
url
string | html_url
string | issue_url
string | id
int64 | node_id
string | user_login
string | user_id
int64 | user_node_id
string | user_avatar_url
string | user_gravatar_id
string | user_url
string | user_html_url
string | user_followers_url
string | user_following_url
string | user_gists_url
string | user_starred_url
string | user_subscriptions_url
string | user_organizations_url
string | user_repos_url
string | user_events_url
string | user_received_events_url
string | user_type
string | user_user_view_type
string | user_site_admin
bool | created_at
timestamp[s] | updated_at
timestamp[s] | body
string | author_association
string | reactions_url
string | reactions_total_count
int64 | reactions_+1
int64 | reactions_-1
int64 | reactions_laugh
int64 | reactions_hooray
int64 | reactions_confused
int64 | reactions_heart
int64 | reactions_rocket
int64 | reactions_eyes
int64 | performed_via_github_app
null |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/comments/613615849
|
https://github.com/huggingface/datasets/issues/2#issuecomment-613615849
|
https://api.github.com/repos/huggingface/datasets/issues/2
| 613,615,849
|
MDEyOklzc3VlQ29tbWVudDYxMzYxNTg0OQ==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-04-14T18:45:40
| 2020-04-14T18:45:40
|
My first bug report ❤️
Looking into this right now!
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/613615849/reactions
| 2
| 2
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/613877975
|
https://github.com/huggingface/datasets/issues/2#issuecomment-613877975
|
https://api.github.com/repos/huggingface/datasets/issues/2
| 613,877,975
|
MDEyOklzc3VlQ29tbWVudDYxMzg3Nzk3NQ==
|
jplu
| 959,590
|
MDQ6VXNlcjk1OTU5MA==
|
https://avatars.githubusercontent.com/u/959590?v=4
|
https://api.github.com/users/jplu
|
https://github.com/jplu
|
https://api.github.com/users/jplu/followers
|
https://api.github.com/users/jplu/following{/other_user}
|
https://api.github.com/users/jplu/gists{/gist_id}
|
https://api.github.com/users/jplu/starred{/owner}{/repo}
|
https://api.github.com/users/jplu/subscriptions
|
https://api.github.com/users/jplu/orgs
|
https://api.github.com/users/jplu/repos
|
https://api.github.com/users/jplu/events{/privacy}
|
https://api.github.com/users/jplu/received_events
|
User
|
public
| false
| 2020-04-15T07:52:18
| 2020-04-15T07:52:18
|
Ok, there are some news, most good than bad :laughing:
The dataset script now became:
```python
import csv
import nlp
class Bbc(nlp.GeneratorBasedBuilder):
VERSION = nlp.Version("1.0.0")
def __init__(self, **config):
self.train = config.pop("train", None)
self.validation = config.pop("validation", None)
super(Bbc, self).__init__(**config)
def _info(self):
return nlp.DatasetInfo(builder=self, description="bla", features=nlp.features.FeaturesDict({"id": nlp.int32, "text": nlp.string, "label": nlp.string}))
def _split_generators(self, dl_manager):
return [nlp.SplitGenerator(name=nlp.Split.TRAIN, gen_kwargs={"filepath": self.train}),
nlp.SplitGenerator(name=nlp.Split.VALIDATION, gen_kwargs={"filepath": self.validation})]
def _generate_examples(self, filepath):
with open(filepath) as f:
reader = csv.reader(f, delimiter=',', quotechar="\"")
lines = list(reader)[1:]
for idx, line in enumerate(lines):
yield idx, {"id": idx, "text": line[1], "label": line[0]}
```
And the dataset folder becomes:
```
.
├── bbc
│ ├── bbc.py
│ └── data
│ ├── test.csv
│ └── train.csv
```
I can load the dataset by using the keywords arguments like this:
```python
import nlp
dataset = nlp.load("bbc", builder_kwargs={"train": "bbc/data/train.csv", "validation": "bbc/data/test.csv"})
```
That was the good part ^^ Because it took me some time to understand that the script itself is put in cache in `datasets/src/nlp/datasets/some-hash/bbc.py` which is very difficult to discover without checking the source code. It means that doesn't matter the changes you do to your original script it is taken into account. I think instead of doing a hash on the name (I suppose it is the name), a hash on the content of the script itself should be a better solution.
Then by diving a bit in the code I found the `force_reload` parameter [here](https://github.com/huggingface/datasets/blob/master/src/nlp/load.py#L50) but the call of this `load_dataset` method is done with the `builder_kwargs` as seen [here](https://github.com/huggingface/datasets/blob/master/src/nlp/load.py#L166) which is ok until the call to the builder is done as the builder do not have this `force_reload` parameter. To show as example, the previous load becomes:
```python
import nlp
dataset = nlp.load("bbc", builder_kwargs={"train": "bbc/data/train.csv", "validation": "bbc/data/test.csv", "force_reload": True})
```
Raises
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jplu/dev/jplu/datasets/src/nlp/load.py", line 283, in load
dbuilder: DatasetBuilder = builder(path, name, data_dir=data_dir, **builder_kwargs)
File "/home/jplu/dev/jplu/datasets/src/nlp/load.py", line 170, in builder
builder_instance = builder_cls(**builder_kwargs)
File "/home/jplu/dev/jplu/datasets/src/nlp/datasets/84d638d2a8ca919d1021a554e741766f50679dc6553d5a0612b6094311babd39/bbc.py", line 12, in __init__
super(Bbc, self).__init__(**config)
TypeError: __init__() got an unexpected keyword argument 'force_reload'
```
So yes the cache is refreshed with the new script but then raises this error.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/613877975/reactions
| 2
| 1
| 0
| 0
| 0
| 0
| 1
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/613936607
|
https://github.com/huggingface/datasets/issues/2#issuecomment-613936607
|
https://api.github.com/repos/huggingface/datasets/issues/2
| 613,936,607
|
MDEyOklzc3VlQ29tbWVudDYxMzkzNjYwNw==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-04-15T09:46:10
| 2020-04-15T09:46:45
|
Ok great, so as discussed today, let's:
- have a main dataset directory inside the lib with sub-directories hashed by the content of the file
- keep a cache for downloading the scripts from S3 for now
- later: add methods to list and clean the local versions of the datasets (and the distant versions on S3 as well)
Side question: do you often use `builder_kwargs` for other things than supplying file paths? I was thinking about having a more easy to read and remember `data_files` argument maybe.
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/613936607/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/613941021
|
https://github.com/huggingface/datasets/issues/2#issuecomment-613941021
|
https://api.github.com/repos/huggingface/datasets/issues/2
| 613,941,021
|
MDEyOklzc3VlQ29tbWVudDYxMzk0MTAyMQ==
|
jplu
| 959,590
|
MDQ6VXNlcjk1OTU5MA==
|
https://avatars.githubusercontent.com/u/959590?v=4
|
https://api.github.com/users/jplu
|
https://github.com/jplu
|
https://api.github.com/users/jplu/followers
|
https://api.github.com/users/jplu/following{/other_user}
|
https://api.github.com/users/jplu/gists{/gist_id}
|
https://api.github.com/users/jplu/starred{/owner}{/repo}
|
https://api.github.com/users/jplu/subscriptions
|
https://api.github.com/users/jplu/orgs
|
https://api.github.com/users/jplu/repos
|
https://api.github.com/users/jplu/events{/privacy}
|
https://api.github.com/users/jplu/received_events
|
User
|
public
| false
| 2020-04-15T09:55:08
| 2020-04-15T09:55:08
|
Good plan!
Yes I do use `builder_kwargs` for other things such as:
- dataset name
- properties to know how to properly read a CSV file: do I have to skip the first line in a CSV, which delimiter is used, and the columns ids to use.
- properties to know how to properly read a JSON file: which properties in a JSON object to read
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/613941021/reactions
| 1
| 1
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/614052741
|
https://github.com/huggingface/datasets/issues/5#issuecomment-614052741
|
https://api.github.com/repos/huggingface/datasets/issues/5
| 614,052,741
|
MDEyOklzc3VlQ29tbWVudDYxNDA1Mjc0MQ==
|
jplu
| 959,590
|
MDQ6VXNlcjk1OTU5MA==
|
https://avatars.githubusercontent.com/u/959590?v=4
|
https://api.github.com/users/jplu
|
https://github.com/jplu
|
https://api.github.com/users/jplu/followers
|
https://api.github.com/users/jplu/following{/other_user}
|
https://api.github.com/users/jplu/gists{/gist_id}
|
https://api.github.com/users/jplu/starred{/owner}{/repo}
|
https://api.github.com/users/jplu/subscriptions
|
https://api.github.com/users/jplu/orgs
|
https://api.github.com/users/jplu/repos
|
https://api.github.com/users/jplu/events{/privacy}
|
https://api.github.com/users/jplu/received_events
|
User
|
public
| false
| 2020-04-15T13:50:30
| 2020-04-15T13:53:34
|
To fix this I propose to modify only the file `arrow_reader.py` with few updates. First update, the following method:
```python
def _make_file_instructions_from_absolutes(
name,
name2len,
absolute_instructions,
):
"""Returns the files instructions from the absolute instructions list."""
# For each split, return the files instruction (skip/take)
file_instructions = []
num_examples = 0
for abs_instr in absolute_instructions:
length = name2len[abs_instr.splitname]
if not length:
raise ValueError(
'Split empty. This might means that dataset hasn\'t been generated '
'yet and info not restored from GCS, or that legacy dataset is used.')
filename = filename_for_dataset_split(
dataset_name=name,
split=abs_instr.splitname,
filetype_suffix='arrow')
from_ = 0 if abs_instr.from_ is None else abs_instr.from_
to = length if abs_instr.to is None else abs_instr.to
num_examples += to - from_
single_file_instructions = [{"filename": filename, "skip": from_, "take": to - from_}]
file_instructions.extend(single_file_instructions)
return FileInstructions(
num_examples=num_examples,
file_instructions=file_instructions,
)
```
Becomes:
```python
def _make_file_instructions_from_absolutes(
name,
name2len,
absolute_instructions,
):
"""Returns the files instructions from the absolute instructions list."""
# For each split, return the files instruction (skip/take)
file_instructions = []
num_examples = 0
for abs_instr in absolute_instructions:
length = name2len[abs_instr.splitname]
## Delete the if not length and the raise
filename = filename_for_dataset_split(
dataset_name=name,
split=abs_instr.splitname,
filetype_suffix='arrow')
from_ = 0 if abs_instr.from_ is None else abs_instr.from_
to = length if abs_instr.to is None else abs_instr.to
num_examples += to - from_
single_file_instructions = [{"filename": filename, "skip": from_, "take": to - from_}]
file_instructions.extend(single_file_instructions)
return FileInstructions(
num_examples=num_examples,
file_instructions=file_instructions,
)
```
Second update the following method:
```python
def _read_files(files, info):
"""Returns Dataset for given file instructions.
Args:
files: List[dict(filename, skip, take)], the files information.
The filenames contain the absolute path, not relative.
skip/take indicates which example read in the file: `ds.slice(skip, take)`
"""
pa_batches = []
for f_dict in files:
pa_table: pa.Table = _get_dataset_from_filename(f_dict)
pa_batches.extend(pa_table.to_batches())
pa_table = pa.Table.from_batches(pa_batches)
ds = Dataset(arrow_table=pa_table, data_files=files, info=info)
return ds
```
Becomes:
```python
def _read_files(files, info):
"""Returns Dataset for given file instructions.
