXNzdWU2NTQxODY4OTA=
| 369
|
can't load local dataset: pyarrow.lib.ArrowInvalid: straddling object straddles two block boundaries
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/24683907?v=4",
"events_url": "https://api.github.com/users/vegarab/events{/privacy}",
"followers_url": "https://api.github.com/users/vegarab/followers",
"following_url": "https://api.github.com/users/vegarab/following{/other_user}",
"gists_url": "https://api.github.com/users/vegarab/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vegarab",
"id": 24683907,
"login": "vegarab",
"node_id": "MDQ6VXNlcjI0NjgzOTA3",
"organizations_url": "https://api.github.com/users/vegarab/orgs",
"received_events_url": "https://api.github.com/users/vegarab/received_events",
"repos_url": "https://api.github.com/users/vegarab/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vegarab/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vegarab/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vegarab",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
| null |
[] | null | 2
|
2020-07-09 16:16:53+00:00
|
2020-12-15 23:07:22+00:00
|
2020-07-10 14:52:06+00:00
|
CONTRIBUTOR
| null | null | null | null |
Trying to load a local SQuAD-formatted dataset (from a JSON file, about 60MB):
```
dataset = nlp.load_dataset(path='json', data_files={nlp.Split.TRAIN: ["./path/to/file.json"]})
```
causes
```
Traceback (most recent call last):
File "dataloader.py", line 9, in <module>
["./path/to/file.json"]})
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/load.py", line 524, in load_dataset
save_infos=save_infos,
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/builder.py", line 432, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/builder.py", line 483, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/builder.py", line 719, in _prepare_split
for key, table in utils.tqdm(generator, unit=" tables", leave=False):
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/tqdm/std.py", line 1129, in __iter__
for obj in iterable:
File "/home/XXX/.conda/envs/torch/lib/python3.7/site-packages/nlp/datasets/json/88c1bc5c68489f7eda549ed05a5a738527c613b3e7a4ee3524d9d233353a949b/json.py", line 53, in _generate_tables
file, read_options=self.config.pa_read_options, parse_options=self.config.pa_parse_options,
File "pyarrow/_json.pyx", line 191, in pyarrow._json.read_json
File "pyarrow/error.pxi", line 85, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: straddling object straddles two block boundaries (try to increase block size?)
```
I haven't been able to find any reports of this specific pyarrow error here or elsewhere.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/369/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/369/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/368
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/368/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/368/comments
|
https://api.github.com/repos/huggingface/datasets/issues/368/events
|
https://github.com/huggingface/datasets/issues/368
| 654,087,251
|
MDU6SXNzdWU2NTQwODcyNTE=
| 368
|
load_metric can't acquire lock anymore
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ydshieh",
"id": 2521628,
"login": "ydshieh",
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ydshieh",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-07-09 14:04:09+00:00
|
2020-07-10 13:45:20+00:00
|
2020-07-10 13:45:20+00:00
|
NONE
| null | null | null | null |
I can't load metric (glue) anymore after an error in a previous run. I even removed the whole cache folder `/home/XXX/.cache/huggingface/`, and the issue persisted. What are the steps to fix this?
Traceback (most recent call last):
File "/home/XXX/miniconda3/envs/ML-DL-py-3.7/lib/python3.7/site-packages/nlp/metric.py", line 101, in __init__
self.filelock.acquire(timeout=1)
File "/home/XXX/miniconda3/envs/ML-DL-py-3.7/lib/python3.7/site-packages/filelock.py", line 278, in acquire
raise Timeout(self._lock_file)
filelock.Timeout: The file lock '/home/XXX/.cache/huggingface/metrics/glue/1.0.0/1-glue-0.arrow.lock' could not be acquired.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "examples_huggingface_nlp.py", line 268, in <module>
main()
File "examples_huggingface_nlp.py", line 242, in main
dataset, metric = get_dataset_metric(glue_task)
File "examples_huggingface_nlp.py", line 77, in get_dataset_metric
metric = nlp.load_metric('glue', glue_config, experiment_id=1)
File "/home/XXX/miniconda3/envs/ML-DL-py-3.7/lib/python3.7/site-packages/nlp/load.py", line 440, in load_metric
**metric_init_kwargs,
File "/home/XXX/miniconda3/envs/ML-DL-py-3.7/lib/python3.7/site-packages/nlp/metric.py", line 104, in __init__
"Cannot acquire lock, caching file might be used by another process, "
ValueError: Cannot acquire lock, caching file might be used by another process, you should setup a unique 'experiment_id' for this run.
