
Add model card
Browse files
README.md
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tags:
|
| 3 |
+
- resnet
|
| 4 |
+
license: apache-2.0
|
| 5 |
+
datasets:
|
| 6 |
+
- imagenet
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# ResNet-50d
|
| 10 |
+
|
| 11 |
+
Pretrained model on [ImageNet](http://www.image-net.org/). The ResNet architecture was introduced in
|
| 12 |
+
[this paper](https://arxiv.org/abs/1512.03385) and is adapted with the ResNet-D trick from
|
| 13 |
+
[this paper](https://arxiv.org/abs/1812.01187)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
## Model description
|
| 17 |
+
|
| 18 |
+
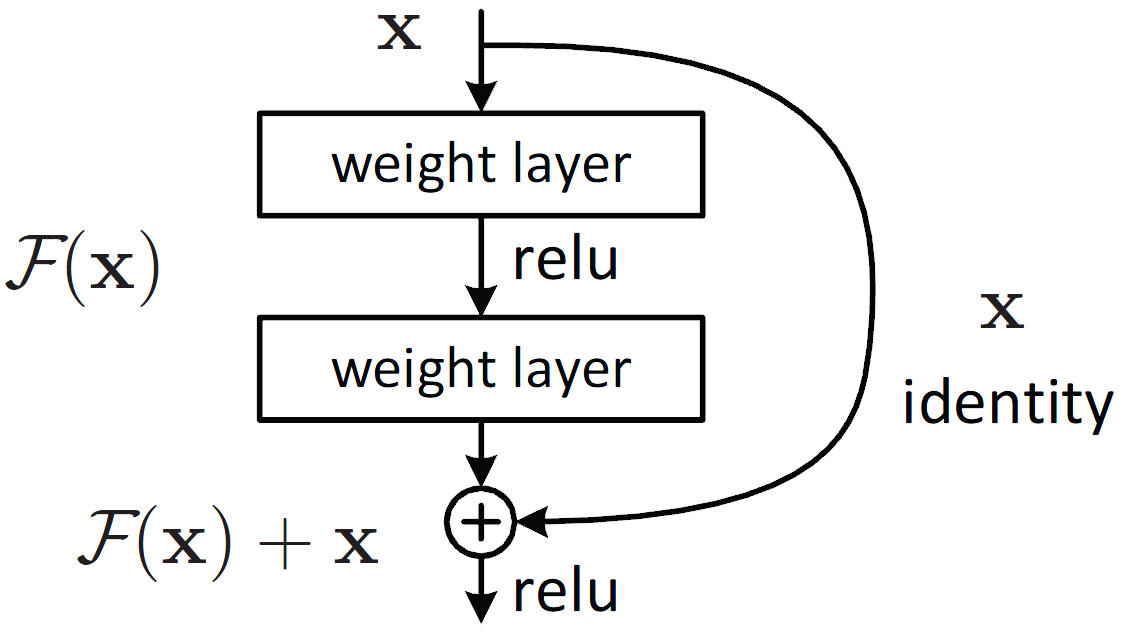
ResNet are deep convolutional neural networks using residual connections. Each layer is composed of two convolutions
|
| 19 |
+
with a ReLU in the middle, but the output is the sum of the input with the output of the convolutional blocks.
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
This way, there is a direct connection from the original inputs to even the deepest layers in the network.
|
| 24 |
+
|
| 25 |
+
## Intended uses & limitations
|
| 26 |
+
|
| 27 |
+
You can use the raw model to classify images along the 1,000 ImageNet labels, but you can also change its head
|
| 28 |
+
to fine-tune it on a downstream task (another classification task with different labels, image segmentation or
|
| 29 |
+
object detection, to name a few).