Args:
files: List[dict(filename, skip, take)], the files information.
The filenames contain the absolute path, not relative.
skip/take indicates which example read in the file: `ds.slice(skip, take)`
"""
pa_batches = []
for f_dict in files:
pa_table: pa.Table = _get_dataset_from_filename(f_dict)
pa_batches.extend(pa_table.to_batches())
## we modify the table only if there are some batches
if pa_batches:
pa_table = pa.Table.from_batches(pa_batches)
ds = Dataset(arrow_table=pa_table, data_files=files, info=info)
return ds
```
With these two updates it works now. @thomwolf are you ok with this changes?
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/614052741/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/614286440
|
https://github.com/huggingface/datasets/issues/5#issuecomment-614286440
|
https://api.github.com/repos/huggingface/datasets/issues/5
| 614,286,440
|
MDEyOklzc3VlQ29tbWVudDYxNDI4NjQ0MA==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-04-15T21:21:04
| 2020-04-15T21:21:11
|
Yes sounds good to me!
Do you want to make a PR? or I can do it as well
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/614286440/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/614287033
|
https://github.com/huggingface/datasets/issues/3#issuecomment-614287033
|
https://api.github.com/repos/huggingface/datasets/issues/3
| 614,287,033
|
MDEyOklzc3VlQ29tbWVudDYxNDI4NzAzMw==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-04-15T21:22:41
| 2020-04-15T21:22:41
|
Yes!
- pandas will be a one-liner in `arrow_dataset`: https://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table.to_pandas
- for Spark I have no idea. let's investigate that at some point
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/614287033/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/614288243
|
https://github.com/huggingface/datasets/issues/4#issuecomment-614288243
|
https://api.github.com/repos/huggingface/datasets/issues/4
| 614,288,243
|
MDEyOklzc3VlQ29tbWVudDYxNDI4ODI0Mw==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-04-15T21:25:47
| 2020-04-15T21:25:47
|
Yes! I see mostly two options for this:
- a `Feature` approach like currently (but we might deprecate features)
- wrapping in a smart way the Dictionary arrays of Arrow: https://arrow.apache.org/docs/python/data.html?highlight=dictionary%20encode#dictionary-arrays
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/614288243/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/614288880
|
https://github.com/huggingface/datasets/issues/6#issuecomment-614288880
|
https://api.github.com/repos/huggingface/datasets/issues/6
| 614,288,880
|
MDEyOklzc3VlQ29tbWVudDYxNDI4ODg4MA==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-04-15T21:27:11
| 2020-04-15T21:27:11
|
Yes looks good to me.
Note that we may refactor quite strongly the `info.py` to make it a lot simpler (it's very complicated for basically a dictionary of info I think)
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/614288880/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/614549885
|
https://github.com/huggingface/datasets/issues/4#issuecomment-614549885
|
https://api.github.com/repos/huggingface/datasets/issues/4
| 614,549,885
|
MDEyOklzc3VlQ29tbWVudDYxNDU0OTg4NQ==
|
jplu
| 959,590
|
MDQ6VXNlcjk1OTU5MA==
|
https://avatars.githubusercontent.com/u/959590?v=4
|
https://api.github.com/users/jplu
|
https://github.com/jplu
|
https://api.github.com/users/jplu/followers
|
https://api.github.com/users/jplu/following{/other_user}
|
https://api.github.com/users/jplu/gists{/gist_id}
|
https://api.github.com/users/jplu/starred{/owner}{/repo}
|
https://api.github.com/users/jplu/subscriptions
|
https://api.github.com/users/jplu/orgs
|
https://api.github.com/users/jplu/repos
|
https://api.github.com/users/jplu/events{/privacy}
|
https://api.github.com/users/jplu/received_events
|
User
|
public
| false
| 2020-04-16T10:05:51
| 2020-04-16T10:05:51
|
I would have a preference for the second bullet point.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/614549885/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/614550627
|
https://github.com/huggingface/datasets/issues/3#issuecomment-614550627
|
https://api.github.com/repos/huggingface/datasets/issues/3
| 614,550,627
|
MDEyOklzc3VlQ29tbWVudDYxNDU1MDYyNw==
|
jplu
| 959,590
|
MDQ6VXNlcjk1OTU5MA==
|
https://avatars.githubusercontent.com/u/959590?v=4
|
https://api.github.com/users/jplu
|
https://github.com/jplu
|
https://api.github.com/users/jplu/followers
|
https://api.github.com/users/jplu/following{/other_user}
|
https://api.github.com/users/jplu/gists{/gist_id}
|
https://api.github.com/users/jplu/starred{/owner}{/repo}
|
https://api.github.com/users/jplu/subscriptions
|
https://api.github.com/users/jplu/orgs
|
https://api.github.com/users/jplu/repos
|
https://api.github.com/users/jplu/events{/privacy}
|
https://api.github.com/users/jplu/received_events
|
User
|
public
| false
| 2020-04-16T10:07:22
| 2020-04-16T10:09:33
|
For Spark it looks to be pretty straightforward as well https://spark.apache.org/docs/latest/sql-pyspark-pandas-with-arrow.html but looks to be having a dependency to Spark is necessary, then nevermind we can skip it
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/614550627/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/615104204
|
https://github.com/huggingface/datasets/issues/6#issuecomment-615104204
|
https://api.github.com/repos/huggingface/datasets/issues/6
| 615,104,204
|
MDEyOklzc3VlQ29tbWVudDYxNTEwNDIwNA==
|
jplu
| 959,590
|
MDQ6VXNlcjk1OTU5MA==
|
https://avatars.githubusercontent.com/u/959590?v=4
|
https://api.github.com/users/jplu
|
https://github.com/jplu
|
https://api.github.com/users/jplu/followers
|
https://api.github.com/users/jplu/following{/other_user}
|
https://api.github.com/users/jplu/gists{/gist_id}
|
https://api.github.com/users/jplu/starred{/owner}{/repo}
|
https://api.github.com/users/jplu/subscriptions
|
https://api.github.com/users/jplu/orgs
|
https://api.github.com/users/jplu/repos
|
https://api.github.com/users/jplu/events{/privacy}
|
https://api.github.com/users/jplu/received_events
|
User
|
public
| false
| 2020-04-17T08:00:38
| 2020-04-17T08:00:38
|
No, problem ^^ It might just be a temporary fix :)
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/615104204/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/617406808
|
https://github.com/huggingface/datasets/pull/9#issuecomment-617406808
|
https://api.github.com/repos/huggingface/datasets/issues/9
| 617,406,808
|
MDEyOklzc3VlQ29tbWVudDYxNzQwNjgwOA==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-04-21T20:49:54
| 2020-04-21T20:49:54
|
Yes!
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/617406808/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/617629452
|
https://github.com/huggingface/datasets/pull/12#issuecomment-617629452
|
https://api.github.com/repos/huggingface/datasets/issues/12
| 617,629,452
|
MDEyOklzc3VlQ29tbWVudDYxNzYyOTQ1Mg==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-22T08:23:12
| 2020-04-22T08:23:12
|
Also added to an assert statement that if a dict is returned by function, all values of `dicts` are `lists`
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/617629452/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/617629597
|
https://github.com/huggingface/datasets/pull/12#issuecomment-617629597
|
https://api.github.com/repos/huggingface/datasets/issues/12
| 617,629,597
|
MDEyOklzc3VlQ29tbWVudDYxNzYyOTU5Nw==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-22T08:23:30
| 2020-04-22T08:23:30
|
Wait to merge until `make style` is set in place.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/617629597/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618235523
|
https://github.com/huggingface/datasets/pull/13#issuecomment-618235523
|
https://api.github.com/repos/huggingface/datasets/issues/13
| 618,235,523
|
MDEyOklzc3VlQ29tbWVudDYxODIzNTUyMw==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-23T07:38:53
| 2020-04-23T07:38:53
|
I think this can be quickly reproduced.
I use `black, version 19.10b0`.
When running:
`black nlp/src/arrow_reader.py`
it gives me:
```
error: cannot format /home/patrick/hugging_face/nlp/src/nlp/arrow_reader.py: cannot use --safe with this file; failed to parse source file. AST error message: invalid syntax (<unknown>, line 78)
Oh no! 💥 💔 💥
1 file failed to reformat.
```
The line in question is:
https://github.com/huggingface/nlp/blob/6922a16705e61f9e31a365f2606090b84d49241f/src/nlp/arrow_reader.py#L78
What is weird is that the trainer file in `transformers` has more or less the same syntax and black does not fail there:
https://github.com/huggingface/transformers/blob/cb3c2212c79d7ff0a4a4e84c3db48371ecc1c15d/src/transformers/trainer.py#L95
I googled quite a bit about black & typing hints yesterday and didn't find anything useful.
Any ideas @thomwolf @julien-c @LysandreJik ?
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618235523/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618239867
|
https://github.com/huggingface/datasets/pull/13#issuecomment-618239867
|
https://api.github.com/repos/huggingface/datasets/issues/13
| 618,239,867
|
MDEyOklzc3VlQ29tbWVudDYxODIzOTg2Nw==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-23T07:48:03
| 2020-04-23T07:48:03
|
> I think this can be quickly reproduced.
> I use `black, version 19.10b0`.
>
> When running:
> `black nlp/src/arrow_reader.py`
> it gives me:
>
> ```
> error: cannot format /home/patrick/hugging_face/nlp/src/nlp/arrow_reader.py: cannot use --safe with this file; failed to parse source file. AST error message: invalid syntax (<unknown>, line 78)
> Oh no! 💥 💔 💥
> 1 file failed to reformat.
> ```
>
> The line in question is:
> https://github.com/huggingface/nlp/blob/6922a16705e61f9e31a365f2606090b84d49241f/src/nlp/arrow_reader.py#L78
>
> What is weird is that the trainer file in `transformers` has more or less the same syntax and black does not fail there:
> https://github.com/huggingface/transformers/blob/cb3c2212c79d7ff0a4a4e84c3db48371ecc1c15d/src/transformers/trainer.py#L95
>
> I googled quite a bit about black & typing hints yesterday and didn't find anything useful.
> Any ideas @thomwolf @julien-c @LysandreJik ?
Ok I found the problem. It was the one Julien mentioned and has nothing to do with this line. Black's error message is a bit misleading here, I guess
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618239867/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618242956
|
https://github.com/huggingface/datasets/pull/13#issuecomment-618242956
|
https://api.github.com/repos/huggingface/datasets/issues/13
| 618,242,956
|
MDEyOklzc3VlQ29tbWVudDYxODI0Mjk1Ng==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-23T07:54:49
| 2020-04-23T07:54:49
|
Ok, just had to remove the python 2 syntax comments `# type`.
Good to merge for me now @thomwolf
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618242956/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618256874
|
https://github.com/huggingface/datasets/pull/12#issuecomment-618256874
|
https://api.github.com/repos/huggingface/datasets/issues/12
| 618,256,874
|
MDEyOklzc3VlQ29tbWVudDYxODI1Njg3NA==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-23T08:23:13
| 2020-04-23T08:23:13
|
Updated the assert statements. Played around with multiple cases and it should be good now IMO.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618256874/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618293120
|
https://github.com/huggingface/datasets/pull/15#issuecomment-618293120
|
https://api.github.com/repos/huggingface/datasets/issues/15
| 618,293,120
|
MDEyOklzc3VlQ29tbWVudDYxODI5MzEyMA==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-23T09:31:46
| 2020-04-23T09:31:46
|
> I think I'm fine with this.