I0709 15:54:41.008838 139854118430464 filelock.py:318] Lock 139852058030936 released on /home/XXX/.cache/huggingface/metrics/glue/1.0.0/1-glue-0.arrow.lock
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/368/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/368/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/367
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/367/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/367/comments
|
https://api.github.com/repos/huggingface/datasets/issues/367/events
|
https://github.com/huggingface/datasets/pull/367
| 654,012,984
|
MDExOlB1bGxSZXF1ZXN0NDQ2ODIxNTAz
| 367
|
Update Xtreme to add PAWS-X es
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-09 12:14:37+00:00
|
2020-07-09 12:37:11+00:00
|
2020-07-09 12:37:10+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/367.diff",
"html_url": "https://github.com/huggingface/datasets/pull/367",
"merged_at": "2020-07-09T12:37:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/367.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/367"
}
|
This PR adds the `PAWS-X.es` in the Xtreme dataset #362
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/367/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/367/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/366
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/366/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/366/comments
|
https://api.github.com/repos/huggingface/datasets/issues/366/events
|
https://github.com/huggingface/datasets/pull/366
| 653,954,896
|
MDExOlB1bGxSZXF1ZXN0NDQ2NzcyODE2
| 366
|
Add quora dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13795113?v=4",
"events_url": "https://api.github.com/users/ghomasHudson/events{/privacy}",
"followers_url": "https://api.github.com/users/ghomasHudson/followers",
"following_url": "https://api.github.com/users/ghomasHudson/following{/other_user}",
"gists_url": "https://api.github.com/users/ghomasHudson/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ghomasHudson",
"id": 13795113,
"login": "ghomasHudson",
"node_id": "MDQ6VXNlcjEzNzk1MTEz",
"organizations_url": "https://api.github.com/users/ghomasHudson/orgs",
"received_events_url": "https://api.github.com/users/ghomasHudson/received_events",
"repos_url": "https://api.github.com/users/ghomasHudson/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ghomasHudson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghomasHudson/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ghomasHudson",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-07-09 10:34:22+00:00
|
2020-07-13 17:35:21+00:00
|
2020-07-13 17:35:21+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/366.diff",
"html_url": "https://github.com/huggingface/datasets/pull/366",
"merged_at": "2020-07-13T17:35:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/366.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/366"
}
|
Added the [Quora question pairs dataset](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs).
Implementation Notes:
- I used the original version provided on the quora website. There's also a [Kaggle competition](https://www.kaggle.com/c/quora-question-pairs) which has a nice train/test split but I can't find an easy way to download it.
- I've made the questions into a list:
```python
{
"questions": [
{"id":0, "text": "Is this an example question?"},
{"id":1, "text": "Is this a sample question?"},
],
...
}
```
rather than:
```python
{
"question1": "Is this an example question?",
"question2": "Is this a sample question?"
"qid0": 0
"qid1": 1
...
}
```
Not sure if this was the right call.
- Can't find a good citation for this dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/366/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/366/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/365
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/365/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/365/comments
|
https://api.github.com/repos/huggingface/datasets/issues/365/events
|
https://github.com/huggingface/datasets/issues/365
| 653,845,964
|
MDU6SXNzdWU2NTM4NDU5NjQ=
| 365
|
How to augment data ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 6
|
2020-07-09 07:52:37+00:00
|
2020-07-10 09:12:07+00:00
|
2020-07-10 08:22:15+00:00
|
NONE
| null | null | null | null |
Is there any clean way to augment data ?
For now my work-around is to use batched map, like this :
```python
def aug(samples):
# Simply copy the existing data to have x2 amount of data
for k, v in samples.items():
samples[k].extend(v)
return samples
dataset = dataset.map(aug, batched=True)
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/365/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/365/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/364
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/364/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/364/comments
|
https://api.github.com/repos/huggingface/datasets/issues/364/events
|
https://github.com/huggingface/datasets/pull/364
| 653,821,597
|
MDExOlB1bGxSZXF1ZXN0NDQ2NjY0NzM5
| 364
|
add MS MARCO dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 7
|
2020-07-09 07:11:19+00:00
|
2020-08-06 06:15:49+00:00
|
2020-08-06 06:15:48+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/364.diff",
"html_url": "https://github.com/huggingface/datasets/pull/364",
"merged_at": "2020-08-06T06:15:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/364.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/364"
}
|
This PR adds the MS MARCO dataset as requested in this issue #336. MS mARCO has multiple task including:
- Passage and Document Retrieval
- Keyphrase Extraction
- QA and NLG
This PR only adds the 2 versions of the QA and NLG task dataset which was realeased with the original paper here https://arxiv.org/pdf/1611.09268.pdf
Tests are failing because of the dummy data. I tried to fix it without success. Can you please have a look at it? @patrickvonplaten , @lhoestq
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/364/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/364/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/363
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/363/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/363/comments
|
https://api.github.com/repos/huggingface/datasets/issues/363/events
|
https://github.com/huggingface/datasets/pull/363
| 653,821,172
|
MDExOlB1bGxSZXF1ZXN0NDQ2NjY0NDIy
| 363
|
Adding support for generic multi dimensional tensors and auxillary image data for multimodal datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/14030663?v=4",
"events_url": "https://api.github.com/users/eltoto1219/events{/privacy}",
"followers_url": "https://api.github.com/users/eltoto1219/followers",
"following_url": "https://api.github.com/users/eltoto1219/following{/other_user}",
"gists_url": "https://api.github.com/users/eltoto1219/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/eltoto1219",
"id": 14030663,
"login": "eltoto1219",
"node_id": "MDQ6VXNlcjE0MDMwNjYz",
"organizations_url": "https://api.github.com/users/eltoto1219/orgs",
"received_events_url": "https://api.github.com/users/eltoto1219/received_events",
"repos_url": "https://api.github.com/users/eltoto1219/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/eltoto1219/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eltoto1219/subscriptions",
"type": "User",
"url": "https://api.github.com/users/eltoto1219",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 23
|
2020-07-09 07:10:30+00:00
|
2020-08-24 09:59:35+00:00
|
2020-08-24 09:59:35+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/363.diff",
"html_url": "https://github.com/huggingface/datasets/pull/363",
"merged_at": "2020-08-24T09:59:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/363.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/363"
}
|
nlp/features.py:
The main factory class is MultiArray, every single time this class is called, a corresponding pyarrow extension array and type class is generated (and added to the list of globals for future use) for a given root data type and set of dimensions/shape. I provide examples on working with this in datasets/lxmert_pretraining_beta/test_multi_array.py
src/nlp/arrow_writer.py
I had to add a method for writing batches that include extension array types because despite having a unique class for each multidimensional array shape, pyarrow is unable to write any other "array-like" data class to a batch object unless it is of the type pyarrow.ExtensionType. The problem in this is that when writing multiple batches, the order of the schema and data to be written get mixed up (where the pyarrow datatype in the schema only refers to as ExtensionAray, but each ExtensionArray subclass has a different shape) ... possibly I am missing something here and would be grateful if anyone else could take a look!