|
| 30 |
+
|
| 31 |
+
### How to use
|
| 32 |
+
|
| 33 |
+
You can use this model with the usual factory method in `timm`:
|
| 34 |
+
|
| 35 |
+
```python
|
| 36 |
+
import PIL
|
| 37 |
+
import timm
|
| 38 |
+
import torch
|
| 39 |
+
|
| 40 |
+
model = timm.create_model("sgugger/resnet50d")
|
| 41 |
+
img = PIL.Image.open(path_to_an_image)
|
| 42 |
+
img = img.convert("RGB")
|
| 43 |
+
|
| 44 |
+
config = model.default_cfg
|
| 45 |
+
|
| 46 |
+
if isinstance(config["input_size"], tuple):
|
| 47 |
+
img_size = config["input_size"][-2:]
|
| 48 |
+
else:
|
| 49 |
+
img_size = config["input_size"]
|
| 50 |
+
|
| 51 |
+
transform = timm.data.transforms_factory.transforms_imagenet_eval(
|
| 52 |
+
img_size=img_size,
|
| 53 |
+
interpolation=config["interpolation"],
|
| 54 |
+
mean=config["mean"],
|
| 55 |
+
std=config["std"],
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
input_tensor = transform(cat_img)
|
| 59 |
+
input_tensor = input_tensor.unsqueeze(0)
|
| 60 |
+
# ^ batch size = 1
|
| 61 |
+
with torch.no_grad():
|
| 62 |
+
output = model(input_tensor)
|
| 63 |
+
|
| 64 |
+
probs = output.squeeze(0).softmax(dim=0)
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
### Limitations and bias
|
| 68 |
+
|
| 69 |
+
The training images in the dataset are usually photos clearly representing one of the 1,000 labels. The model will
|
| 70 |
+
probably not generalize well on drawings or images containing multiple objects with different labels.
|
| 71 |
+
|
| 72 |
+
The training images in the dataset come mostly from the US (45.4%) and Great Britain (7.6%). As such the model or
|
| 73 |
+
models created by fine-tuning this model will work better on images picturing scenes from these countries (see
|
| 74 |
+
[this paper](https://arxiv.org/abs/1906.02659) for examples).
|
| 75 |
+
|
| 76 |
+
More generally, [recent research](https://arxiv.org/abs/2010.15052) has shown that even models trained in an
|
| 77 |
+
unsupervised fashion on ImageNet (i.e. without using the labels) will pick up racial and gender bias represented in
|
| 78 |
+
the training images.
|
| 79 |
+
|
| 80 |
+
## Training data
|
| 81 |
+
|
| 82 |
+
This model was pretrained on [ImageNet](http://www.image-net.org/), a dataset consisting of 14 millions of
|
| 83 |
+
hand-annotated images with 1,000 categories.
|
| 84 |
+
|
| 85 |
+
## Training procedure
|
| 86 |
+
|
| 87 |
+
### Preprocessing
|
| 88 |
+
|
| 89 |
+
The images are resized using bicubic interpolation to 224x224 and normalized with the usual ImageNet statistics.
|
| 90 |
+
|
| 91 |
+
## Evaluation results
|
| 92 |
+
|
| 93 |
+
This model has a top1-accuracy of 80.53% and a top-5 accuracy of 95.16% in the evaluation set of ImageNet
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
### BibTeX entry and citation info
|
| 97 |
+
|
| 98 |
+
```bibtex
|
| 99 |
+
@article{DBLP:journals/corr/HeZRS15,
|
| 100 |
+
author = {Kaiming He and
|
| 101 |
+
Xiangyu Zhang and
|
| 102 |
+
Shaoqing Ren and
|
| 103 |
+
Jian Sun},
|
| 104 |
+
title = {Deep Residual Learning for Image Recognition},
|
| 105 |
+
journal = {CoRR},
|
| 106 |
+
volume = {abs/1512.03385},
|
| 107 |
+
year = {2015},
|
| 108 |
+
url = {http://arxiv.org/abs/1512.03385},
|
| 109 |
+
archivePrefix = {arXiv},
|
| 110 |
+
eprint = {1512.03385},
|
| 111 |
+
timestamp = {Wed, 17 Apr 2019 17:23:45 +0200},
|
| 112 |
+
biburl = {https://dblp.org/rec/journals/corr/HeZRS15.bib},
|
| 113 |
+
bibsource = {dblp computer science bibliography, https://dblp.org}
|
| 114 |
+
}
|
| 115 |
+
```
|