>
> The alternative would be to host a small subset of the dataset on the S3 together with the testing script. But I think having all (test file creation + actual tests) in one file is actually quite convenient.
>
> Good for me!
>
> One question though, will we have to create one test file for each of the 100+ datasets or could we make some automatic conversion from tfds dataset test files?
I think if we go the way shown in the PR we would have to create one test file for each of the 100+ datasets.
As far as I know the tfds test files all rely on the user having created a special download folder structure in `tensorflow-datasets/tensorflow_datasets/testing/test_data/fake_examples`.
My hypothesis was:
Becasue, we don't want to work with PRs, no `dataset_script` is going to be in the official repo, so no `dataset_script_test` can be in the repo either. Therefore we can also not have any "fake" test folder structure in the repo.
**BUT:** As you mentioned @thom, we could have a fake data structure on AWS. To add a test the user has to upload multiple small test files when uploading his data set script.
So for a cli this could look like:
`python nlp-cli upload <data_set_script> --testfiles <relative path to test file 1> <relative path to test file 2> ...`
or even easier if the user just creates the dataset folder with the script inside and the testing folder structure, then the API could look like:
`python nlp-cli upload <path/to/dataset/folder>`
and the dataset folder would look like
```
squad
- squad.py
- fake_data # this dir would have to have the exact same structure we get when downloading from the official squad data url
```
This way I think we wouldn't even need any test files at all for each dataset script. For special datasets like `c4` or `wikipedia` we could then allow to optionally upload another test script.
We just assume that this is our downloaded `url` and check all functionality from there.
Thinking a bit more about this solution sounds a) much less work and b) even easier for the user.
A small problem I see here though:
1) What do we do when the depending on the config name the downloaded folder structure is very different? I think for each dataset config name we should have one test, which could correspond to one "fake" folder structure on AWS
@thomwolf What do you think? I would actually go for this solution instead now.
@mariamabarham You have written many more tfds dataset scripts and tests than I have - what do you think?
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618293120/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618297182
|
https://github.com/huggingface/datasets/pull/15#issuecomment-618297182
|
https://api.github.com/repos/huggingface/datasets/issues/15
| 618,297,182
|
MDEyOklzc3VlQ29tbWVudDYxODI5NzE4Mg==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-23T09:39:51
| 2020-04-23T09:39:51
|
Regarding the tfds tests, I don't really see a point in keeping them because:
1) If you provide a fake data structure, IMO there is no need for each dataset to have an individual test file because (I think) most datasets have the same functions `_split_generators` and `_generate_examples` for which you can just test the functionality in a common test file. For special functions like these beam / pipeline functionality you probably need an extra test file. But @mariamabarham I think you have seen more than I have here as well
2) The dataset test design is very much intertwined with the download manager design and contains a lot of code. I would like to seperate the tests into a) tests for downloading in general b) tests for post download data set pre-processing. Since we are going to change the download code anyways quite a lot, my plan was to focus on b) first.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618297182/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618315888
|
https://github.com/huggingface/datasets/pull/15#issuecomment-618315888
|
https://api.github.com/repos/huggingface/datasets/issues/15
| 618,315,888
|
MDEyOklzc3VlQ29tbWVudDYxODMxNTg4OA==
|
lhoestq
| 42,851,186
|
MDQ6VXNlcjQyODUxMTg2
|
https://avatars.githubusercontent.com/u/42851186?v=4
|
https://api.github.com/users/lhoestq
|
https://github.com/lhoestq
|
https://api.github.com/users/lhoestq/followers
|
https://api.github.com/users/lhoestq/following{/other_user}
|
https://api.github.com/users/lhoestq/gists{/gist_id}
|
https://api.github.com/users/lhoestq/starred{/owner}{/repo}
|
https://api.github.com/users/lhoestq/subscriptions
|
https://api.github.com/users/lhoestq/orgs
|
https://api.github.com/users/lhoestq/repos
|
https://api.github.com/users/lhoestq/events{/privacy}
|
https://api.github.com/users/lhoestq/received_events
|
User
|
public
| false
| 2020-04-23T10:17:17
| 2020-04-23T10:17:17
|
I like the idea of having a fake data folder on S3. I have seen datasets with nested compressed files structures that would be tedious to generate with code. And for users it is probably easier to create a fake data folder by taking a subset of the actual data, and then upload it as you said.
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618315888/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618393695
|
https://github.com/huggingface/datasets/pull/15#issuecomment-618393695
|
https://api.github.com/repos/huggingface/datasets/issues/15
| 618,393,695
|
MDEyOklzc3VlQ29tbWVudDYxODM5MzY5NQ==
|
mariamabarham
| 38,249,783
|
MDQ6VXNlcjM4MjQ5Nzgz
|
https://avatars.githubusercontent.com/u/38249783?v=4
|
https://api.github.com/users/mariamabarham
|
https://github.com/mariamabarham
|
https://api.github.com/users/mariamabarham/followers
|
https://api.github.com/users/mariamabarham/following{/other_user}
|
https://api.github.com/users/mariamabarham/gists{/gist_id}
|
https://api.github.com/users/mariamabarham/starred{/owner}{/repo}
|
https://api.github.com/users/mariamabarham/subscriptions
|
https://api.github.com/users/mariamabarham/orgs
|
https://api.github.com/users/mariamabarham/repos
|
https://api.github.com/users/mariamabarham/events{/privacy}
|
https://api.github.com/users/mariamabarham/received_events
|
User
|
public
| false
| 2020-04-23T13:09:26
| 2020-04-23T13:09:26
|
> > I think I'm fine with this.
> > The alternative would be to host a small subset of the dataset on the S3 together with the testing script. But I think having all (test file creation + actual tests) in one file is actually quite convenient.
> > Good for me!
> > One question though, will we have to create one test file for each of the 100+ datasets or could we make some automatic conversion from tfds dataset test files?
>
> I think if we go the way shown in the PR we would have to create one test file for each of the 100+ datasets.
>
> As far as I know the tfds test files all rely on the user having created a special download folder structure in `tensorflow-datasets/tensorflow_datasets/testing/test_data/fake_examples`.
>
> My hypothesis was:
> Becasue, we don't want to work with PRs, no `dataset_script` is going to be in the official repo, so no `dataset_script_test` can be in the repo either. Therefore we can also not have any "fake" test folder structure in the repo.
>
> **BUT:** As you mentioned @thom, we could have a fake data structure on AWS. To add a test the user has to upload multiple small test files when uploading his data set script.
>
> So for a cli this could look like:
> `python nlp-cli upload <data_set_script> --testfiles <relative path to test file 1> <relative path to test file 2> ...`
>
> or even easier if the user just creates the dataset folder with the script inside and the testing folder structure, then the API could look like:
>
> `python nlp-cli upload <path/to/dataset/folder>`
>
> and the dataset folder would look like
>
> ```
> squad
> - squad.py
> - fake_data # this dir would have to have the exact same structure we get when downloading from the official squad data url
> ```
>
> This way I think we wouldn't even need any test files at all for each dataset script. For special datasets like `c4` or `wikipedia` we could then allow to optionally upload another test script.
> We just assume that this is our downloaded `url` and check all functionality from there.
>
> Thinking a bit more about this solution sounds a) much less work and b) even easier for the user.
>
> A small problem I see here though:
>
> 1. What do we do when the depending on the config name the downloaded folder structure is very different? I think for each dataset config name we should have one test, which could correspond to one "fake" folder structure on AWS
>
> @thomwolf What do you think? I would actually go for this solution instead now.
> @mariamabarham You have written many more tfds dataset scripts and tests than I have - what do you think?
I'm agreed with you just one thing, for some dataset like glue or xtreme you may have multiple datasets in it. so I think a good way is to have one main fake folder and a subdirectory for each dataset inside
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618393695/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618396256
|
https://github.com/huggingface/datasets/pull/15#issuecomment-618396256
|
https://api.github.com/repos/huggingface/datasets/issues/15
| 618,396,256
|
MDEyOklzc3VlQ29tbWVudDYxODM5NjI1Ng==
|
mariamabarham
| 38,249,783
|
MDQ6VXNlcjM4MjQ5Nzgz
|
https://avatars.githubusercontent.com/u/38249783?v=4
|
https://api.github.com/users/mariamabarham
|
https://github.com/mariamabarham
|
https://api.github.com/users/mariamabarham/followers
|
https://api.github.com/users/mariamabarham/following{/other_user}
|
https://api.github.com/users/mariamabarham/gists{/gist_id}
|
https://api.github.com/users/mariamabarham/starred{/owner}{/repo}
|
https://api.github.com/users/mariamabarham/subscriptions
|
https://api.github.com/users/mariamabarham/orgs
|
https://api.github.com/users/mariamabarham/repos
|
https://api.github.com/users/mariamabarham/events{/privacy}
|
https://api.github.com/users/mariamabarham/received_events
|
User
|
public
| false
| 2020-04-23T13:20:55
| 2020-04-23T13:20:55
|
> Regarding the tfds tests, I don't really see a point in keeping them because:
>
> 1. If you provide a fake data structure, IMO there is no need for each dataset to have an individual test file because (I think) most datasets have the same functions `_split_generators` and `_generate_examples` for which you can just test the functionality in a common test file. For special functions like these beam / pipeline functionality you probably need an extra test file. But @mariamabarham I think you have seen more than I have here as well
> 2. The dataset test design is very much intertwined with the download manager design and contains a lot of code. I would like to seperate the tests into a) tests for downloading in general b) tests for post download data set pre-processing. Since we are going to change the download code anyways quite a lot, my plan was to focus on b) first.
For _split_generator, yes. But I'm not sure for _generate_examples because there is lots of things that should be taken into account such as feature names and types, data format (json, jsonl, csv, tsv,..)
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618396256/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618694816
|
https://github.com/huggingface/datasets/pull/15#issuecomment-618694816
|
https://api.github.com/repos/huggingface/datasets/issues/15
| 618,694,816
|
MDEyOklzc3VlQ29tbWVudDYxODY5NDgxNg==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-04-23T22:02:32
| 2020-04-23T22:03:03
|
Sounds good to me!
When testing, we could thus just override the prefix in the URL inside the download manager to have them point to the test directory on our S3.
Cc @lhoestq
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/618694816/reactions
| 1
| 1
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619001228
|
https://github.com/huggingface/datasets/pull/15#issuecomment-619001228
|
https://api.github.com/repos/huggingface/datasets/issues/15
| 619,001,228
|
MDEyOklzc3VlQ29tbWVudDYxOTAwMTIyOA==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-24T13:14:39
| 2020-04-24T13:19:05
|
Ok, here is a second draft for the testing structure.
I think the big difficulty here is "How can you generate tests on the fly from a given dataset name, *e.g.* `squad`"?
So, this morning I did some research on "parameterized testing" and pure `unittest` or `pytest` didn't work very well.
I found the lib https://github.com/wolever/parameterized, which works very nicely for our use case I think.
@thomwolf - would it be ok to have a dependence on this lib for `nlp`? It seems like a light-weight lib to me.