datasets/lxmert_pretraining_beta/lxmert_pretraining_beta.py & datasets/lxmert_pretraining_beta/to_arrow_data.py:
I have begun adding the data from the original LXMERT paper (https://arxiv.org/abs/1908.07490) hosted here: (https://github.com/airsplay/lxmert). The reason I am not pulling from the source of truth for each individual dataset is because it seems that there will also need to be functionality to aggregate multimodal datasets to create a pre-training corpus (:sleepy: ).
For now, this is just being used to test and run edge-cases for the MultiArray feature, so ive labeled it as "beta_pretraining"!
(still working on the pretraining, just wanted to push out the new functionality sooner than later)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/363/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/363/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/362
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/362/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/362/comments
|
https://api.github.com/repos/huggingface/datasets/issues/362/events
|
https://github.com/huggingface/datasets/issues/362
| 653,766,245
|
MDU6SXNzdWU2NTM3NjYyNDU=
| 362
|
[dateset subset missing] xtreme paws-x
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/50871412?v=4",
"events_url": "https://api.github.com/users/cosmeowpawlitan/events{/privacy}",
"followers_url": "https://api.github.com/users/cosmeowpawlitan/followers",
"following_url": "https://api.github.com/users/cosmeowpawlitan/following{/other_user}",
"gists_url": "https://api.github.com/users/cosmeowpawlitan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cosmeowpawlitan",
"id": 50871412,
"login": "cosmeowpawlitan",
"node_id": "MDQ6VXNlcjUwODcxNDEy",
"organizations_url": "https://api.github.com/users/cosmeowpawlitan/orgs",
"received_events_url": "https://api.github.com/users/cosmeowpawlitan/received_events",
"repos_url": "https://api.github.com/users/cosmeowpawlitan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cosmeowpawlitan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cosmeowpawlitan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cosmeowpawlitan",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-07-09 05:04:54+00:00
|
2020-07-09 12:38:42+00:00
|
2020-07-09 12:38:42+00:00
|
CONTRIBUTOR
| null | null | null | null |
I tried nlp.load_dataset('xtreme', 'PAWS-X.es') but get the value error
It turns out that the subset for Spanish is missing
https://github.com/google-research-datasets/paws/tree/master/pawsx
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/362/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/362/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/361
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/361/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/361/comments
|
https://api.github.com/repos/huggingface/datasets/issues/361/events
|
https://github.com/huggingface/datasets/issues/361
| 653,757,376
|
MDU6SXNzdWU2NTM3NTczNzY=
| 361
|
🐛 [Metrics] ROUGE is non-deterministic
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 8
|
2020-07-09 04:39:37+00:00
|
2022-09-09 15:20:55+00:00
|
2020-07-20 23:48:37+00:00
|
NONE
| null | null | null | null |
If I run the ROUGE metric 2 times, with same predictions / references, the scores are slightly different.
Refer to [this Colab notebook](https://colab.research.google.com/drive/1wRssNXgb9ldcp4ulwj-hMJn0ywhDOiDy?usp=sharing) for reproducing the problem.
Example of F-score for ROUGE-1, ROUGE-2, ROUGE-L in 2 differents run :
> ['0.3350', '0.1470', '0.2329']
['0.3358', '0.1451', '0.2332']
---
Why ROUGE is not deterministic ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/361/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/361/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/360
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/360/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/360/comments
|
https://api.github.com/repos/huggingface/datasets/issues/360/events
|
https://github.com/huggingface/datasets/issues/360
| 653,687,176
|
MDU6SXNzdWU2NTM2ODcxNzY=
| 360
|
[Feature request] Add dataset.ragged_map() function for many-to-many transformations
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists_url": "https://api.github.com/users/jarednielsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jarednielsen",
"id": 4564897,
"login": "jarednielsen",
"node_id": "MDQ6VXNlcjQ1NjQ4OTc=",
"organizations_url": "https://api.github.com/users/jarednielsen/orgs",
"received_events_url": "https://api.github.com/users/jarednielsen/received_events",
"repos_url": "https://api.github.com/users/jarednielsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jarednielsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jarednielsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jarednielsen",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-07-09 01:04:43+00:00
|
2020-07-09 19:31:51+00:00
|
2020-07-09 19:31:51+00:00
|
CONTRIBUTOR
| null | null | null | null |
`dataset.map()` enables one-to-one transformations. Input one example and output one example. This is helpful for tokenizing and cleaning individual lines.
`dataset.filter()` enables one-to-(one-or-none) transformations. Input one example and output either zero/one example. This is helpful for removing portions from the dataset.
However, some dataset transformations are many-to-many. Consider constructing BERT training examples from a dataset of sentences, where you map `["a", "b", "c"] -> ["a[SEP]b", "a[SEP]c", "b[SEP]c", "c[SEP]b", ...]`
I propose a more general `ragged_map()` method that takes in a batch of examples of length `N` and return a batch of examples `M`. This is different from the `map(batched=True)` method, which takes examples of length `N` and returns a batch of length `N`, processing individual examples in parallel. I don't have a clear vision of how this would be implemented efficiently and lazily, but would love to hear the community's feedback on this.