This lib allows to add a `parameterization` decorator to a `unittest.TestCase` class so that the class can be instantiated for multiple different arguments (which are the dataset names `squad` etc. in our case).
What I like about this lib is that one only has to add the decorator and the each of the parameterized tests are shown, like this:
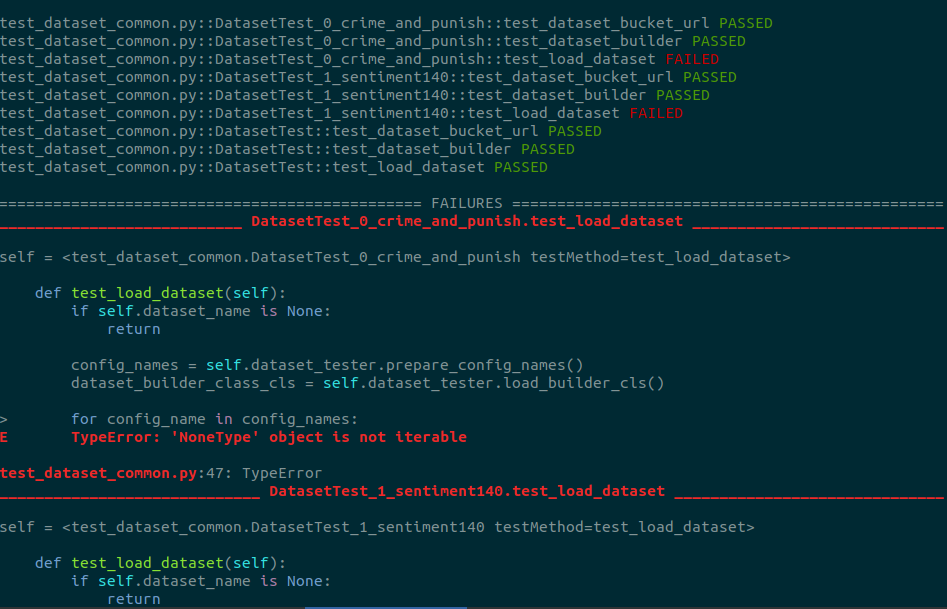
With this structure we would only have to upload the dummy data for each dataset and would not require a specific testing file.
What do you think @thomwolf @mariamabarham @lhoestq ?
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619001228/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619007632
|
https://github.com/huggingface/datasets/pull/16#issuecomment-619007632
|
https://api.github.com/repos/huggingface/datasets/issues/16
| 619,007,632
|
MDEyOklzc3VlQ29tbWVudDYxOTAwNzYzMg==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-24T13:24:48
| 2020-04-24T13:24:48
|
Looks great to me!
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619007632/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619090994
|
https://github.com/huggingface/datasets/pull/16#issuecomment-619090994
|
https://api.github.com/repos/huggingface/datasets/issues/16
| 619,090,994
|
MDEyOklzc3VlQ29tbWVudDYxOTA5MDk5NA==
|
lhoestq
| 42,851,186
|
MDQ6VXNlcjQyODUxMTg2
|
https://avatars.githubusercontent.com/u/42851186?v=4
|
https://api.github.com/users/lhoestq
|
https://github.com/lhoestq
|
https://api.github.com/users/lhoestq/followers
|
https://api.github.com/users/lhoestq/following{/other_user}
|
https://api.github.com/users/lhoestq/gists{/gist_id}
|
https://api.github.com/users/lhoestq/starred{/owner}{/repo}
|
https://api.github.com/users/lhoestq/subscriptions
|
https://api.github.com/users/lhoestq/orgs
|
https://api.github.com/users/lhoestq/repos
|
https://api.github.com/users/lhoestq/events{/privacy}
|
https://api.github.com/users/lhoestq/received_events
|
User
|
public
| false
| 2020-04-24T15:46:02
| 2020-04-24T15:46:02
|
The new download manager is ready. I removed the old folder and I fixed a few remaining dependencies.
I tested it on squad and a few others from the dataset folder and it works fine.
The only impact of these changes is that it breaks the `download_and_prepare` script that was used to register the checksums when we create a dataset, as the checksum logic is not implemented.
Let me know if you have remarks
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619090994/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619341947
|
https://github.com/huggingface/datasets/pull/15#issuecomment-619341947
|
https://api.github.com/repos/huggingface/datasets/issues/15
| 619,341,947
|
MDEyOklzc3VlQ29tbWVudDYxOTM0MTk0Nw==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-04-25T08:24:44
| 2020-04-25T08:24:44
|
I think this is a nice solution.
Do you think we could have the `parametrized` dependency in a `[test]` optional installation of `setup.py`? I would really like to keep the dependencies of the standard installation as small as possible.
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619341947/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619442038
|
https://github.com/huggingface/datasets/pull/19#issuecomment-619442038
|
https://api.github.com/repos/huggingface/datasets/issues/19
| 619,442,038
|
MDEyOklzc3VlQ29tbWVudDYxOTQ0MjAzOA==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-04-25T21:18:40
| 2020-04-25T21:18:40
|
Awesome!
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619442038/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619442873
|
https://github.com/huggingface/datasets/pull/16#issuecomment-619442873
|
https://api.github.com/repos/huggingface/datasets/issues/16
| 619,442,873
|
MDEyOklzc3VlQ29tbWVudDYxOTQ0Mjg3Mw==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-04-25T21:26:20
| 2020-04-25T21:26:20
|
Ok merged it (a bit fast for you to update the copyright, now I see that. but it's ok, we'll do a pass on these doc/copyright before releasing anyway)
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619442873/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619505084
|
https://github.com/huggingface/datasets/pull/16#issuecomment-619505084
|
https://api.github.com/repos/huggingface/datasets/issues/16
| 619,505,084
|
MDEyOklzc3VlQ29tbWVudDYxOTUwNTA4NA==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-04-26T07:59:43
| 2020-04-26T07:59:43
|
Actually two additional things here @lhoestq (I merged too fast sorry, let's make a new PR for additional developments):
- I think we can remove some dependencies now (e.g. `promises`) in setup.py, can you have a look?
- also, I think we can remove the boto3 dependency like here: https://github.com/huggingface/transformers/pull/3968
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619505084/reactions
| 1
| 1
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619773867
|
https://github.com/huggingface/datasets/pull/15#issuecomment-619773867
|
https://api.github.com/repos/huggingface/datasets/issues/15
| 619,773,867
|
MDEyOklzc3VlQ29tbWVudDYxOTc3Mzg2Nw==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-27T07:02:20
| 2020-04-27T07:02:20
|
> I think this is a nice solution.
>
> Do you think we could have the `parametrized` dependency in a `[test]` optional installation of `setup.py`? I would really like to keep the dependencies of the standard installation as small as possible.
Yes definitely!
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/619773867/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/620015689
|
https://github.com/huggingface/datasets/pull/15#issuecomment-620015689
|
https://api.github.com/repos/huggingface/datasets/issues/15
| 620,015,689
|
MDEyOklzc3VlQ29tbWVudDYyMDAxNTY4OQ==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-27T14:16:13
| 2020-04-27T14:16:13
|
UPDATE:
This test design is ready now. I added dummy data to S3 for the dataests: `squad, crime_and_punish, sentiment140` . The structure can be seen on `https://s3.console.aws.amazon.com/s3/buckets/datasets.huggingface.co/nlp/squad/dummy/?region=us-east-1&tab=overview` for `squad`.
All dummy data files have to be in .zip format and called `dummy_data.zip`. The zip file should thereby have the exact same folder structure one gets from downloading the "real" data url(s).
To show how the .zip file looks like for the added datasets, I added the folder `nlp/datasets/dummy_data` in this PR. I think we can leave for the moment so that people can see better how to add dummy data tests and later delete it like `nlp/datasets/nlp`.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/620015689/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/620246234
|
https://github.com/huggingface/datasets/pull/18#issuecomment-620246234
|
https://api.github.com/repos/huggingface/datasets/issues/18
| 620,246,234
|
MDEyOklzc3VlQ29tbWVudDYyMDI0NjIzNA==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-27T21:30:45
| 2020-04-27T21:30:45
|
LGTM
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/620246234/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621088256
|
https://github.com/huggingface/datasets/issues/5#issuecomment-621088256
|
https://api.github.com/repos/huggingface/datasets/issues/5
| 621,088,256
|
MDEyOklzc3VlQ29tbWVudDYyMTA4ODI1Ng==
|
jplu
| 959,590
|
MDQ6VXNlcjk1OTU5MA==
|
https://avatars.githubusercontent.com/u/959590?v=4
|
https://api.github.com/users/jplu
|
https://github.com/jplu
|
https://api.github.com/users/jplu/followers
|
https://api.github.com/users/jplu/following{/other_user}
|
https://api.github.com/users/jplu/gists{/gist_id}
|
https://api.github.com/users/jplu/starred{/owner}{/repo}
|
https://api.github.com/users/jplu/subscriptions
|
https://api.github.com/users/jplu/orgs
|
https://api.github.com/users/jplu/repos
|
https://api.github.com/users/jplu/events{/privacy}
|
https://api.github.com/users/jplu/received_events
|
User
|
public
| false
| 2020-04-29T09:23:05
| 2020-04-29T09:23:05
|
Fixed.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621088256/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621088291
|
https://github.com/huggingface/datasets/pull/21#issuecomment-621088291
|
https://api.github.com/repos/huggingface/datasets/issues/21
| 621,088,291
|
MDEyOklzc3VlQ29tbWVudDYyMTA4ODI5MQ==
|
lhoestq
| 42,851,186
|
MDQ6VXNlcjQyODUxMTg2
|
https://avatars.githubusercontent.com/u/42851186?v=4
|
https://api.github.com/users/lhoestq
|
https://github.com/lhoestq
|
https://api.github.com/users/lhoestq/followers
|
https://api.github.com/users/lhoestq/following{/other_user}
|
https://api.github.com/users/lhoestq/gists{/gist_id}
|
https://api.github.com/users/lhoestq/starred{/owner}{/repo}
|
https://api.github.com/users/lhoestq/subscriptions
|
https://api.github.com/users/lhoestq/orgs
|
https://api.github.com/users/lhoestq/repos
|
https://api.github.com/users/lhoestq/events{/privacy}
|
https://api.github.com/users/lhoestq/received_events
|
User
|
public
| false
| 2020-04-29T09:23:10
| 2020-04-29T09:23:10
|
For conflicts, I think the mention hint "This should be modified because it mentions ..." is missing.
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621088291/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621088369
|
https://github.com/huggingface/datasets/issues/6#issuecomment-621088369
|
https://api.github.com/repos/huggingface/datasets/issues/6
| 621,088,369
|
MDEyOklzc3VlQ29tbWVudDYyMTA4ODM2OQ==
|
jplu
| 959,590
|
MDQ6VXNlcjk1OTU5MA==
|
https://avatars.githubusercontent.com/u/959590?v=4
|
https://api.github.com/users/jplu
|
https://github.com/jplu
|
https://api.github.com/users/jplu/followers
|
https://api.github.com/users/jplu/following{/other_user}
|
https://api.github.com/users/jplu/gists{/gist_id}
|
https://api.github.com/users/jplu/starred{/owner}{/repo}
|
https://api.github.com/users/jplu/subscriptions
|
https://api.github.com/users/jplu/orgs
|
https://api.github.com/users/jplu/repos
|
https://api.github.com/users/jplu/events{/privacy}
|
https://api.github.com/users/jplu/received_events
|
User
|
public
| false
| 2020-04-29T09:23:21
| 2020-04-29T09:23:21
|
Fixed.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621088369/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621645766
|
https://github.com/huggingface/datasets/pull/21#issuecomment-621645766
|
https://api.github.com/repos/huggingface/datasets/issues/21
| 621,645,766
|
MDEyOklzc3VlQ29tbWVudDYyMTY0NTc2Ng==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-30T06:46:15
| 2020-04-30T06:46:15
|
Looks great!
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621645766/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621656344
|
https://github.com/huggingface/datasets/pull/24#issuecomment-621656344
|
https://api.github.com/repos/huggingface/datasets/issues/24
| 621,656,344
|
MDEyOklzc3VlQ29tbWVudDYyMTY1NjM0NA==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-30T07:12:32
| 2020-04-30T07:12:32
|
Looks good to me :-)
Just would prefer to get rid of the `_DYNAMICALLY_IMPORTED_MODULE` attribute and replace it by a `get_imported_module()` function. Maybe there is something I'm not seeing here though - what do you think?
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621656344/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621704068
|
https://github.com/huggingface/datasets/pull/24#issuecomment-621704068
|
https://api.github.com/repos/huggingface/datasets/issues/24
| 621,704,068
|
MDEyOklzc3VlQ29tbWVudDYyMTcwNDA2OA==
|
lhoestq
| 42,851,186
|
MDQ6VXNlcjQyODUxMTg2
|
https://avatars.githubusercontent.com/u/42851186?v=4
|
https://api.github.com/users/lhoestq
|
https://github.com/lhoestq
|
https://api.github.com/users/lhoestq/followers
|
https://api.github.com/users/lhoestq/following{/other_user}
|
https://api.github.com/users/lhoestq/gists{/gist_id}
|
https://api.github.com/users/lhoestq/starred{/owner}{/repo}
|
https://api.github.com/users/lhoestq/subscriptions
|
https://api.github.com/users/lhoestq/orgs
|
https://api.github.com/users/lhoestq/repos
|
https://api.github.com/users/lhoestq/events{/privacy}
|
https://api.github.com/users/lhoestq/received_events
|
User
|
public
| false
| 2020-04-30T08:53:26
| 2020-04-30T11:48:50
|
> * I'm not sure I understand the general organization of checksums. I see we have a checksum folder with potentially several checksum files but I also see that checksum files can potentially contain several checksums. Could you explain a bit more how this is organized?
It should look like this:
squad/
├── squad.py/
└── urls_checksums/
...........└── checksums.txt
In checksums.txt, the format is one line per (url, size, checksum)
I don't have a strong opinion between `urls_checksums/checksums.txt` or directly `checksums.txt` (not inside the `urls_checksums` folder), let me know what you think.
> * Also regarding your comment on checksum files for "canonical" datasets. I understand we can just create these with `nlp-cli test` and then upload them manually to our S3, right?
Yes you're right
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621704068/reactions
| 1
| 1
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621807985
|
https://github.com/huggingface/datasets/pull/24#issuecomment-621807985
|
https://api.github.com/repos/huggingface/datasets/issues/24
| 621,807,985
|
MDEyOklzc3VlQ29tbWVudDYyMTgwNzk4NQ==
|
lhoestq
| 42,851,186
|
MDQ6VXNlcjQyODUxMTg2
|
https://avatars.githubusercontent.com/u/42851186?v=4
|
https://api.github.com/users/lhoestq
|
https://github.com/lhoestq
|
https://api.github.com/users/lhoestq/followers
|
https://api.github.com/users/lhoestq/following{/other_user}
|
https://api.github.com/users/lhoestq/gists{/gist_id}
|
https://api.github.com/users/lhoestq/starred{/owner}{/repo}
|
https://api.github.com/users/lhoestq/subscriptions
|
https://api.github.com/users/lhoestq/orgs
|
https://api.github.com/users/lhoestq/repos
|
https://api.github.com/users/lhoestq/events{/privacy}
|
https://api.github.com/users/lhoestq/received_events
|
User
|
public
| false
| 2020-04-30T12:39:43
| 2020-04-30T12:39:43
|
Update of the commands:
- nlp-cli test \<dataset\> : Run download_and_prepare and verify checksums
* --name \<name\> : run only for the name
* --all_configs : run for all configs
* --save_checksums : instead of verifying checksums, compute and save them
* --ignore_checksums : don't do checksums verification
- nlp-cli upload \<dataset_folder\> : Upload a dataset
* --upload_checksums : compute and upload checksums for uploaded files
TODO:
- don't overwrite checksums files on S3, to let the user upload a dataset in several steps if needed
Question:
- One idea from @patrickvonplaten : shall we upload checksums everytime we upload files ? (and therefore remove the upload_checksums parameter)
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621807985/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621962403
|
https://github.com/huggingface/datasets/pull/25#issuecomment-621962403
|
https://api.github.com/repos/huggingface/datasets/issues/25
| 621,962,403
|
MDEyOklzc3VlQ29tbWVudDYyMTk2MjQwMw==
|
jplu
| 959,590
|
MDQ6VXNlcjk1OTU5MA==
|
https://avatars.githubusercontent.com/u/959590?v=4
|
https://api.github.com/users/jplu
|
https://github.com/jplu
|
https://api.github.com/users/jplu/followers
|
https://api.github.com/users/jplu/following{/other_user}
|
https://api.github.com/users/jplu/gists{/gist_id}
|
https://api.github.com/users/jplu/starred{/owner}{/repo}
|
https://api.github.com/users/jplu/subscriptions
|
https://api.github.com/users/jplu/orgs
|
https://api.github.com/users/jplu/repos
|
https://api.github.com/users/jplu/events{/privacy}
|
https://api.github.com/users/jplu/received_events
|
User
|
public
| false
| 2020-04-30T16:29:39
| 2020-04-30T16:29:39
|
Very interesting thoughts, we should think deeper about all what you raised indeed.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/621962403/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/622052653
|
https://github.com/huggingface/datasets/pull/24#issuecomment-622052653
|
https://api.github.com/repos/huggingface/datasets/issues/24
| 622,052,653
|
MDEyOklzc3VlQ29tbWVudDYyMjA1MjY1Mw==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-04-30T19:19:15
| 2020-04-30T19:19:15
|
Ok, ready to merge, then @lhoestq ?
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/622052653/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/622069889
|
https://github.com/huggingface/datasets/pull/24#issuecomment-622069889
|
https://api.github.com/repos/huggingface/datasets/issues/24
| 622,069,889
|
MDEyOklzc3VlQ29tbWVudDYyMjA2OTg4OQ==
|
lhoestq
| 42,851,186
|
MDQ6VXNlcjQyODUxMTg2
|
https://avatars.githubusercontent.com/u/42851186?v=4
|
https://api.github.com/users/lhoestq
|
https://github.com/lhoestq
|
https://api.github.com/users/lhoestq/followers
|
https://api.github.com/users/lhoestq/following{/other_user}
|
https://api.github.com/users/lhoestq/gists{/gist_id}
|
https://api.github.com/users/lhoestq/starred{/owner}{/repo}
|
https://api.github.com/users/lhoestq/subscriptions
|
https://api.github.com/users/lhoestq/orgs
|
https://api.github.com/users/lhoestq/repos
|
https://api.github.com/users/lhoestq/events{/privacy}
|
https://api.github.com/users/lhoestq/received_events
|
User
|
public
| false
| 2020-04-30T19:49:31
| 2020-04-30T19:49:31
|
Yep :)
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/622069889/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/622071027
|
https://github.com/huggingface/datasets/pull/29#issuecomment-622071027
|
https://api.github.com/repos/huggingface/datasets/issues/29
| 622,071,027
|
MDEyOklzc3VlQ29tbWVudDYyMjA3MTAyNw==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-04-30T19:51:38
| 2020-04-30T19:51:38
|
Ok merging! I think it's good now
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/622071027/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623090267
|
https://github.com/huggingface/datasets/pull/33#issuecomment-623090267
|
https://api.github.com/repos/huggingface/datasets/issues/33
| 623,090,267
|
MDEyOklzc3VlQ29tbWVudDYyMzA5MDI2Nw==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-03T10:46:30
| 2020-05-03T10:46:30
|
Great! I think when this merged, we can merge sure that Circle Ci stays happy when uploading new datasets.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623090267/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623112863
|
https://github.com/huggingface/datasets/issues/4#issuecomment-623112863
|
https://api.github.com/repos/huggingface/datasets/issues/4
| 623,112,863
|
MDEyOklzc3VlQ29tbWVudDYyMzExMjg2Mw==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-05-03T13:47:43
| 2020-05-03T13:47:43
|
This should be accessible now as a feature in dataset.info.features (and even have the mapping methods).
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623112863/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623276549
|
https://github.com/huggingface/datasets/issues/4#issuecomment-623276549
|
https://api.github.com/repos/huggingface/datasets/issues/4
| 623,276,549
|
MDEyOklzc3VlQ29tbWVudDYyMzI3NjU0OQ==
|
jplu
| 959,590
|
MDQ6VXNlcjk1OTU5MA==
|
https://avatars.githubusercontent.com/u/959590?v=4
|
https://api.github.com/users/jplu
|
https://github.com/jplu
|
https://api.github.com/users/jplu/followers
|
https://api.github.com/users/jplu/following{/other_user}
|
https://api.github.com/users/jplu/gists{/gist_id}
|
https://api.github.com/users/jplu/starred{/owner}{/repo}
|
https://api.github.com/users/jplu/subscriptions
|
https://api.github.com/users/jplu/orgs
|
https://api.github.com/users/jplu/repos
|
https://api.github.com/users/jplu/events{/privacy}
|
https://api.github.com/users/jplu/received_events
|
User
|
public
| false
| 2020-05-04T06:11:57
| 2020-05-04T06:11:57
|
Perfect! Well done!!
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623276549/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623276695
|
https://github.com/huggingface/datasets/issues/3#issuecomment-623276695
|
https://api.github.com/repos/huggingface/datasets/issues/3
| 623,276,695
|
MDEyOklzc3VlQ29tbWVudDYyMzI3NjY5NQ==
|
jplu
| 959,590
|
MDQ6VXNlcjk1OTU5MA==
|
https://avatars.githubusercontent.com/u/959590?v=4
|
https://api.github.com/users/jplu
|
https://github.com/jplu
|
https://api.github.com/users/jplu/followers
|
https://api.github.com/users/jplu/following{/other_user}
|
https://api.github.com/users/jplu/gists{/gist_id}
|
https://api.github.com/users/jplu/starred{/owner}{/repo}
|
https://api.github.com/users/jplu/subscriptions
|
https://api.github.com/users/jplu/orgs
|
https://api.github.com/users/jplu/repos
|
https://api.github.com/users/jplu/events{/privacy}
|
https://api.github.com/users/jplu/received_events
|
User
|
public
| false
| 2020-05-04T06:12:27
| 2020-05-04T06:12:27
|
Now Pandas is available.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623276695/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623317405
|
https://github.com/huggingface/datasets/issues/38#issuecomment-623317405
|
https://api.github.com/repos/huggingface/datasets/issues/38
| 623,317,405
|
MDEyOklzc3VlQ29tbWVudDYyMzMxNzQwNQ==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-04T08:00:37
| 2020-05-04T08:00:37
|
@lhoestq - could you take a look? It's not very urgent though!