My specific use case is creating an end-to-end ELECTRA data pipeline. I would like to take the raw WikiText data and generate training examples from this using the `ragged_map()` method, then export to TFRecords and train quickly. This would be a reproducible pipeline with no bash scripts. Currently I'm relying on scripts like https://github.com/google-research/electra/blob/master/build_pretraining_dataset.py, which are less general.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists_url": "https://api.github.com/users/jarednielsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jarednielsen",
"id": 4564897,
"login": "jarednielsen",
"node_id": "MDQ6VXNlcjQ1NjQ4OTc=",
"organizations_url": "https://api.github.com/users/jarednielsen/orgs",
"received_events_url": "https://api.github.com/users/jarednielsen/received_events",
"repos_url": "https://api.github.com/users/jarednielsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jarednielsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jarednielsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jarednielsen",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/360/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/360/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/359
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/359/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/359/comments
|
https://api.github.com/repos/huggingface/datasets/issues/359/events
|
https://github.com/huggingface/datasets/issues/359
| 653,656,279
|
MDU6SXNzdWU2NTM2NTYyNzk=
| 359
|
ArrowBasedBuilder _prepare_split parse_schema breaks on nested structures
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2000204?v=4",
"events_url": "https://api.github.com/users/timothyjlaurent/events{/privacy}",
"followers_url": "https://api.github.com/users/timothyjlaurent/followers",
"following_url": "https://api.github.com/users/timothyjlaurent/following{/other_user}",
"gists_url": "https://api.github.com/users/timothyjlaurent/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/timothyjlaurent",
"id": 2000204,
"login": "timothyjlaurent",
"node_id": "MDQ6VXNlcjIwMDAyMDQ=",
"organizations_url": "https://api.github.com/users/timothyjlaurent/orgs",
"received_events_url": "https://api.github.com/users/timothyjlaurent/received_events",
"repos_url": "https://api.github.com/users/timothyjlaurent/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/timothyjlaurent/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/timothyjlaurent/subscriptions",
"type": "User",
"url": "https://api.github.com/users/timothyjlaurent",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 4
|
2020-07-08 23:24:05+00:00
|
2020-07-10 14:52:06+00:00
|
2020-07-10 14:52:06+00:00
|
NONE
| null | null | null | null |
I tried using the Json dataloader to load some JSON lines files. but get an exception in the parse_schema function.
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-23-9aecfbee53bd> in <module>
55 from nlp import load_dataset
56
---> 57 ds = load_dataset("../text2struct/model/dataset_builder.py", data_files=rel_datafiles)
58
59
~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
522 download_mode=download_mode,
523 ignore_verifications=ignore_verifications,
--> 524 save_infos=save_infos,
525 )
526
~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
430 verify_infos = not save_infos and not ignore_verifications
431 self._download_and_prepare(
--> 432 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
433 )
434 # Sync info
~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
481 try:
482 # Prepare split will record examples associated to the split
--> 483 self._prepare_split(split_generator, **prepare_split_kwargs)
484 except OSError:
485 raise OSError("Cannot find data file. " + (self.manual_download_instructions or ""))
~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/builder.py in _prepare_split(self, split_generator)
736 schema_dict[field.name] = Value(str(field.type))
737
--> 738 parse_schema(writer.schema, features)
739 self.info.features = Features(features)
740
~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/builder.py in parse_schema(schema, schema_dict)
734 parse_schema(field.type.value_type, schema_dict[field.name])
735 else:
--> 736 schema_dict[field.name] = Value(str(field.type))
737
738 parse_schema(writer.schema, features)
<string> in __init__(self, dtype, id, _type)
~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/features.py in __post_init__(self)
55
56 def __post_init__(self):
---> 57 self.pa_type = string_to_arrow(self.dtype)
58
59 def __call__(self):
~/.virtualenvs/inv-text2struct/lib/python3.6/site-packages/nlp/features.py in string_to_arrow(type_str)
32 if str(type_str + "_") not in pa.__dict__:
33 raise ValueError(
---> 34 f"Neither {type_str} nor {type_str + '_'} seems to be a pyarrow data type. "
35 f"Please make sure to use a correct data type, see: "
36 f"https://arrow.apache.org/docs/python/api/datatypes.html#factory-functions"
ValueError: Neither list<item: string> nor list<item: string>_ seems to be a pyarrow data type. Please make sure to use a correct data type, see: https://arrow.apache.org/docs/python/api/datatypes.html#factory-functions
```
If I create the dataset imperatively, using a pyarrow table, the dataset is created correctly. If I override the `_prepare_split` method to avoid calling the validate schema, the dataset can load as well.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/359/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/359/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/358
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/358/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/358/comments
|
https://api.github.com/repos/huggingface/datasets/issues/358/events
|
https://github.com/huggingface/datasets/pull/358
| 653,645,121
|
MDExOlB1bGxSZXF1ZXN0NDQ2NTI0NjQ5
| 358
|
Starting to add some real doc
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-07-08 22:53:03+00:00
|
2020-07-14 09:58:17+00:00
|
2020-07-14 09:58:15+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/358.diff",
"html_url": "https://github.com/huggingface/datasets/pull/358",
"merged_at": "2020-07-14T09:58:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/358.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/358"
}
|
Adding a lot of documentation for:
- load a dataset
- explore the dataset object
- process data with the dataset
- add a new dataset script
- share a dataset script
- full package reference
This version of the doc can be explored here: https://2219-250213286-gh.circle-artifacts.com/0/docs/_build/html/index.html
Also:
- fix a bug in `train_test_split`
- update the `csv` script
- add a verbose argument to the dataset processing methods
Still missing:
- doc for the metrics
- how to directly upload a community provided dataset with the CLI
- clean up more docstrings
- add the `features` argument to `load_dataset` (should be another PR)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/358/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/358/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/357
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/357/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/357/comments
|
https://api.github.com/repos/huggingface/datasets/issues/357/events
|
https://github.com/huggingface/datasets/pull/357
| 653,642,292
|
MDExOlB1bGxSZXF1ZXN0NDQ2NTIyMzU2
| 357
|
Add hashes to cnn_dailymail
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2238344?v=4",
"events_url": "https://api.github.com/users/jbragg/events{/privacy}",
"followers_url": "https://api.github.com/users/jbragg/followers",