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623317405/reactions
| 1
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 1
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623327458
|
https://github.com/huggingface/datasets/issues/38#issuecomment-623327458
|
https://api.github.com/repos/huggingface/datasets/issues/38
| 623,327,458
|
MDEyOklzc3VlQ29tbWVudDYyMzMyNzQ1OA==
|
lhoestq
| 42,851,186
|
MDQ6VXNlcjQyODUxMTg2
|
https://avatars.githubusercontent.com/u/42851186?v=4
|
https://api.github.com/users/lhoestq
|
https://github.com/lhoestq
|
https://api.github.com/users/lhoestq/followers
|
https://api.github.com/users/lhoestq/following{/other_user}
|
https://api.github.com/users/lhoestq/gists{/gist_id}
|
https://api.github.com/users/lhoestq/starred{/owner}{/repo}
|
https://api.github.com/users/lhoestq/subscriptions
|
https://api.github.com/users/lhoestq/orgs
|
https://api.github.com/users/lhoestq/repos
|
https://api.github.com/users/lhoestq/events{/privacy}
|
https://api.github.com/users/lhoestq/received_events
|
User
|
public
| false
| 2020-05-04T08:23:55
| 2020-05-04T08:23:55
|
Fixed with 06882b4
Now your command works :)
Note that you can also do
```
nlp-cli test datasets/nlp/xnli --save_checksums
```
So that it will save the checksums directly in the right directory.
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623327458/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623337880
|
https://github.com/huggingface/datasets/pull/37#issuecomment-623337880
|
https://api.github.com/repos/huggingface/datasets/issues/37
| 623,337,880
|
MDEyOklzc3VlQ29tbWVudDYyMzMzNzg4MA==
|
lhoestq
| 42,851,186
|
MDQ6VXNlcjQyODUxMTg2
|
https://avatars.githubusercontent.com/u/42851186?v=4
|
https://api.github.com/users/lhoestq
|
https://github.com/lhoestq
|
https://api.github.com/users/lhoestq/followers
|
https://api.github.com/users/lhoestq/following{/other_user}
|
https://api.github.com/users/lhoestq/gists{/gist_id}
|
https://api.github.com/users/lhoestq/starred{/owner}{/repo}
|
https://api.github.com/users/lhoestq/subscriptions
|
https://api.github.com/users/lhoestq/orgs
|
https://api.github.com/users/lhoestq/repos
|
https://api.github.com/users/lhoestq/events{/privacy}
|
https://api.github.com/users/lhoestq/received_events
|
User
|
public
| false
| 2020-05-04T08:47:09
| 2020-05-04T08:47:09
|
Note:
```
nlp-cli test datasets/nlp/<your-dataset-folder> --save_checksums --all_configs
```
directly saves the checksums in the right place, and runs for all the dataset configurations.
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623337880/reactions
| 1
| 1
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623352235
|
https://github.com/huggingface/datasets/pull/37#issuecomment-623352235
|
https://api.github.com/repos/huggingface/datasets/issues/37
| 623,352,235
|
MDEyOklzc3VlQ29tbWVudDYyMzM1MjIzNQ==
|
mariamabarham
| 38,249,783
|
MDQ6VXNlcjM4MjQ5Nzgz
|
https://avatars.githubusercontent.com/u/38249783?v=4
|
https://api.github.com/users/mariamabarham
|
https://github.com/mariamabarham
|
https://api.github.com/users/mariamabarham/followers
|
https://api.github.com/users/mariamabarham/following{/other_user}
|
https://api.github.com/users/mariamabarham/gists{/gist_id}
|
https://api.github.com/users/mariamabarham/starred{/owner}{/repo}
|
https://api.github.com/users/mariamabarham/subscriptions
|
https://api.github.com/users/mariamabarham/orgs
|
https://api.github.com/users/mariamabarham/repos
|
https://api.github.com/users/mariamabarham/events{/privacy}
|
https://api.github.com/users/mariamabarham/received_events
|
User
|
public
| false
| 2020-05-04T09:16:49
| 2020-05-04T09:16:49
|
@patrickvonplaten can you provide the add the link to the PR for the dummy data?
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623352235/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623353725
|
https://github.com/huggingface/datasets/pull/37#issuecomment-623353725
|
https://api.github.com/repos/huggingface/datasets/issues/37
| 623,353,725
|
MDEyOklzc3VlQ29tbWVudDYyMzM1MzcyNQ==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-04T09:20:04
| 2020-05-04T09:20:04
|
https://github.com/huggingface/nlp/pull/15 - But it's probably best to checkout into this branch and look how the dummy data strtucture is for `squad` for example.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623353725/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623366659
|
https://github.com/huggingface/datasets/issues/38#issuecomment-623366659
|
https://api.github.com/repos/huggingface/datasets/issues/38
| 623,366,659
|
MDEyOklzc3VlQ29tbWVudDYyMzM2NjY1OQ==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-04T09:48:20
| 2020-05-04T09:48:20
|
Awesome!
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623366659/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623452924
|
https://github.com/huggingface/datasets/pull/43#issuecomment-623452924
|
https://api.github.com/repos/huggingface/datasets/issues/43
| 623,452,924
|
MDEyOklzc3VlQ29tbWVudDYyMzQ1MjkyNA==
|
lhoestq
| 42,851,186
|
MDQ6VXNlcjQyODUxMTg2
|
https://avatars.githubusercontent.com/u/42851186?v=4
|
https://api.github.com/users/lhoestq
|
https://github.com/lhoestq
|
https://api.github.com/users/lhoestq/followers
|
https://api.github.com/users/lhoestq/following{/other_user}
|
https://api.github.com/users/lhoestq/gists{/gist_id}
|
https://api.github.com/users/lhoestq/starred{/owner}{/repo}
|
https://api.github.com/users/lhoestq/subscriptions
|
https://api.github.com/users/lhoestq/orgs
|
https://api.github.com/users/lhoestq/repos
|
https://api.github.com/users/lhoestq/events{/privacy}
|
https://api.github.com/users/lhoestq/received_events
|
User
|
public
| false
| 2020-05-04T13:08:07
| 2020-05-04T13:08:07
|
Whoops I fixed it directly on master before checking that you have done it in this PR. We may close it
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623452924/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623456579
|
https://github.com/huggingface/datasets/pull/43#issuecomment-623456579
|
https://api.github.com/repos/huggingface/datasets/issues/43
| 623,456,579
|
MDEyOklzc3VlQ29tbWVudDYyMzQ1NjU3OQ==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-04T13:14:53
| 2020-05-04T13:14:53
|
Yeah, I saw :-) But I think we should add this as well since some datasets have an empty list of configs and then as the code is now it would fail.
In this PR, I just make sure that the code jumps in the correct else if "there are no configs" as is the case for some datasets @mariamabarham
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623456579/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623458287
|
https://github.com/huggingface/datasets/pull/43#issuecomment-623458287
|
https://api.github.com/repos/huggingface/datasets/issues/43
| 623,458,287
|
MDEyOklzc3VlQ29tbWVudDYyMzQ1ODI4Nw==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-04T13:18:03
| 2020-05-04T13:18:03
|
Sorry, I thought you meant a different commit . Just saw this one: https://github.com/huggingface/nlp/commit/7c644f284e2303b57612a6e7c904fe13906d893f
.
All good then :-)
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623458287/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623463019
|
https://github.com/huggingface/datasets/pull/37#issuecomment-623463019
|
https://api.github.com/repos/huggingface/datasets/issues/37
| 623,463,019
|
MDEyOklzc3VlQ29tbWVudDYyMzQ2MzAxOQ==
|
lhoestq
| 42,851,186
|
MDQ6VXNlcjQyODUxMTg2
|
https://avatars.githubusercontent.com/u/42851186?v=4
|
https://api.github.com/users/lhoestq
|
https://github.com/lhoestq
|
https://api.github.com/users/lhoestq/followers
|
https://api.github.com/users/lhoestq/following{/other_user}
|
https://api.github.com/users/lhoestq/gists{/gist_id}
|
https://api.github.com/users/lhoestq/starred{/owner}{/repo}
|
https://api.github.com/users/lhoestq/subscriptions
|
https://api.github.com/users/lhoestq/orgs
|
https://api.github.com/users/lhoestq/repos
|
https://api.github.com/users/lhoestq/events{/privacy}
|
https://api.github.com/users/lhoestq/received_events
|
User
|
public
| false
| 2020-05-04T13:26:59
| 2020-05-04T13:26:59
|
are lock files supposed to stay ?
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623463019/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623465237
|
https://github.com/huggingface/datasets/pull/37#issuecomment-623465237
|
https://api.github.com/repos/huggingface/datasets/issues/37
| 623,465,237
|
MDEyOklzc3VlQ29tbWVudDYyMzQ2NTIzNw==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-04T13:31:06
| 2020-05-04T13:31:06
|
> are lock files supposed to stay ?
Not sure! I think the checksum command creates them, so I just uploaded them as well.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623465237/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623662192
|
https://github.com/huggingface/datasets/pull/37#issuecomment-623662192
|
https://api.github.com/repos/huggingface/datasets/issues/37
| 623,662,192
|
MDEyOklzc3VlQ29tbWVudDYyMzY2MjE5Mg==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-05-04T19:35:15
| 2020-05-04T19:35:15
|
We can trash the `lock` file, they are dummy file that are only used to avoid concurrent access when the library is run.
You can read the filelock readme and code, it's a very simple single-file library: https://github.com/benediktschmitt/py-filelock
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/623662192/reactions
| 1
| 1
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/624041328
|
https://github.com/huggingface/datasets/pull/50#issuecomment-624041328
|
https://api.github.com/repos/huggingface/datasets/issues/50
| 624,041,328
|
MDEyOklzc3VlQ29tbWVudDYyNDA0MTMyOA==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-05T13:01:57
| 2020-05-05T13:01:57
|
Test failure is not related to change in test file.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/624041328/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/624592209
|
https://github.com/huggingface/datasets/pull/25#issuecomment-624592209
|
https://api.github.com/repos/huggingface/datasets/issues/25
| 624,592,209
|
MDEyOklzc3VlQ29tbWVudDYyNDU5MjIwOQ==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-05-06T11:23:40
| 2020-05-06T11:32:13
|
Ok here is a proposal for a more general API and workflow.
# New `ArrowBasedBuilder`
For all the formats that can be directly and efficiently loaded by Arrow (CSV, JSON, Parquet, Arrow), we don't really want to have to go through a conversion to python and back to Arrow. This new builder has a `_generate_tables` method to yield `Arrow.Tables` instead of single examples.
The tables can be directly casted in Arrow so it's not necessary to supply `Features`, they can be deduced from the `Table` column.
# Central role of the `BuilderConfig` to store all the arguments necessary for the Dataset creation.
`BuilderConfig` provide a few defaults fields `name`, `version`, `description`, `data_files` and `data_dir` which can be used to store values necessary for the creation of the dataset. It can be freely extended to store additional information (see the example for `CsvConfig`).
On the contrary, `DatasetInfo` is designed as an organized and delimited information storage class with predefined fields.
`DatasetInfo` now store two names:
- `builder_name`: Name of the builder script used to create the dataset
- `config_name`: Name of the configuration used to create the dataset.
# Refactoring `load()` arguments and all the chain of processing including the `DownloadManager`
`load()` now accept a selection of arguments which are used to update the `BuilderConfig` and some kwargs which are used to handle the download process.
Supplying a `BuilderConfig` as `config` will override the config provided in the dataset. Supplying a `str` will get the associated config from the dataset. Default is to fetch the first config of the dataset.
Giving additional arguments to `load()` will override the arguments in the `BuilderConfig`.
# CSV script
The `csv.py` script is provided as an example, usage is:
```python
bbc = nlp.load('/Users/thomwolf/Documents/GitHub/datasets/datasets/nlp/csv',
name='bbc',
version="1.0.1",
split='train',
data_files={'train': ['/Users/thomwolf/Documents/GitHub/datasets/datasets/dummy_data/csv/test.csv']},
skip_rows=10,
download_mode='force_redownload')
```
# Checksums
We now don't raise an error if the checksum file is not found.
# `DownloadConfig`
We now have a download configuration class to handle all the specific arguments for file caching like proxies, using only local files or user-agents.
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/624592209/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/624649759
|
https://github.com/huggingface/datasets/pull/37#issuecomment-624649759
|
https://api.github.com/repos/huggingface/datasets/issues/37
| 624,649,759
|
MDEyOklzc3VlQ29tbWVudDYyNDY0OTc1OQ==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-06T13:29:05
| 2020-05-06T13:29:05
|
The testing design was slightly changed as explained in https://github.com/huggingface/nlp/pull/51 .
If creating the dummy folder is too confusing it helps to upload everything else to AWS, then run the test and check the INFO when testing on how to create the dummy folder structure.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/624649759/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625188686
|
https://github.com/huggingface/datasets/pull/55#issuecomment-625188686
|
https://api.github.com/repos/huggingface/datasets/issues/55
| 625,188,686
|
MDEyOklzc3VlQ29tbWVudDYyNTE4ODY4Ng==
|
lhoestq
| 42,851,186
|
MDQ6VXNlcjQyODUxMTg2
|
https://avatars.githubusercontent.com/u/42851186?v=4
|
https://api.github.com/users/lhoestq
|
https://github.com/lhoestq
|
https://api.github.com/users/lhoestq/followers
|
https://api.github.com/users/lhoestq/following{/other_user}
|
https://api.github.com/users/lhoestq/gists{/gist_id}
|
https://api.github.com/users/lhoestq/starred{/owner}{/repo}
|
https://api.github.com/users/lhoestq/subscriptions
|
https://api.github.com/users/lhoestq/orgs
|
https://api.github.com/users/lhoestq/repos
|
https://api.github.com/users/lhoestq/events{/privacy}
|
https://api.github.com/users/lhoestq/received_events
|
User
|
public
| false
| 2020-05-07T11:09:56
| 2020-05-07T11:09:56
|
Right now the changes are a bit hard to read as the one from #25 are also included. You can wait until #25 is merged before looking at the implementation details
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625188686/reactions
| 1
| 1
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625284711
|
https://github.com/huggingface/datasets/pull/55#issuecomment-625284711
|
https://api.github.com/repos/huggingface/datasets/issues/55
| 625,284,711
|
MDEyOklzc3VlQ29tbWVudDYyNTI4NDcxMQ==
|
jplu
| 959,590
|
MDQ6VXNlcjk1OTU5MA==
|
https://avatars.githubusercontent.com/u/959590?v=4
|
https://api.github.com/users/jplu
|
https://github.com/jplu
|
https://api.github.com/users/jplu/followers
|
https://api.github.com/users/jplu/following{/other_user}
|
https://api.github.com/users/jplu/gists{/gist_id}
|
https://api.github.com/users/jplu/starred{/owner}{/repo}
|
https://api.github.com/users/jplu/subscriptions
|
https://api.github.com/users/jplu/orgs
|
https://api.github.com/users/jplu/repos
|
https://api.github.com/users/jplu/events{/privacy}
|
https://api.github.com/users/jplu/received_events
|
User
|
public
| false
| 2020-05-07T14:20:12
| 2020-05-07T14:20:12
|
Nice!! I tested it a bit and works quite well. I will do a my review once the #25 will be merged because there are several overlaps.
At least I can share my thoughts on your **Next** section:
1) I don't think it is a good thing to rely on tfds preprocessed datasets uploaded in their online storage, because they might be updated or deleted at any moment by Google and then possibly break our own processing.
2) Improves the pipeline is always a good direction, but in the meantime we might also share the preprocessed dataset in S3 storage. Which might be another way to see 1), instead of downloading Google preprocessed datasets, using our own ones.
3) Apache Beam can be easily integrated in Spark, so I don't see the need to replace Beam by Spark.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625284711/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625500567
|
https://github.com/huggingface/datasets/pull/25#issuecomment-625500567
|
https://api.github.com/repos/huggingface/datasets/issues/25
| 625,500,567
|
MDEyOklzc3VlQ29tbWVudDYyNTUwMDU2Nw==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-05-07T21:13:02
| 2020-05-07T21:14:44
|
Ok merging this for now.
One general note is that it's a bit hard to handle the `ClassLabel` generally in both `nlp` and `Arrow` since a class label typically need some metadata for the class names. For now, I raise a `NotImplementedError` when an `ArrowBuilder` output a table with a `DictionaryType` is encountered (which could be a simple equivalent for a `ClassLabel` Feature in Arrow tables).
In general and if we need this in the future for some Beam Datasets for instance, I think we should use one of the `metadata` fields in the `Arrow` type or table's schema to store the relation with indices and class names.
So ping me if you meet Beam datasets which uses `ClassLabels` (cc @lhoestq @patrickvonplaten @mariamabarham).
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625500567/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625502323
|
https://github.com/huggingface/datasets/pull/55#issuecomment-625502323
|
https://api.github.com/repos/huggingface/datasets/issues/55
| 625,502,323
|
MDEyOklzc3VlQ29tbWVudDYyNTUwMjMyMw==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-05-07T21:17:12
| 2020-05-07T21:17:12
|
Ok I've merged #25 so you can rebase or merge if you want.
I fully agree with @jplu notes for the "next section".
Don't hesitate to use some credit on Google Dataflow if you think it would be useful to give it a try.
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625502323/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625511928
|
https://github.com/huggingface/datasets/pull/58#issuecomment-625511928
|
https://api.github.com/repos/huggingface/datasets/issues/58
| 625,511,928
|
MDEyOklzc3VlQ29tbWVudDYyNTUxMTkyOA==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-05-07T21:41:27
| 2020-05-07T21:41:27
|
Wait I messed up my branch, let me clean this.
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625511928/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625521252
|
https://github.com/huggingface/datasets/pull/51#issuecomment-625521252
|
https://api.github.com/repos/huggingface/datasets/issues/51
| 625,521,252
|
MDEyOklzc3VlQ29tbWVudDYyNTUyMTI1Mg==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-05-07T22:07:19
| 2020-05-07T22:07:19
|
Awesome!
Let's have this in the doc at the end :-)
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625521252/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625523028
|
https://github.com/huggingface/datasets/pull/59#issuecomment-625523028
|
https://api.github.com/repos/huggingface/datasets/issues/59
| 625,523,028
|
MDEyOklzc3VlQ29tbWVudDYyNTUyMzAyOA==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-07T22:11:53
| 2020-05-07T22:11:53
|
I can fix the tests tomorrow :-)
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625523028/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625702045
|
https://github.com/huggingface/datasets/pull/59#issuecomment-625702045
|
https://api.github.com/repos/huggingface/datasets/issues/59
| 625,702,045
|
MDEyOklzc3VlQ29tbWVudDYyNTcwMjA0NQ==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-08T08:22:07
| 2020-05-08T08:22:07
|
Very weird bug indeed! I think the problem was that when importing `setup_module` we overwrote `pytest's` setup_module function. I think this is the relevant code in pytest: https://github.com/pytest-dev/pytest/blob/9d2eabb397b059b75b746259daeb20ee5588f559/src/_pytest/python.py#L460.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625702045/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625712432
|
https://github.com/huggingface/datasets/pull/59#issuecomment-625712432
|
https://api.github.com/repos/huggingface/datasets/issues/59
| 625,712,432
|
MDEyOklzc3VlQ29tbWVudDYyNTcxMjQzMg==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-08T08:49:27
| 2020-05-08T08:49:27
|
Also PR: #25 introduced some renaming: `DatasetBuilder.builder_config` -> `DatasetBuilder.config` so that we will have to change most of the dataset scripts (Just replace the "builder_config" with "config").
I think the renaming is a good idea and I can do the fix with a bash regex, but will have to re-upload most of the datasets. @thomwolf @mariamabarham
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625712432/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625717837
|
https://github.com/huggingface/datasets/pull/59#issuecomment-625717837
|
https://api.github.com/repos/huggingface/datasets/issues/59
| 625,717,837
|
MDEyOklzc3VlQ29tbWVudDYyNTcxNzgzNw==
|
mariamabarham
| 38,249,783
|
MDQ6VXNlcjM4MjQ5Nzgz
|
https://avatars.githubusercontent.com/u/38249783?v=4
|
https://api.github.com/users/mariamabarham
|
https://github.com/mariamabarham
|
https://api.github.com/users/mariamabarham/followers
|
https://api.github.com/users/mariamabarham/following{/other_user}
|
https://api.github.com/users/mariamabarham/gists{/gist_id}
|
https://api.github.com/users/mariamabarham/starred{/owner}{/repo}
|
https://api.github.com/users/mariamabarham/subscriptions
|
https://api.github.com/users/mariamabarham/orgs
|
https://api.github.com/users/mariamabarham/repos
|
https://api.github.com/users/mariamabarham/events{/privacy}
|
https://api.github.com/users/mariamabarham/received_events
|
User
|
public
| false
| 2020-05-08T09:03:28
| 2020-05-08T09:03:28
|
> Also PR: #25 introduced some renaming: `DatasetBuilder.builder_config` -> `DatasetBuilder.config` so that we will have to change most of the dataset scripts (Just replace the "builder_config" with "config").
>
> I think the renaming is a good idea and I can do the fix with a bash regex, but will have to re-upload most of the datasets. @thomwolf @mariamabarham
I think if it only needs a re-uploading, we can rename it, `DatasetBuilder.config` is easier and sounds better
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625717837/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625730016
|
https://github.com/huggingface/datasets/pull/60#issuecomment-625730016
|
https://api.github.com/repos/huggingface/datasets/issues/60
| 625,730,016
|
MDEyOklzc3VlQ29tbWVudDYyNTczMDAxNg==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-08T09:32:09
| 2020-05-08T09:32:09
|
Awesome!
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625730016/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625734992
|
https://github.com/huggingface/datasets/pull/57#issuecomment-625734992
|
https://api.github.com/repos/huggingface/datasets/issues/57
| 625,734,992
|
MDEyOklzc3VlQ29tbWVudDYyNTczNDk5Mg==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-08T09:45:23
| 2020-05-08T09:45:23
|
I should have read this PR before doing my own: https://github.com/huggingface/nlp/pull/62 :D
will close mine. Looks great :-)
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625734992/reactions
| 1
| 0
| 0
| 1
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625735293
|
https://github.com/huggingface/datasets/pull/57#issuecomment-625735293
|
https://api.github.com/repos/huggingface/datasets/issues/57
| 625,735,293
|
MDEyOklzc3VlQ29tbWVudDYyNTczNTI5Mw==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-08T09:46:13
| 2020-05-08T09:46:13
|
> Awesome, this is really nice!