"following_url": "https://api.github.com/users/jbragg/following{/other_user}",
"gists_url": "https://api.github.com/users/jbragg/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jbragg",
"id": 2238344,
"login": "jbragg",
"node_id": "MDQ6VXNlcjIyMzgzNDQ=",
"organizations_url": "https://api.github.com/users/jbragg/orgs",
"received_events_url": "https://api.github.com/users/jbragg/received_events",
"repos_url": "https://api.github.com/users/jbragg/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jbragg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jbragg/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jbragg",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-07-08 22:45:21+00:00
|
2020-07-13 14:16:38+00:00
|
2020-07-13 14:16:38+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/357.diff",
"html_url": "https://github.com/huggingface/datasets/pull/357",
"merged_at": "2020-07-13T14:16:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/357.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/357"
}
|
The URL hashes are helpful for comparing results from other sources.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/357/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/357/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/356
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/356/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/356/comments
|
https://api.github.com/repos/huggingface/datasets/issues/356/events
|
https://github.com/huggingface/datasets/pull/356
| 653,537,388
|
MDExOlB1bGxSZXF1ZXN0NDQ2NDM3MDQ5
| 356
|
Add text dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists_url": "https://api.github.com/users/jarednielsen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jarednielsen",
"id": 4564897,
"login": "jarednielsen",
"node_id": "MDQ6VXNlcjQ1NjQ4OTc=",
"organizations_url": "https://api.github.com/users/jarednielsen/orgs",
"received_events_url": "https://api.github.com/users/jarednielsen/received_events",
"repos_url": "https://api.github.com/users/jarednielsen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jarednielsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jarednielsen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jarednielsen",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-08 19:21:53+00:00
|
2020-07-10 14:19:03+00:00
|
2020-07-10 14:19:03+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/356.diff",
"html_url": "https://github.com/huggingface/datasets/pull/356",
"merged_at": "2020-07-10T14:19:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/356.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/356"
}
|
Usage:
```python
from nlp import load_dataset
dset = load_dataset("text", data_files="/path/to/file.txt")["train"]
```
I created a dummy_data.zip which contains three files: `train.txt`, `test.txt`, `dev.txt`. Each of these contains two lines. It passes
```bash
RUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_dataset_all_configs_text
```
but I would like a second set of eyes to ensure I did it right.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 3,
"laugh": 0,
"rocket": 0,
"total_count": 6,
"url": "https://api.github.com/repos/huggingface/datasets/issues/356/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/356/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/355
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/355/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/355/comments
|
https://api.github.com/repos/huggingface/datasets/issues/355/events
|
https://github.com/huggingface/datasets/issues/355
| 653,451,013
|
MDU6SXNzdWU2NTM0NTEwMTM=
| 355
|
can't load SNLI dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jxmorris12",
"id": 13238952,
"login": "jxmorris12",
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jxmorris12",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 3
|
2020-07-08 16:54:14+00:00
|
2020-07-18 05:15:57+00:00
|
2020-07-15 07:59:01+00:00
|
CONTRIBUTOR
| null | null | null | null |
`nlp` seems to load `snli` from some URL based on nlp.stanford.edu. This subdomain is frequently down -- including right now, when I'd like to load `snli` in a Colab notebook, but can't.
Is there a plan to move these datasets to huggingface servers for a more stable solution?
Btw, here's the stack trace:
```
File "/content/nlp/src/nlp/builder.py", line 432, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/content/nlp/src/nlp/builder.py", line 466, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/content/nlp/src/nlp/datasets/snli/e417f6f2e16254938d977a17ed32f3998f5b23e4fcab0f6eb1d28784f23ea60d/snli.py", line 76, in _split_generators
dl_dir = dl_manager.download_and_extract(_DATA_URL)
File "/content/nlp/src/nlp/utils/download_manager.py", line 217, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/content/nlp/src/nlp/utils/download_manager.py", line 156, in download
lambda url: cached_path(url, download_config=self._download_config,), url_or_urls,
File "/content/nlp/src/nlp/utils/py_utils.py", line 190, in map_nested
return function(data_struct)
File "/content/nlp/src/nlp/utils/download_manager.py", line 156, in <lambda>
lambda url: cached_path(url, download_config=self._download_config,), url_or_urls,
File "/content/nlp/src/nlp/utils/file_utils.py", line 198, in cached_path
local_files_only=download_config.local_files_only,
File "/content/nlp/src/nlp/utils/file_utils.py", line 356, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://nlp.stanford.edu/projects/snli/snli_1.0.zip
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/355/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/355/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/354
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/354/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/354/comments
|
https://api.github.com/repos/huggingface/datasets/issues/354/events
|
https://github.com/huggingface/datasets/pull/354
| 653,357,617
|
MDExOlB1bGxSZXF1ZXN0NDQ2MjkyMTc4
| 354
|
More faiss control
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 1
|
2020-07-08 14:45:20+00:00
|
2020-07-09 09:54:54+00:00
|
2020-07-09 09:54:51+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/354.diff",
"html_url": "https://github.com/huggingface/datasets/pull/354",
"merged_at": "2020-07-09T09:54:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/354.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/354"
}
|
Allow users to specify a faiss index they created themselves, as sometimes indexes can be composite for examples
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/354/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/354/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/353
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/353/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/353/comments
|
https://api.github.com/repos/huggingface/datasets/issues/353/events
|
https://github.com/huggingface/datasets/issues/353
| 653,250,611
|
MDU6SXNzdWU2NTMyNTA2MTE=
| 353
|
[Dataset requests] New datasets for Text Classification
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
[
{
"color": "008672",
"default": true,
"description": "Extra attention is needed",
"id": 1935892884,
"name": "help wanted",
"node_id": "MDU6TGFiZWwxOTM1ODkyODg0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/help%20wanted"
},
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
open
| false
| null |
[] | null | 12
|
2020-07-08 12:17:58+00:00
|
2025-04-05 09:28:15+00:00
|
NaT
|
MEMBER
| null | null | null | null |
We are missing a few datasets for Text Classification which is an important field.
Namely, it would be really nice to add:
- [x] TREC-6 dataset (see here for instance: https://pytorchnlp.readthedocs.io/en/latest/source/torchnlp.datasets.html#torchnlp.datasets.trec_dataset) **[done]**
- #386
- [x] Yelp-5
- #1315
- [x] Movie review (Movie Review (MR) dataset [156]) **[done (same as rotten_tomatoes)]**
- [x] SST (Stanford Sentiment Treebank) **[include in glue]**
- #1934
- [ ] Multi-Perspective Question Answering (MPQA) dataset **[require authentication (indeed manual download)]**
- [x] Amazon. This is a popular corpus of product reviews collected from the Amazon website [159]. It contains labels for both binary classification and multi-class (5-class) classification
- #791
- #1389
- [x] 20 Newsgroups. The 20 Newsgroups dataset **[done]**
- #410
- [x] Sogou News dataset **[done]**
- #450
- [x] Reuters news. The Reuters-21578 dataset [165] **[done]**
- #471
- [x] DBpedia. The DBpedia dataset [170]
- #1116
- [ ] Ohsumed. The Ohsumed collection [171] is a subset of the MEDLINE database
- [ ] EUR-Lex. The EUR-Lex dataset
- [x] WOS. The Web Of Science (WOS) dataset **[done]**
- #424
- [ ] PubMed. PubMed [173]
- [x] TREC-QA: TREC-6 + TREC-50
- See above: TREC-6 dataset
- [x] Quora. The Quora dataset [180]
- #366
All these datasets are cited in https://arxiv.org/abs/2004.03705
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/353/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/353/timeline
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/352
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/352/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/352/comments
|
https://api.github.com/repos/huggingface/datasets/issues/352/events
|
https://github.com/huggingface/datasets/pull/352
| 653,128,883
|
MDExOlB1bGxSZXF1ZXN0NDQ2MTA1Mjky
| 352
|
🐛[BugFix]fix seqeval
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20281571?v=4",
"events_url": "https://api.github.com/users/AlongWY/events{/privacy}",
"followers_url": "https://api.github.com/users/AlongWY/followers",
"following_url": "https://api.github.com/users/AlongWY/following{/other_user}",
"gists_url": "https://api.github.com/users/AlongWY/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AlongWY",
"id": 20281571,
"login": "AlongWY",
"node_id": "MDQ6VXNlcjIwMjgxNTcx",
"organizations_url": "https://api.github.com/users/AlongWY/orgs",
"received_events_url": "https://api.github.com/users/AlongWY/received_events",
"repos_url": "https://api.github.com/users/AlongWY/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AlongWY/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AlongWY/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AlongWY",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 7
|
2020-07-08 09:12:12+00:00
|
2020-07-16 08:26:46+00:00
|
2020-07-16 08:26:46+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/352.diff",
"html_url": "https://github.com/huggingface/datasets/pull/352",
"merged_at": "2020-07-16T08:26:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/352.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/352"
}
|
Fix seqeval process labels such as 'B', 'B-ARGM-LOC'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/352/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/352/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/351
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/351/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/351/comments
|
https://api.github.com/repos/huggingface/datasets/issues/351/events
|
https://github.com/huggingface/datasets/pull/351
| 652,424,048
|
MDExOlB1bGxSZXF1ZXN0NDQ1NDk0NTE4
| 351
|
add pandas dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-07 15:38:07+00:00
|
2020-07-08 14:15:16+00:00
|
2020-07-08 14:15:15+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/351.diff",
"html_url": "https://github.com/huggingface/datasets/pull/351",
"merged_at": "2020-07-08T14:15:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/351.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/351"
}
|
Create a dataset from serialized pandas dataframes.
Usage:
```python
from nlp import load_dataset
dset = load_dataset("pandas", data_files="df.pkl")["train"]
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/351/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/351/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/350
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/350/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/350/comments
|
https://api.github.com/repos/huggingface/datasets/issues/350/events
|
https://github.com/huggingface/datasets/pull/350
| 652,398,691
|
MDExOlB1bGxSZXF1ZXN0NDQ1NDczODYz
| 350
|
add from_pandas and from_dict
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 0
|
2020-07-07 15:03:53+00:00
|
2020-07-08 14:14:33+00:00
|
2020-07-08 14:14:32+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/350.diff",
"html_url": "https://github.com/huggingface/datasets/pull/350",
"merged_at": "2020-07-08T14:14:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/350.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/350"
}
|
I added two new methods to the `Dataset` class:
- `from_pandas()` to create a dataset from a pandas dataframe
- `from_dict()` to create a dataset from a dictionary (keys = columns)
It uses the `pa.Table.from_pandas` and `pa.Table.from_pydict` funcitons to do so.