>
> By the way, we should improve the `cached_path` method of the `transformers` repo similarly, don't you think (@patrickvonplaten in particular).
Yeah, we should do the same in `transformers` I think - will note it down.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625735293/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625738556
|
https://github.com/huggingface/datasets/pull/60#issuecomment-625738556
|
https://api.github.com/repos/huggingface/datasets/issues/60
| 625,738,556
|
MDEyOklzc3VlQ29tbWVudDYyNTczODU1Ng==
|
mariamabarham
| 38,249,783
|
MDQ6VXNlcjM4MjQ5Nzgz
|
https://avatars.githubusercontent.com/u/38249783?v=4
|
https://api.github.com/users/mariamabarham
|
https://github.com/mariamabarham
|
https://api.github.com/users/mariamabarham/followers
|
https://api.github.com/users/mariamabarham/following{/other_user}
|
https://api.github.com/users/mariamabarham/gists{/gist_id}
|
https://api.github.com/users/mariamabarham/starred{/owner}{/repo}
|
https://api.github.com/users/mariamabarham/subscriptions
|
https://api.github.com/users/mariamabarham/orgs
|
https://api.github.com/users/mariamabarham/repos
|
https://api.github.com/users/mariamabarham/events{/privacy}
|
https://api.github.com/users/mariamabarham/received_events
|
User
|
public
| false
| 2020-05-08T09:55:13
| 2020-05-08T09:55:13
|
Also we should convert `tf.io.gfile.exists` into `os.path.exists` , `tf.io.gfile.listdir`into `os.listdir` and `tf.io.gfile.glob` into `glob.glob` (will need to add `import glob`)
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625738556/reactions
| 1
| 1
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625747106
|
https://github.com/huggingface/datasets/pull/60#issuecomment-625747106
|
https://api.github.com/repos/huggingface/datasets/issues/60
| 625,747,106
|
MDEyOklzc3VlQ29tbWVudDYyNTc0NzEwNg==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-08T10:18:44
| 2020-05-08T10:18:44
|
> Also we should convert `tf.io.gfile.exists` into `os.path.exists` , `tf.io.gfile.listdir`into `os.listdir` and `tf.io.gfile.glob` into `glob.glob` (will need to add `import glob`)
We should probably open a new PR about this
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625747106/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625752474
|
https://github.com/huggingface/datasets/pull/60#issuecomment-625752474
|
https://api.github.com/repos/huggingface/datasets/issues/60
| 625,752,474
|
MDEyOklzc3VlQ29tbWVudDYyNTc1MjQ3NA==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-08T10:33:34
| 2020-05-08T10:33:34
|
I think it might be a good idea to both change the supervised keys to a named tuple and also handle the translation features specifically.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625752474/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625753647
|
https://github.com/huggingface/datasets/pull/60#issuecomment-625753647
|
https://api.github.com/repos/huggingface/datasets/issues/60
| 625,753,647
|
MDEyOklzc3VlQ29tbWVudDYyNTc1MzY0Nw==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-08T10:36:56
| 2020-05-08T10:36:56
|
Just noticed that `pyarrow` apparently does not have a `is_boolean` function. Or do I have the wrong `pyarrow` version?
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625753647/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625754153
|
https://github.com/huggingface/datasets/pull/60#issuecomment-625754153
|
https://api.github.com/repos/huggingface/datasets/issues/60
| 625,754,153
|
MDEyOklzc3VlQ29tbWVudDYyNTc1NDE1Mw==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-08T10:38:31
| 2020-05-08T10:38:31
|
Ah, it was a typo `pa.types.is_boolean` is the correct name. Will fix in: https://github.com/huggingface/nlp/pull/59
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625754153/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625756961
|
https://github.com/huggingface/datasets/pull/59#issuecomment-625756961
|
https://api.github.com/repos/huggingface/datasets/issues/59
| 625,756,961
|
MDEyOklzc3VlQ29tbWVudDYyNTc1Njk2MQ==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-08T10:46:45
| 2020-05-08T10:46:45
|
Ok seems to be fine. Most tests work - merging.
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625756961/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625824710
|
https://github.com/huggingface/datasets/pull/37#issuecomment-625824710
|
https://api.github.com/repos/huggingface/datasets/issues/37
| 625,824,710
|
MDEyOklzc3VlQ29tbWVudDYyNTgyNDcxMA==
|
patrickvonplaten
| 23,423,619
|
MDQ6VXNlcjIzNDIzNjE5
|
https://avatars.githubusercontent.com/u/23423619?v=4
|
https://api.github.com/users/patrickvonplaten
|
https://github.com/patrickvonplaten
|
https://api.github.com/users/patrickvonplaten/followers
|
https://api.github.com/users/patrickvonplaten/following{/other_user}
|
https://api.github.com/users/patrickvonplaten/gists{/gist_id}
|
https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}
|
https://api.github.com/users/patrickvonplaten/subscriptions
|
https://api.github.com/users/patrickvonplaten/orgs
|
https://api.github.com/users/patrickvonplaten/repos
|
https://api.github.com/users/patrickvonplaten/events{/privacy}
|
https://api.github.com/users/patrickvonplaten/received_events
|
User
|
public
| false
| 2020-05-08T13:48:23
| 2020-05-08T13:48:23
|
Closing because we can now work on master
|
CONTRIBUTOR
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625824710/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625926487
|
https://github.com/huggingface/datasets/pull/55#issuecomment-625926487
|
https://api.github.com/repos/huggingface/datasets/issues/55
| 625,926,487
|
MDEyOklzc3VlQ29tbWVudDYyNTkyNjQ4Nw==
|
lhoestq
| 42,851,186
|
MDQ6VXNlcjQyODUxMTg2
|
https://avatars.githubusercontent.com/u/42851186?v=4
|
https://api.github.com/users/lhoestq
|
https://github.com/lhoestq
|
https://api.github.com/users/lhoestq/followers
|
https://api.github.com/users/lhoestq/following{/other_user}
|
https://api.github.com/users/lhoestq/gists{/gist_id}
|
https://api.github.com/users/lhoestq/starred{/owner}{/repo}
|
https://api.github.com/users/lhoestq/subscriptions
|
https://api.github.com/users/lhoestq/orgs
|
https://api.github.com/users/lhoestq/repos
|
https://api.github.com/users/lhoestq/events{/privacy}
|
https://api.github.com/users/lhoestq/received_events
|
User
|
public
| false
| 2020-05-08T17:24:53
| 2020-05-08T17:24:53
|
Pr is ready for review !
New minor changes:
- re-added the csv dataset builder (it was on my branch from #25 but disappeared from master)
- move the csv script and the wikipedia script to "under construction" for now
- some renaming in the `nlp-cli test` command
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625926487/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625989063
|
https://github.com/huggingface/datasets/pull/67#issuecomment-625989063
|
https://api.github.com/repos/huggingface/datasets/issues/67
| 625,989,063
|
MDEyOklzc3VlQ29tbWVudDYyNTk4OTA2Mw==
|
thomwolf
| 7,353,373
|
MDQ6VXNlcjczNTMzNzM=
|
https://avatars.githubusercontent.com/u/7353373?v=4
|
https://api.github.com/users/thomwolf
|
https://github.com/thomwolf
|
https://api.github.com/users/thomwolf/followers
|
https://api.github.com/users/thomwolf/following{/other_user}
|
https://api.github.com/users/thomwolf/gists{/gist_id}
|
https://api.github.com/users/thomwolf/starred{/owner}{/repo}
|
https://api.github.com/users/thomwolf/subscriptions
|
https://api.github.com/users/thomwolf/orgs
|
https://api.github.com/users/thomwolf/repos
|
https://api.github.com/users/thomwolf/events{/privacy}
|
https://api.github.com/users/thomwolf/received_events
|
User
|
public
| false
| 2020-05-08T19:50:47
| 2020-05-08T19:50:47
|
Super nice, good job @patrickvonplaten!
|
MEMBER
|
https://api.github.com/repos/huggingface/datasets/issues/comments/625989063/reactions
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| 0
| null |
GitHub Issue Comments – Hugging Face/datasets Repository
Dataset Summary
This dataset contains 4,000 structured GitHub issue comments collected from the huggingface/datasets repository. Each comment includes metadata such as author details, timestamps, reactions and association type. The dataset is ideal for analysing open-source community dynamics, sentiment trends, contributor behaviour and natural language patterns in technical discussions.
Dataset Structure
Data Fields Column Name Description id Unique identifier for the comment body Text content of the comment created_at Timestamp when the comment was created updated_at Timestamp when the comment was last updated author_association Role of the commenter (e.g., MEMBER, CONTRIBUTOR, NONE) user_login GitHub username of the commenter user_id Unique GitHub user ID user_type Type of GitHub account (e.g., User, Bot) user_site_admin Boolean indicating if the user is a GitHub site admin html_url Direct URL to the comment on GitHub issue_url API URL of the issue the comment belongs to reactions_total_count Total number of emoji reactions reactions_+1 to reactions_eyes Individual counts for each reaction type (👍, 👎, ❤️, 🎉, etc.) performed_via_github_app GitHub App used to post the comment (if any) user_* fields Additional metadata about the user (avatar, profile URLs, etc.)
Data Types
- int64: IDs, reaction counts
- object: Text, URLs, usernames
- datetime64[s]: Timestamps
- bool: Admin flag
Source
- Repository: huggingface/datasets
- API Endpoint: https://api.github.com/repos/huggingface/datasets/issues/comments
- Collection Method: API calls (per_page=100, page=1–40)
- License: GitHub content is subject to GitHub Terms of Service
Intended Uses
- NLP Tasks: Sentiment analysis, topic modelling, summarisation
- Community Analytics: Contributor engagement, reaction trends
- Model Training: Fine-tuning on technical dialogue and bug reporting
- Feature Engineering: Text length, emoji usage, time-based features, user roles
Limitations
- Comments are limited to public issues only.
- No issue titles or labels are included.
- performed_via_github_app is always null.
- Reactions may not reflect full emotional tone.
Dataset Creation script
- Data was collected using Python requests library by GitHub REST API:
- url = "https://api.github.com/repos/huggingface/datasets/issues/comments?per_page=100&page={page}"
- headers = {"Authorization": f"token {your_token}"}
- response = requests.get(url, headers=headers)
- Comments were flattened into a tabular format with 39 columns. Timestamps were parsed, and nested fields (e.g., user, reactions) were expanded.
License
- This dataset is released under the Apache 2.0 License, which permits commercial and non-commercial use, distribution, modification and private use, provided that proper attribution is given and a copy of the license is included with any redistribution.
Ethical Considerations
- All data is publicly available via GitHub’s API.
- Usernames and profile links are included; please respect contributor privacy and avoid misuse.
Privacy considerations
- All data was collected from publicly accessible GitHub issue comments via the GitHub REST API.
- Usernames, profile URLs and other metadata are included as part of the original public content.
- No private or sensitive data was collected or included.
Storage and Distribution:
- The dataset is stored and distributed via the Hugging Face Hub.
- Users downloading or hosting the dataset are responsible for ensuring compliance with GitHub’s Terms of Service and applicable data handling policies.
- Downloads last month
- 15