It is also possible to specify the features types via `features=...` if there are ambiguities (null/nan values), otherwise the arrow schema is infered from the data automatically by pyarrow.
One question that I have right now:
+ Should we also add a `save()` method that would write the dataset on the disk ? Right now if we create a `Dataset` using those two new methods, the data are kept in RAM. Then to reload it we can call the `from_file()` method.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/350/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/350/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/349
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/349/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/349/comments
|
https://api.github.com/repos/huggingface/datasets/issues/349/events
|
https://github.com/huggingface/datasets/pull/349
| 652,231,571
|
MDExOlB1bGxSZXF1ZXN0NDQ1MzQwMTQ1
| 349
|
Hyperpartisan news detection
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/13795113?v=4",
"events_url": "https://api.github.com/users/ghomasHudson/events{/privacy}",
"followers_url": "https://api.github.com/users/ghomasHudson/followers",
"following_url": "https://api.github.com/users/ghomasHudson/following{/other_user}",
"gists_url": "https://api.github.com/users/ghomasHudson/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ghomasHudson",
"id": 13795113,
"login": "ghomasHudson",
"node_id": "MDQ6VXNlcjEzNzk1MTEz",
"organizations_url": "https://api.github.com/users/ghomasHudson/orgs",
"received_events_url": "https://api.github.com/users/ghomasHudson/received_events",
"repos_url": "https://api.github.com/users/ghomasHudson/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ghomasHudson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghomasHudson/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ghomasHudson",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 2
|
2020-07-07 11:06:37+00:00
|
2020-07-07 20:47:27+00:00
|
2020-07-07 14:57:11+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/349.diff",
"html_url": "https://github.com/huggingface/datasets/pull/349",
"merged_at": "2020-07-07T14:57:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/349.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/349"
}
|
Adding the hyperpartisan news detection dataset from PAN. This contains news article text, labelled with whether they're hyper-partisan and why kinds of biases they display.
Implementation notes:
- As with many PAN tasks, the data is hosted on [Zenodo](https://zenodo.org/record/1489920) and must be requested before use. I've used the manual download stuff for this, although the dataset is provided under a Creative Commons Attribution 4.0 International License, so we could host a version if we wanted to?
- The 'bias' attribute doesn't exist for the 'byarticle' configuration. I've added an empty string to the class labels to deal with this. Is there a more standard value for empty data?
- Should we always subclass `nlp.BuilderConfig`?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/349/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/349/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/348
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/348/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/348/comments
|
https://api.github.com/repos/huggingface/datasets/issues/348/events
|
https://github.com/huggingface/datasets/pull/348
| 652,158,308
|
MDExOlB1bGxSZXF1ZXN0NDQ1MjgwNjk3
| 348
|
Add OSCAR dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/635220?v=4",
"events_url": "https://api.github.com/users/pjox/events{/privacy}",
"followers_url": "https://api.github.com/users/pjox/followers",
"following_url": "https://api.github.com/users/pjox/following{/other_user}",
"gists_url": "https://api.github.com/users/pjox/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pjox",
"id": 635220,
"login": "pjox",
"node_id": "MDQ6VXNlcjYzNTIyMA==",
"organizations_url": "https://api.github.com/users/pjox/orgs",
"received_events_url": "https://api.github.com/users/pjox/received_events",
"repos_url": "https://api.github.com/users/pjox/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pjox/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pjox/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pjox",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 20
|
2020-07-07 09:22:07+00:00
|
2021-05-03 22:07:08+00:00
|
2021-02-09 10:19:19+00:00
|
CONTRIBUTOR
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/348.diff",
"html_url": "https://github.com/huggingface/datasets/pull/348",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/348.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/348"
}
|
I don't know if tests pass, when I run them it tries to download the whole corpus which is around 3.5TB compressed and I don't have that kind of space. I'll really need some help with it 😅
Thanks!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 4,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/348/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/348/timeline
| null | null | null | null | true
|
https://api.github.com/repos/huggingface/datasets/issues/347
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/347/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/347/comments
|
https://api.github.com/repos/huggingface/datasets/issues/347/events
|
https://github.com/huggingface/datasets/issues/347
| 652,106,567
|
MDU6SXNzdWU2NTIxMDY1Njc=
| 347
|
'cp950' codec error from load_dataset('xtreme', 'tydiqa')
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/50871412?v=4",
"events_url": "https://api.github.com/users/cosmeowpawlitan/events{/privacy}",
"followers_url": "https://api.github.com/users/cosmeowpawlitan/followers",
"following_url": "https://api.github.com/users/cosmeowpawlitan/following{/other_user}",
"gists_url": "https://api.github.com/users/cosmeowpawlitan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cosmeowpawlitan",
"id": 50871412,
"login": "cosmeowpawlitan",
"node_id": "MDQ6VXNlcjUwODcxNDEy",
"organizations_url": "https://api.github.com/users/cosmeowpawlitan/orgs",
"received_events_url": "https://api.github.com/users/cosmeowpawlitan/received_events",
"repos_url": "https://api.github.com/users/cosmeowpawlitan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cosmeowpawlitan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cosmeowpawlitan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cosmeowpawlitan",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
| null |
[] | null | 10
|
2020-07-07 08:14:23+00:00
|
2020-09-07 14:51:45+00:00
|
2020-09-07 14:51:45+00:00
|
CONTRIBUTOR
| null | null | null | null |

I guess the error is related to python source encoding issue that my PC is trying to decode the source code with wrong encoding-decoding tools, perhaps :
https://www.python.org/dev/peps/pep-0263/
I guess the error was triggered by the code " module = importlib.import_module(module_path)" at line 57 in the source code: nlp/src/nlp/load.py / (https://github.com/huggingface/nlp/blob/911d5596f9b500e39af8642fe3d1b891758999c7/src/nlp/load.py#L51)
Any ideas?
p.s. tried the same code on colab, that runs perfectly
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/347/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/347/timeline
| null |
completed
|
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
{
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
}
| false
|
https://api.github.com/repos/huggingface/datasets/issues/346
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/346/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/346/comments
|
https://api.github.com/repos/huggingface/datasets/issues/346/events
|
https://github.com/huggingface/datasets/pull/346
| 652,044,151
|
MDExOlB1bGxSZXF1ZXN0NDQ1MTg4MTUz
| 346
|
Add emotion dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null | 9
|
2020-07-07 06:35:41+00:00
|
2022-05-30 15:16:44+00:00
|
2020-07-13 14:39:38+00:00
|
MEMBER
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/346.diff",
"html_url": "https://github.com/huggingface/datasets/pull/346",
"merged_at": "2020-07-13T14:39:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/346.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/346"
}
|
Hello 🤗 team!
I am trying to add an emotion classification dataset ([link](https://github.com/dair-ai/emotion_dataset)) to `nlp` but I am a bit stuck about what I should do when the URL for the dataset is not a ZIP file, but just a pickled `pandas.DataFrame` (see [here](https://www.dropbox.com/s/607ptdakxuh5i4s/merged_training.pkl)).
With the current implementation, running
```bash
python nlp-cli test datasets/emotion --save_infos --all_configs
```
throws a `_pickle.UnpicklingError: invalid load key, '<'.` error (full stack trace below). The strange thing is that the path to the file does not carry the `.pkl` extension and instead appears to be some md5 hash (see the `FILE PATH` print statement in the stack trace).
Note: I have checked that the `merged_training.pkl` file is not corrupted when I download it with `wget`.
Any pointers on what I'm doing wrong would be greatly appreciated!
**Stack trace**
```
INFO:nlp.load:Checking datasets/emotion/emotion.py for additional imports.
INFO:filelock:Lock 140330435928512 acquired on datasets/emotion/emotion.py.lock
INFO:nlp.load:Found main folder for dataset datasets/emotion/emotion.py at /Users/lewtun/git/nlp/src/nlp/datasets/emotion
INFO:nlp.load:Creating specific version folder for dataset datasets/emotion/emotion.py at /Users/lewtun/git/nlp/src/nlp/datasets/emotion/59666994754d1b369228a749b695e377643d141fa98c6972be00407659788c7b
INFO:nlp.load:Copying script file from datasets/emotion/emotion.py to /Users/lewtun/git/nlp/src/nlp/datasets/emotion/59666994754d1b369228a749b695e377643d141fa98c6972be00407659788c7b/emotion.py
INFO:nlp.load:Couldn't find dataset infos file at datasets/emotion/dataset_infos.json
INFO:nlp.load:Creating metadata file for dataset datasets/emotion/emotion.py at /Users/lewtun/git/nlp/src/nlp/datasets/emotion/59666994754d1b369228a749b695e377643d141fa98c6972be00407659788c7b/emotion.json
INFO:filelock:Lock 140330435928512 released on datasets/emotion/emotion.py.lock
INFO:nlp.builder:Generating dataset emotion (/Users/lewtun/.cache/huggingface/datasets/emotion/emotion/1.0.0)
INFO:nlp.builder:Dataset not on Hf google storage. Downloading and preparing it from source
Downloading and preparing dataset emotion/emotion (download: Unknown size, generated: Unknown size, total: Unknown size) to /Users/lewtun/.cache/huggingface/datasets/emotion/emotion/1.0.0...
INFO:nlp.builder:Generating split train
0 examples [00:00, ? examples/s]FILE PATH /Users/lewtun/.cache/huggingface/datasets/3615dcb52b7ba052ef63e1571894c4b67e8e12a6ab1ef2f756ec3c380bf48490
Traceback (most recent call last):
File "nlp-cli", line 37, in <module>
service.run()
File "/Users/lewtun/git/nlp/src/nlp/commands/test.py", line 83, in run
builder.download_and_prepare(
File "/Users/lewtun/git/nlp/src/nlp/builder.py", line 431, in download_and_prepare
self._download_and_prepare(
File "/Users/lewtun/git/nlp/src/nlp/builder.py", line 483, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/Users/lewtun/git/nlp/src/nlp/builder.py", line 664, in _prepare_split
for key, record in utils.tqdm(generator, unit=" examples", total=split_info.num_examples, leave=False):
File "/Users/lewtun/miniconda3/envs/nlp/lib/python3.8/site-packages/tqdm/std.py", line 1129, in __iter__
for obj in iterable:
File "/Users/lewtun/git/nlp/src/nlp/datasets/emotion/59666994754d1b369228a749b695e377643d141fa98c6972be00407659788c7b/emotion.py", line 87, in _generate_examples
data = pickle.load(f)
_pickle.UnpicklingError: invalid load key, '<'.
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/346/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/346/timeline
| null | null | null | null | true
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.